2019秋招复习笔记--实习项目经验总结
自己做的几个小项目
以下需要总结整理细节部分
1. 车道线检测
2. 视频解压缩编码、传输等
3. 一个用python做的路径寻址application
关于三维模型搜索引擎项目相关度排序算法是怎么做的:
以文字搜模型:
基于Lucene文本搜索引擎,查找最匹配的;
以图片搜模型:
计算图片特征,对图片特征计算HashCode, 搜索的时候匹配HashCode;
以模型搜模型:
计算模型的特征得到n维特征矩阵, 对特征矩阵计算HashCode, 搜索的时候匹配HashCode;
去重和检测url有效性是怎么做的:
对外网数据去重:
一开始直接使用条件逐个字段比较判断是否重复;
后来对关键字段连接建立联合哈希值保存,用这个哈希值去重;
后来想到其实外网的url是唯一的,直接对url建立哈希值来去重;后来设想直接用url哈希之后作为主键保存,建立聚集索引;但是数据量上去了之后速度明显下降;
现在可以使用的解决方法:
对URL 使用布隆过滤器
有效性检测比较简单:
使用java.net 下的类来实现,主要用到了 URL和HttpURLConnection :
刚开始使用openStream()方法,这样使用倒是可以,但是速度慢;
最后使用了getResponseCode()方法,可以得到请求的响应状态,该方法返回一个 int 分别是 200 and 404 如无法从响应中识别任何代码则返回 -1, 如果对该url发起的5次请求都没有应答则认为链接失效;
你的项目用了哪些技术?
Lucene, Solr
MySQL,
Redis,
Java多线程
遇到过什么问题?你是怎么解决的?
去重的过程经历了多次迭代:
刚开始直接对记录逐个字段比较判断是否重复 ——>然后对关键字段建立HashCode作为标识,对比该Hash字段——>再是对外网URL建立HashCode对比;
有什么可以改进的地方?
可以对URL使用布隆过滤器做去重;(位图+多个哈希函数)
使用缓存数据库来提高并发访问;(缓存穿透(查询一个数据库一定不存在的数据),缓存击穿(一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存),缓存雪崩(缓存集中过期失效))
使用Elesticsearch来替代Solr(Elasticsearch是分布式的, 不需要其他组件,分发是实时的;solr需要结合依赖其他分布式组件来实现分布式);
链路负载导出功能
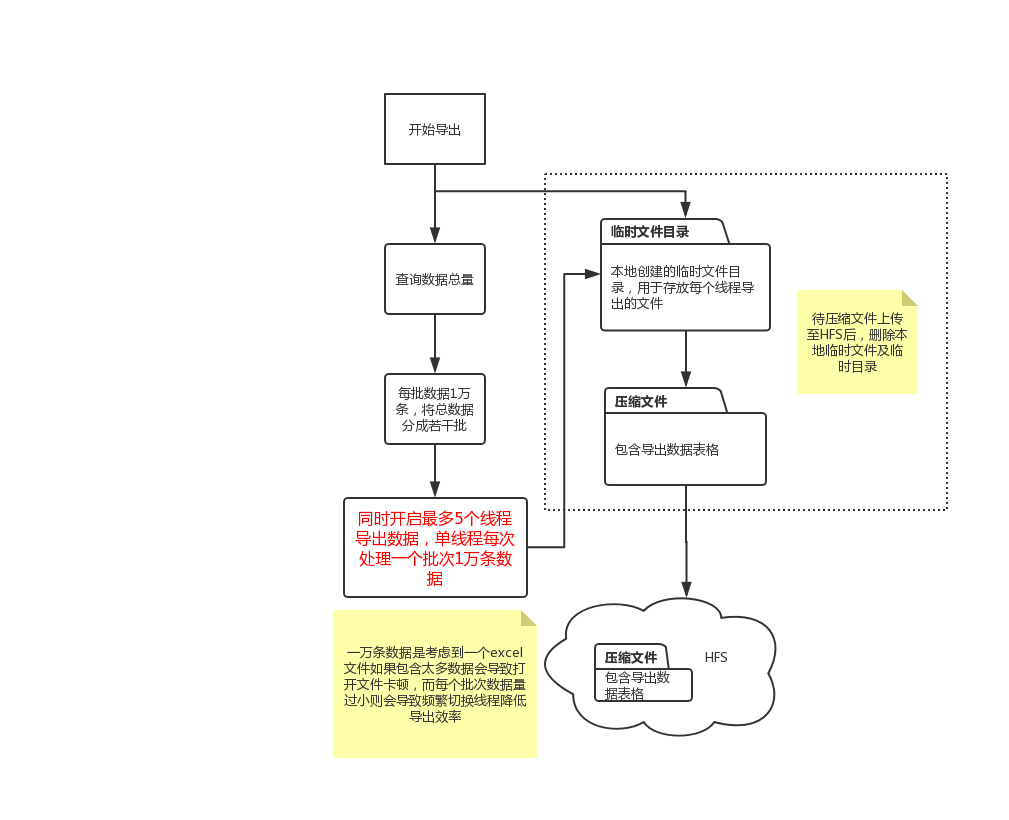
流程图:
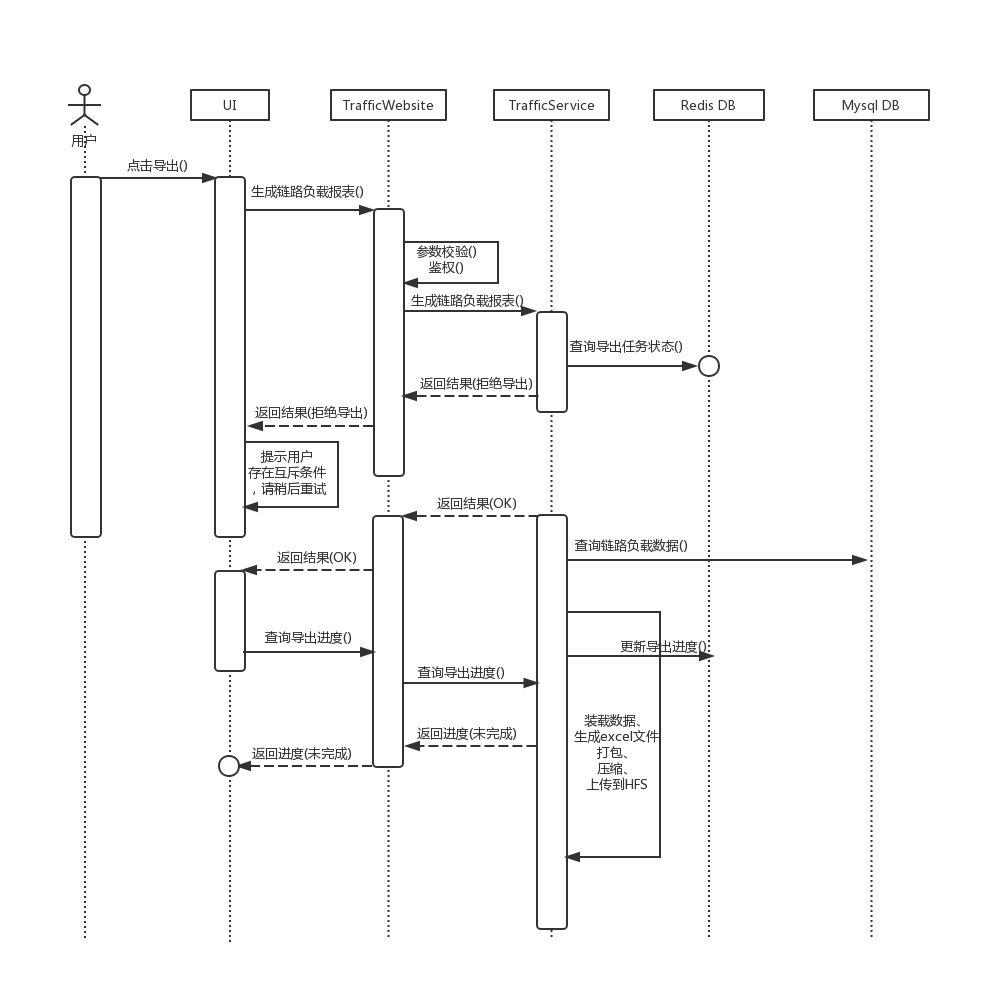
时序图1
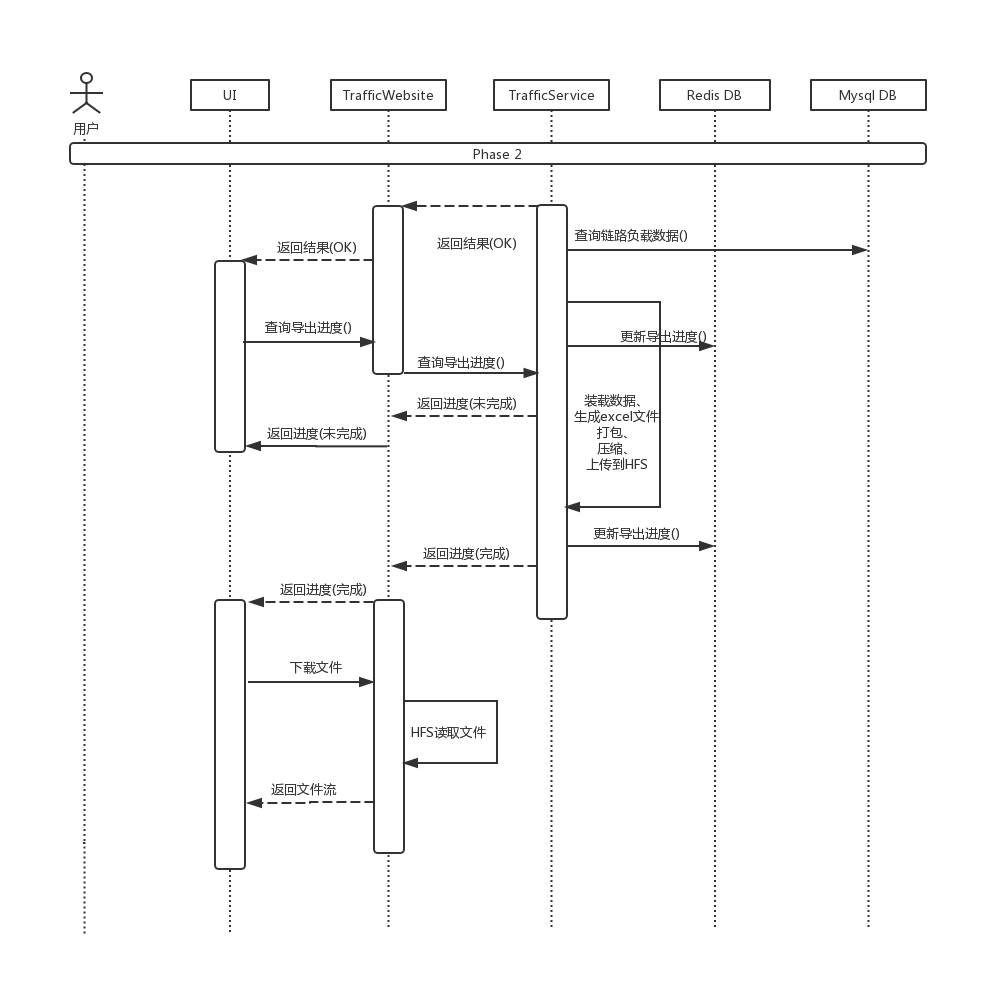
接上面时序图
遇到的三个问题:
1. zip文件下载后不能打开,且文件大小与HFS上的文件大小不一致(比实际文件要大)
1.怀疑文件传输流的代码有误,每次往客户端提交数据的时候提交的时缓冲区长度而不是真实写入数据的长度,这样在文件传输的末尾阶段会多传很多个无效文件位,导致文件大小变大且文件损坏。
走读传输代码,发现不是这个原因
2. 在和同事一起排查的时候,发现没有将下载文件的链接加入到服务器的输入输入编码例外中去。常用的输入输出编码方式时base64, 作用是将一些不可见的字符(如回车、制表符等)编码乘可见字符,提供纠错功能,减少数据传输错误。一般服务器对客户端的文本响应要通过输入输出编码。但是文件传输的时候是以二进制进行传输的,只有0,1不存在不可见字符,所以无需输入输出编码,一般文件较大的情况下作编码的效率也会降低。且只在服务端对其编码而不告知客户端的解码的话,客户端收到的文件会出错。
解决方式,将下载链接配置到web.xml的输入输出编码例外(一个filter过滤器)解决了问题。
2. 文件传输部分地代码复用了之前某个下载的模块地代码,在后台查看日志的时候发现response未提交异常。
说明: 复用的代码逻辑中对ServletResponse的提交状态做了判断,代码的逻辑是运行到代码的最后, 如果response的isCommitted()状态如果是false,则将此异常记录到日志,错误的等级是erro。日志显示每次下载文件的时候都会触发此异常。
经过查找资料,知道:
- 每个response的默认缓冲区大小是8KB,如果缓冲区满,则servlet会自动提交, 并将isCommited状态设置为false;
在测试功能的时候,由于链路负载数据不多(只有不到50条数据),因此生成的链路负载报表只有7KB左右。因此在服务器向客户端提交数据的时候,报表的大小不足以触发缓冲区满而自动提交的条件。因此isCommited状态时false, 进而每次下载该数据的时候日志里都会打上response未提交异常。
备份测试数据库,然后编写数据库脚本循环插入一万条相同的链路负载数据,扩大测试数据大小。在此条件下,日志中的response未提交异常消失。说明正是这个原因导致了日志记录的异常。
处理;
进一步查看Servlet 说明文档, 发现文档中有如下说明;
ServletResponse在如下三个条件下会提交缓冲区:
1. 服务器显示调用commit函数,会将response的isCommited状态设为true;
2. 缓冲区已满的时候, 会将response的isCommited状态设为true并将缓冲区数据刷向客户端。此后剩余的数据操作均使用当前的isCommited状态,也就是说,如果还有剩余数据,则继续填入缓冲区,但不会再对isCommited状态作任何改变。
3. 会话的最后response将要关闭的时候,tomcat会帮我们将缓冲区剩余的数据全部刷到客户端。这个刷数据的过程中如果发现缓冲区的数据未提交,会首先提交数据设置isCommited为true然后再将数据刷到客户端。
综上所述,其实我们没有必要人为的通过查看resposne的isCommited状态来判断服务端的数据是否已经向客户端提交,进而判断数据是不是全部传输到客户端。因为在response会话关闭之前,TomCat会自动提交缓冲区数据。这种方式并不能正确的检测出数据是否已经传到客户端。
解决方式,删掉此处检测response isCommited的逻辑,发现下载异常消失并且下载功能正常使用。
3. 使用lombok包简化java bean对象代码(lombok包可以隐藏代码中的getter setter函数),导致了某个对象在序列化的时候名称不正确。
经检查,发现某个类中的一个布尔类型的成员命名位isFinished, 而在序列化之后存到redis中该成员的名字变成了finished。名称的改变导致后续的代码逻辑都找不到反序列化的结果。
原因:
lombok可以隐藏java bean中的getter setter代码, 但该代码依然存在。依赖框架生成的getter、 setter代码函数命名的逻辑是去掉成员变量开头的is\get\set等单词,用剩下的部分和get、set组合成为getter、setter函数的名称。在序列化的时候,框架也会依赖于getter、setter函数名称(去掉get、set)来生成相应的序列化结果,这样在这个过程中就会丢失原有变量isFinished的is,变成了finish。
解决方法:
1. 显示设置getter、setter方法,写成getIsFinshed和setIsFinised。
2. isFinished作为java bean的成员变量其命名时不规范的,将这个成员变量改为finished.
项目中时怎么使用redis的
如流程图所示,主要作为缓存来使用。使用Redis记录文件生成的进度、文件生成的状态、以及文件生成的路径。website层通过查询redis可以获得service层文件生成的进度,service层通过redis向website层传达自己文件生成的进度信息,从而实现website层和service层的解耦,提高模块的可扩展能力。比如,如果要新增加一个互斥条件(比如正在解析或者采集负载数据的时候不能导出文件的状态),website层和service层可以各自针对这个在redis新增的状态作相应的处理即可。另外,此处应用redis作缓存还考虑到多线程的情况,如果多个客户端同时请求生成文件,则服务器只需要向redis 写入文件导出状态,各个客户端各自分别去redis上读取文件生成的进度,而不需要service层一一的去相应。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号