
python exp4 jieba+wordcloud
20175307 2019-2020-2 《Python程序设计》实验四Python综合实践
课程:《Python程序设计》
班级: 1753
姓名: 高士淳
学号:20175307
实验教师:王志强
实验日期:2020年6月1日
必修/选修: 公选课
1.实验内容
本实验的内容为对文章提取频率最高的词语,并制作一张词云。
2. 实验过程及结果
先通过jieba完成对中文文章词语的提取,再通过wrodcloud完成制作。
3.预备知识
1.jieba
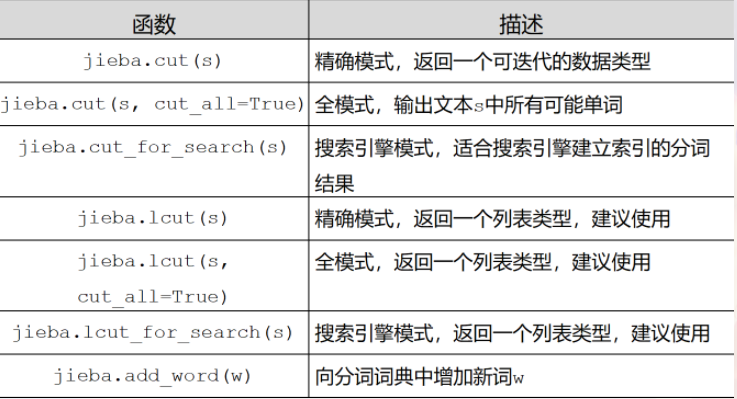
2.wordcloud
- 首先配置词云对象参数
| 参数 | 描述 |
|---|---|
| font_path | 字体路径 |
| width | 输出的画布宽度,默认为400像素 |
| height | 输出的画布高度,默认为200像素 |
| mask | 背景图片 |
| min_font_size | 显示的最小的字体大小 |
| max_font_size | 显示的最大的字体大小 |
| max_words | 要显示的词的最大个数 |
| background_color | 背景颜色 |
- generate_from_frequencies()为通过词频生成词云,传入参数为字典
![]()

4. 实验过程
- 库引用
import jieba
import numpy as np
from PIL import Image
from wordcloud import WordCloud, ImageColorGenerator
- 通过
jieba对文章内容统计词频
txt = open("文章名称.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
for word in words:
if len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1
items = list(counts.items()) # 将键值对转换成列表
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
dic = dict(items)
得到一个包含词语和次数的字典dic
- 配置、生成词云,背景图片通过numpy处理
image = Image.open('D:\\python2020作业\\EXP4\\china.jpg') # 作为背景轮廓图
graph = np.array(image)
wc = WordCloud(font_path='C:/Windows/Fonts/simsun.ttc', background_color='white', max_words=22, mask=graph)
wc.generate_from_frequencies(dic) # 根据给定词频生成词云
image_color = ImageColorGenerator(graph)
wc.to_file('文章名称.png') # 图片命名
- 我对十九大和十八的报告进行了词频的统计,并制作了词云
十八大:
![]()

十九大:

感想
哎呀,python还是一如既往的简单实用啊,但是没时间研究一下源码,还是挺遗憾的。
posted on 2020-06-13 10:16 20175307GSC 阅读(122) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号