
用户分成中关于用户关系的数据存储实现
业务场景描述:
每个用户可以通过用户加入app的方式获得被邀请用户获取收益的 10% ,被邀请用户通过填写邀请用户的邀请码进行绑定。
那么邀请者和被邀请者之间的关系需要存储起来,具体的实现方法有多种,最终选择了 路径枚举的方案。
方案选择:
1. 自引用法(基础父子关系)
- 自引用本身:每个节点都有
parent_id指向父节点,构成最基本的树形关系。 - 优点:简单直观,适合增删改操作,不需要额外的字段或表。
- 缺点:多层级查询时性能下降,所有查询相关的业务需求都需要通过复杂sql实现。
2. 嵌套集方法(Nested Sets)+ 自引用
- 自引用基础:在存储父子关系的同时,为每个节点添加
lft和rgt边界字段,使得子树查询无需递归。 - 优点:子树查询性能极高,通过
lft和rgt一次性获取整棵子树。 - 缺点:更新复杂,每次增删节点都需要重新计算边界值。而且不符合业务场景1个用户会有多个下级的用户。
- 自引用的作用:自引用提供了树结构的基本框架,而嵌套集边界优化了查询,特别是针对读取频繁的情况。
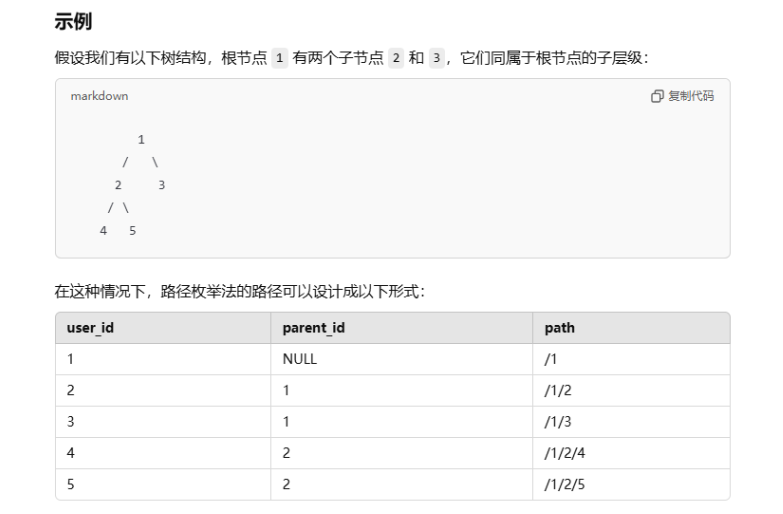
3. 路径枚举法(Path Enumeration)+ 自引用 (选用)
- 自引用基础:使用
parent_id建立父子关系,同时每个节点存储路径path,例如/1/3/7。 - 优点:可以快速查询祖先路径和完整子树。
- 缺点:插入和更新需要同步更新
path,复杂度较高。 - 自引用的作用:自引用简化了基本层级关系,而
path则提供了快速获取路径的能力。
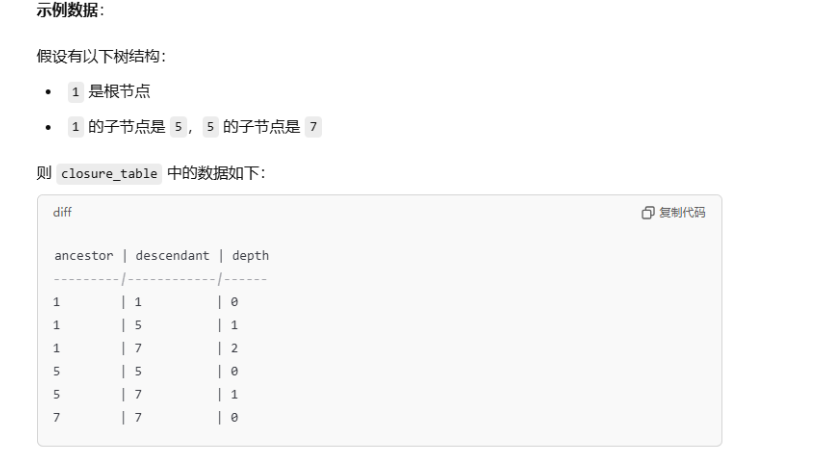
4. 闭包表(Closure Table)+ 自引用
- 自引用基础:父子关系表上增加一张闭包表,用于记录每个节点与所有祖先及后代的关系。
- 优点:查询祖先或后代时性能最高,直接通过闭包表查询关系。
- 缺点:插入和更新操作较复杂,因为每次变动需要更新闭包表的多条记录。相对于路径枚举法没那么直观,数据维护相对多一点。基本上等同于路径枚举法。
- 自引用的作用:自引用是树结构的基础,而闭包表进一步扩展了层级查询能力,避免了递归查询。
路径枚举数据存储情况:
闭包表数据存储情况:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号