




1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
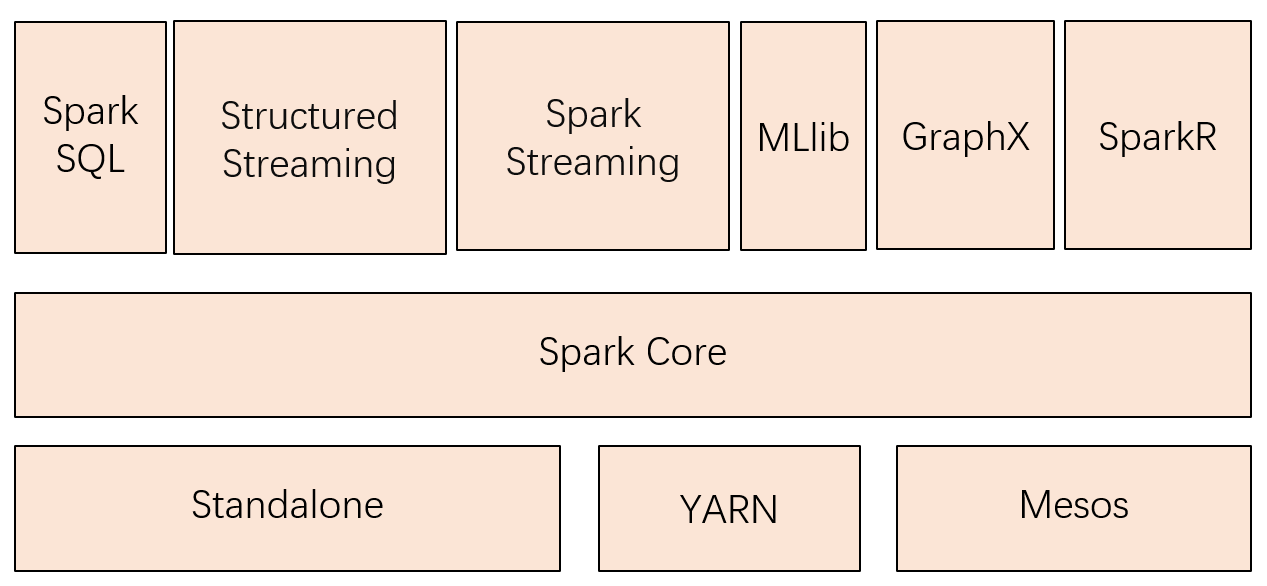
1)SparkCore:类似于MR的分布式内存计算框架,最大的特点是将中间计算结果直接放在内存中,提升计算性能。自带了Standalone模式的资源管理框架,同时,也支持YARN、MESOS的资源管理系统。FI集成的是Spark On Yarn的模式。
2)SparkSQL:一个用于处理结构化数据的Spark组件,作为Apache Spark大数据框架的一部分,主要用于结构化数据处理和对数据执行类SQL查询。通过Spark SQL,可以针对不同数据格式(如:JSON,Parquet, ORC等)和数据源执行ETL操作(如:HDFS、数据库等),完成特定的查询操作。
3)SparkStreaming:微批处理的流处理引擎,将流数据分片以后用SparkCore的计算引擎中进行处理。相对于Storm,实时性稍差,优势体现在吞吐量上。
4)Mllib和GraphX:主要一些算法库。
5)FusionInsight Spark:默认运行在YARN集群之上。
6)Structured Streaming:2.0版本之后的spark独有。知道自己的不足,增加了自己的产品。
2.请详细阐述Spark的几个主要概念及相互关系:
Master,Worker;RDD,DAG;Application,job,stage,task;driver,executor,Cluster ManagerDAGScheduler, TaskScheduler.
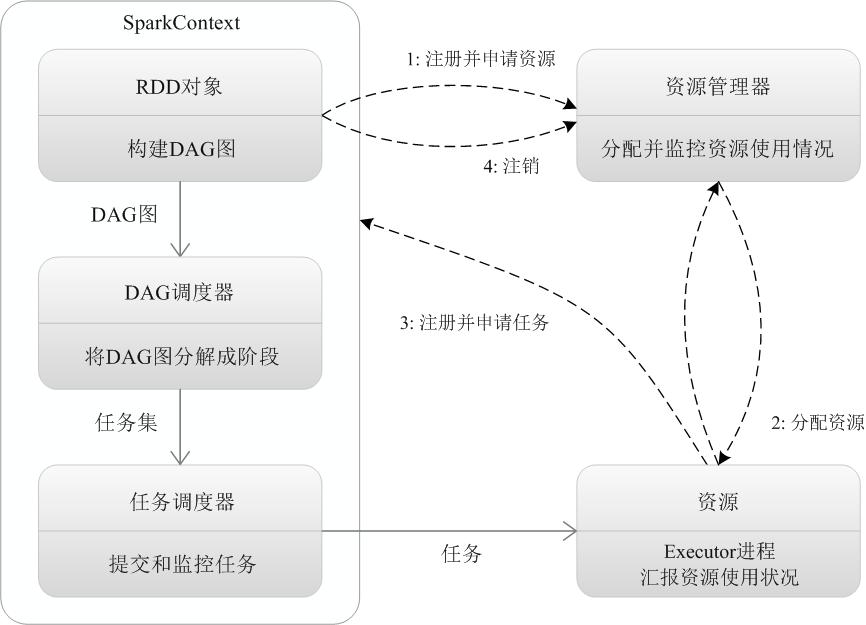
1)Master
主要是控制、管理和监督整个spark集群
2)Worker
从节点,负责控制计算节点,启动Executor或者Driver。在YARN模式中为NodeManager,负责计算节点的控制。
3)RDD
Spark的基础计算单元,一组RDD可形成执行的有向无环图RDD Graph。
4)DAG
DAG 是一个应用被切分为任务之后的执行的相关处理流程,主要是用来控制任务的执行顺序和调用的数据,它是一个有向无环图。
5)Application
用户编写的spark应用程序,由一个或者多个job组成,提交到spark之后,spark为application分派资源,将程序转换并执行。
6)Job
包含多个Task组成的并行计算,是由Action行为触发的
7)Stage
一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。至于stage是怎么切分的,首选得知道spark论文中提到的narrow dependency(窄依赖)和wide dependency(宽依赖)的概念。
8)Task
是类的实例 ,有属性(从哪里读取数据/读取的是哪个切片的数据) ,有方法(如何计算/即数据的计算分析逻辑) ;
9)Driver
负责应用的业务逻辑和运行规划(DAG—有向无环图)。
10)Executor
由若干core组成,每个Executor的每个core一次只能执行一个Task。
11)Cluster Manager
集群上获取资源的外部服务,比如Standalone(由Master负责资源的分配)和Yarn(由ResourceManager负责资源的分配)DAGScheduler
根据作业(task)构建基于Stage的DAG,并提交Stage给TaskScheduler。
12)TaskScheduler
将任务(task)分发给Executor执行。
相互关系
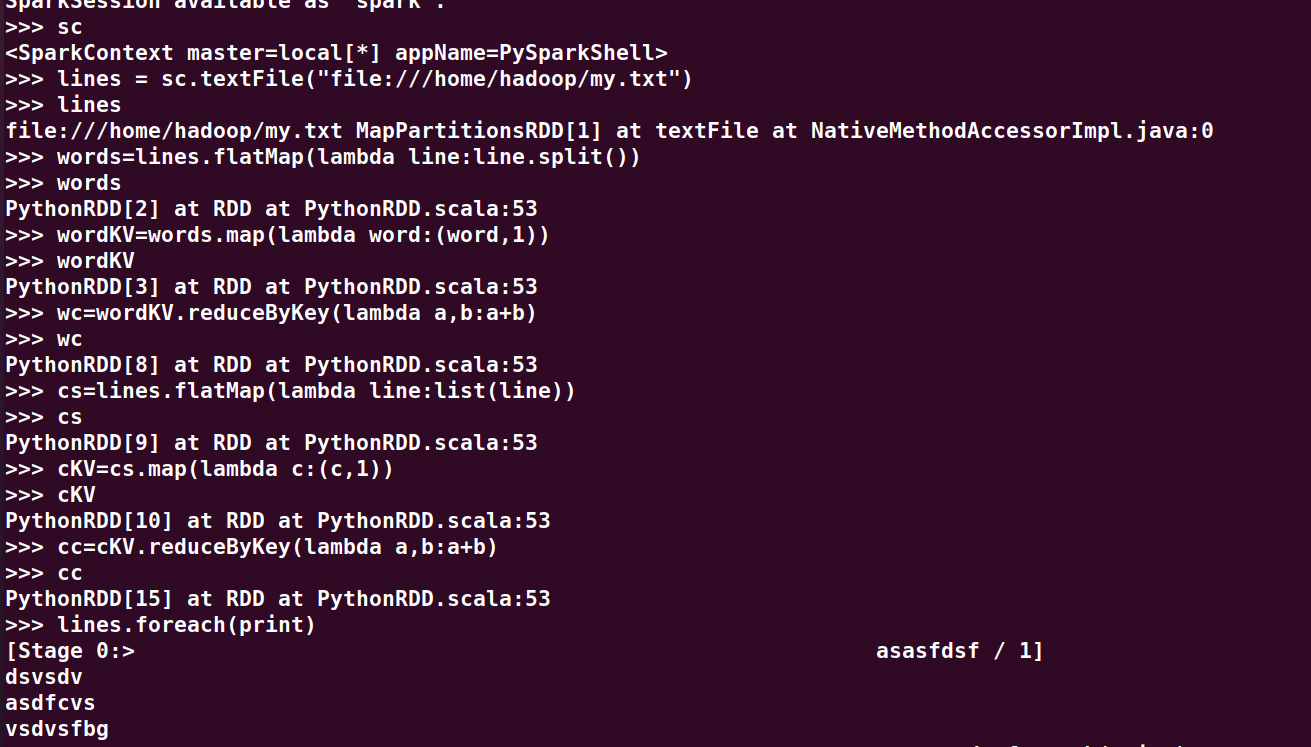
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。

sc
lines = sc.textFile("file:///home/hadoop/my.txt")
lines
words=lines.flatMap(lambda line:line.split())
words
wordKV=words.map(lambda word:(word,1))
wordKV
wc=wordKV.reduceByKey(lambda a,b:a+b)
wc
cs=lines.flatMap(lambda line:list(line))
cs
cKV=cs.map(lambda c:(c,1))
cKV
cc=cKV.reduceByKey(lambda a,b:a+b)
cc
lines.foreach(print)
wordKV.foreach(print)
cs.foreach(print)
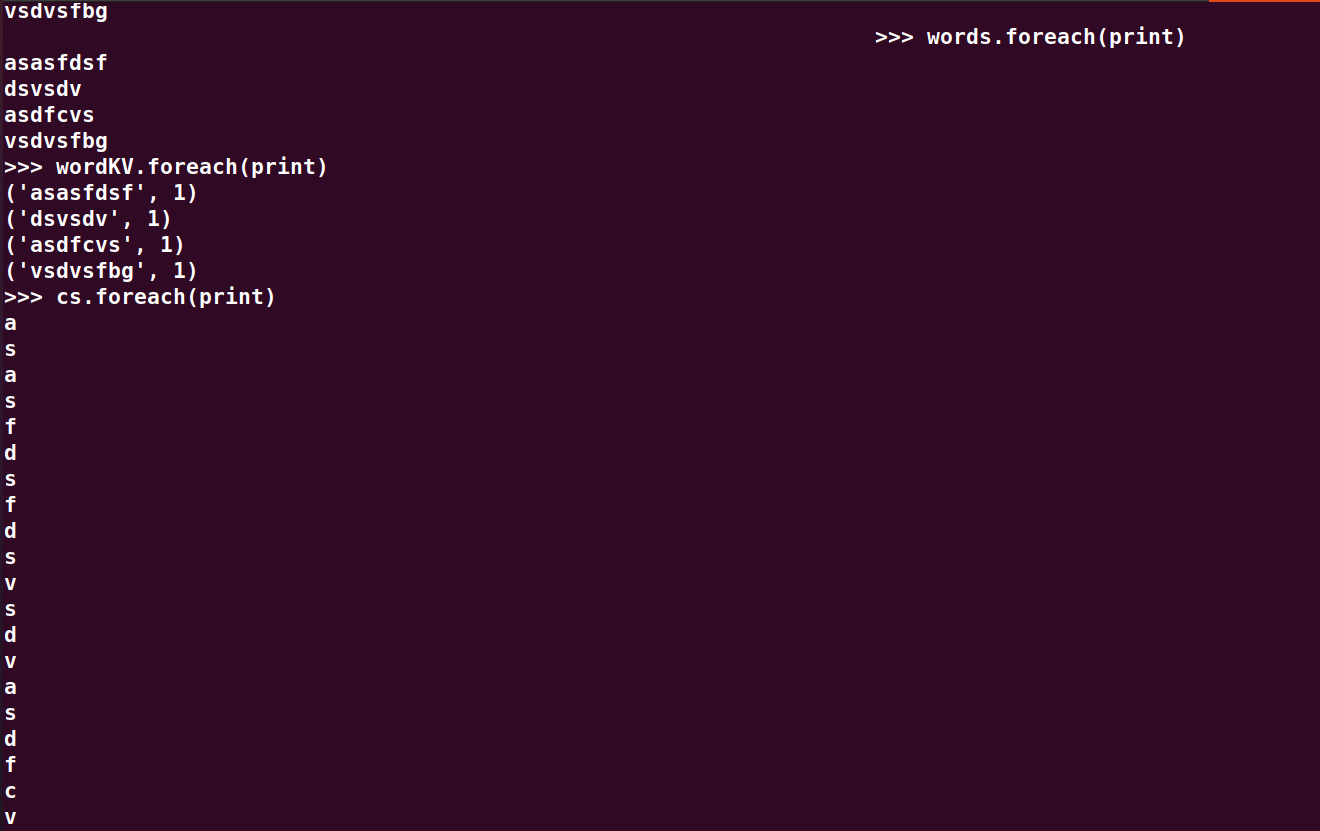
cKV.foreach(print)

wc.foreach(print)

wc.foreach(print)
RDD转换关系图



 浙公网安备 33010602011771号
浙公网安备 33010602011771号