




1、列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
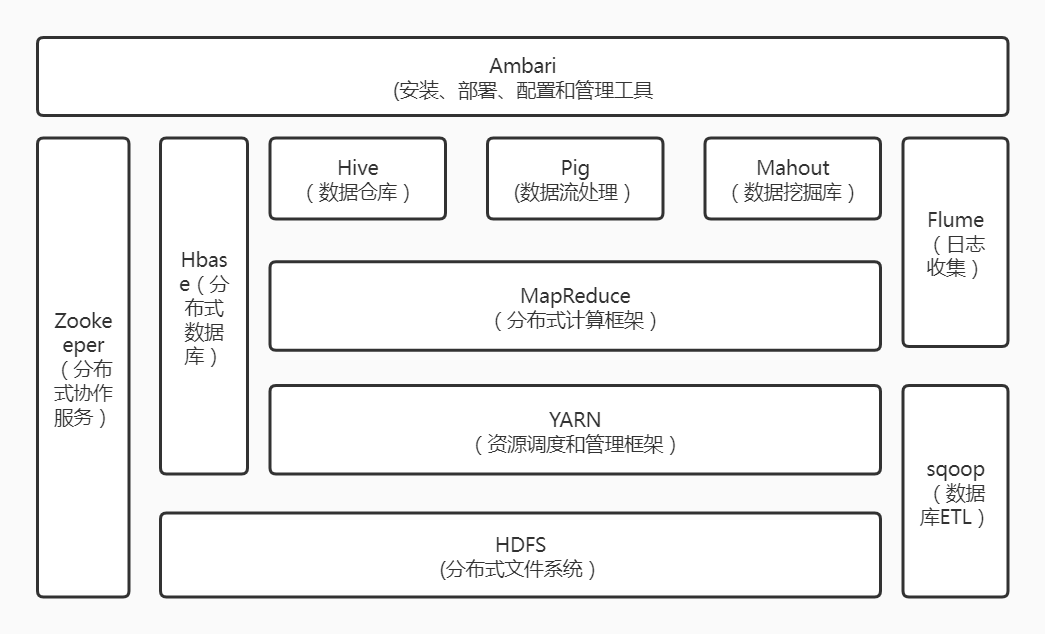
一、HDFS分布式文件系统
Hadoop分布式文件系统HDFS是针对谷歌分布式文件系统的开源实现,它是Hadoop两大核心组成部分之一,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。
HDFS具有很好的容错能力,并且兼容廉价的硬件设备,因此,可以以较低的成本利用现有机器实现大流量和大数据量的读写。
HDFS采用了主从结构模型,一个HDFS集群包括一个名称节点和若干个数据节点。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
二、MapReduce
MapReduce 是一种分布式并行编程模型,用于大规模数据集的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度抽象到两个函数:Map和Reduce。MapReduce极大方便了分布式编程工作,编程人员在不会分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式系统上,完成海量数据集的计算。
MapReduce框架会为每个Map任务输入一个数据子集,Map任务生成的结果会继续作为Reduce任务的输入,最终由Reduce任务输出最后结果,并写入分布式文件系统。
三、YARN
YARN 是负责集群资源调度管理的组件。YARN 的目标就是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架。
通过这种方式,可以实现一个集群上的不同应用负载混搭,有效提高了集群的利用率,同时,不同计算框架可以共享底层存储,在一个集群上集成多个数据集,使用多个计算框架来访问这些数据集,从而避免了数据集跨集群移动,最后,这种部署方式也大大降低了企业运维成本。
四、HBase
HBase 是针对谷歌 BigTable 的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
HBase可以支持超大规模数据存储,它可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行元素和数百万列元素组成的数据表
HBase利用MapReduce来处理HBase中的海量数据,实现高性能计算;利用 Zookeeper 作为协同服务,实现稳定服务和失败恢复;使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力,当然,HBase也可以在单机模式下使用,直接使用本地文件系统而不用 HDFS 作为底层数据存储方式,不过,为了提高数据可靠性和系统的健壮性,发挥HBase处理大量数据等功能,一般都使用HDFS作为HBase的底层数据存储方式。此外,为了方便在HBase上进行数据处理,Sqoop为HBase提供了高效、便捷的RDBMS数据导入功能,Pig和Hive为HBase提供了高层语言支持。
五、Hive
Hive是一个基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。
Hive的学习门槛比较低,因为它提供了类似于关系数据库SQL语言的查询语言——HiveQL,可以通过HiveQL语句快速实现简单的MapReduce统计,Hive自身可以自动将HiveQL语句快速转换成MapReduce任务进行运行,而不必开发专门的MapReduce应用程序,因而十分适合数据仓库的统计分析。
六、Flume
Flume 是 Cloudera 公司开发的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统。
Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方的能力。
七、Sqoop
Sqoop是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。
通过Sqoop,可以方便地将数据从MySQL、Oracle、PostgreSQL等关系数据库中导入Hadoop(比如导入到HDFS、HBase或Hive中),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据
2、对比Hadoop与Spark的优缺点
(1)Spark对标于Hadoop中的计算模块MR,但是速度和效率比MR要快得多;
(2)Spark没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作,它只是一个计算分析框架,专门用来对分布式存储的数据进行计算处理,它本身并不能存储数据;
(3)Spark可以使用Hadoop的HDFS或者其他云数据平台进行数据存储,但是一般使用HDFS;
(4)Spark可以使用基于HDFS的HBase数据库,也可以使用HDFS的数据文件,还可以通过jdbc连接使用Mysql数据库数据;Spark可以对数据库数据进行修改删除,而HDFS只能对数据进行追加和全表删除;
(5)Spark处理数据的设计模式与MR不一样,Hadoop是从HDFS读取数据,通过MR将中间结果写入HDFS;然后再重新从HDFS读取数据进行MR,再刷写到HDFS,这个过程涉及多次落盘操作,多次磁盘IO,效率并不高;而Spark的设计模式是读取集群中的数据后,在内存中存储和运算,直到全部运算完毕后,再存储到集群中;
(6)Spark中通过DAG图可以实现良好的容错。
3、如何实现Hadoop与Spark的统一部署?
由于Hadoop生态系统中的一些组件所实现的功能目前还无法有Spark取代,Spark可运行在YURN上,与Hadoop统一部署即“Spark on YARN”,不同的计算框架统一运行在YARN,分布式存储在HDFS。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号