上面的部分 答案 我测试过,遇到几万条数据,这个函数就会显得很慢。
我推荐 我自己使用这2种方法:速度是目前 最快了。
<img src="https://picx.zhimg.com/50/v2-2f72afead6ebb45766f21ef71937e994_720w.jpg?source=2c26e567" data-caption="" data-size="normal" data-rawwidth="982" data-rawheight="505" data-original-token="v2-94d4181753c2c02e73260362be98e7e0" data-default-watermark-src="https://picx.zhimg.com/50/v2-1acb1983e9c7b13923514367d9ac53a5_720w.jpg?source=2c26e567" class="origin_image zh-lightbox-thumb" width="982" data-original="https://picx.zhimg.com/v2-2f72afead6ebb45766f21ef71937e994_r.jpg?source=2c26e567"/>
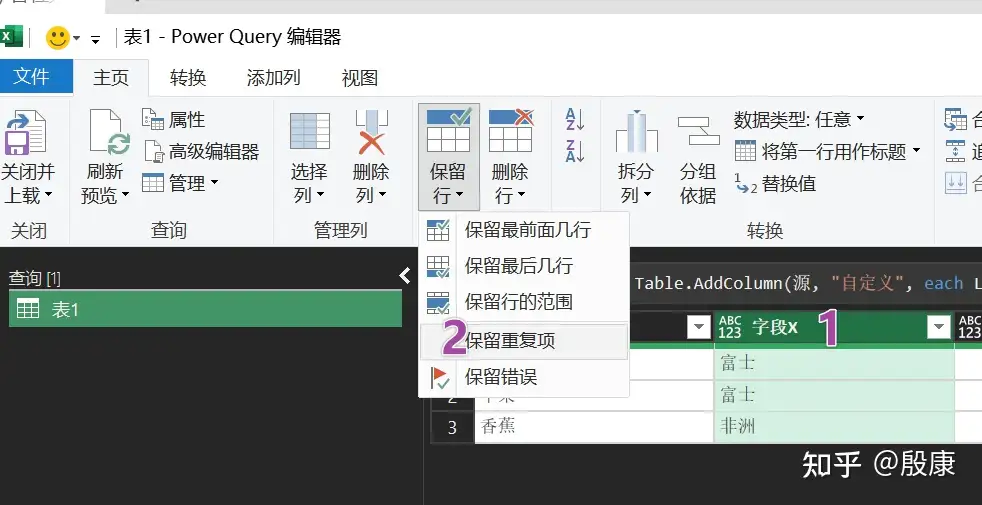
这样基本上就是可以筛选重复值 在2以上的。里面的公式还可以调整数字出现几次的可以保留下来。
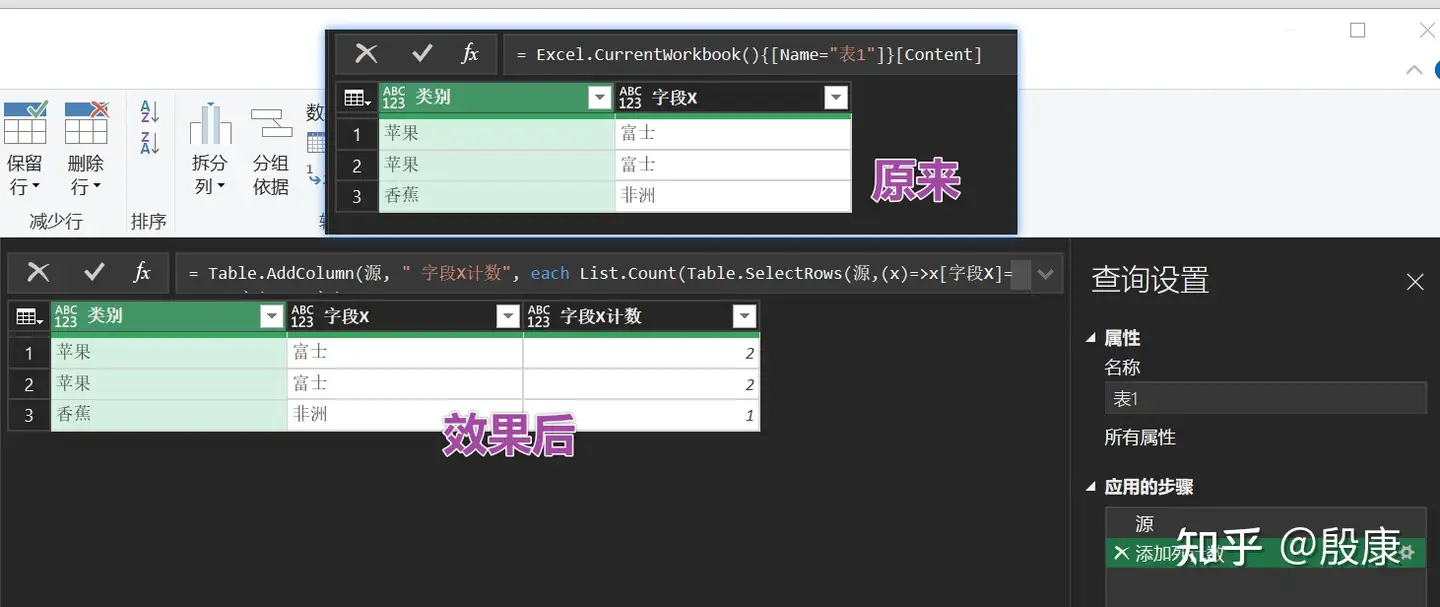
这个方法没有数字直观,但是速度运行明显快过用:List.Count和Table.SelectRows函数。
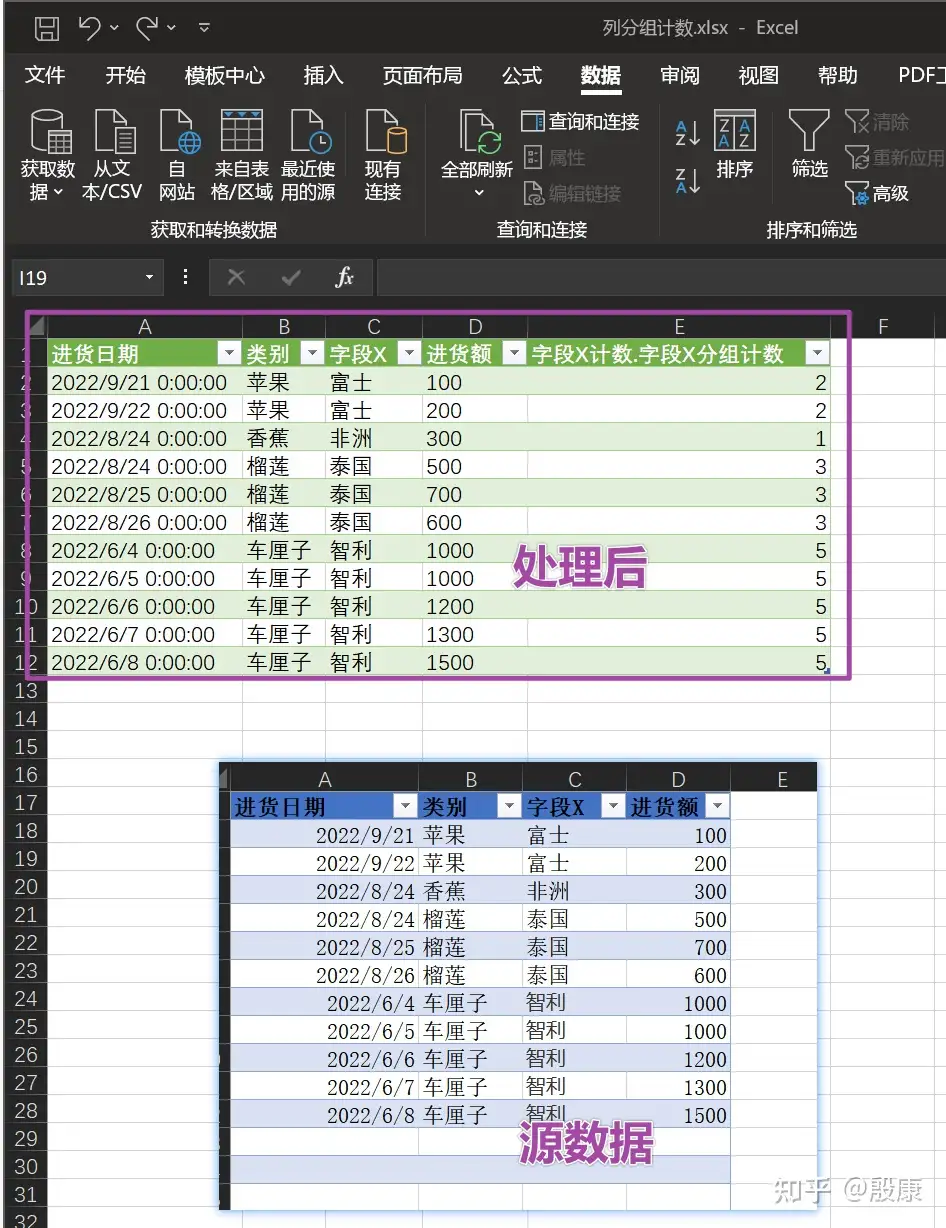
第二种方法是我自己测试想出来的,推荐给大家使用。运行速度超过其他的函数,估计是目前最快的函数方法了, 10多秒可以处理7万行数据。 方法思路如下:
先用 分组函数 进行单列的计数
把单列放在一边
加载之前整个表格
然后在再用匹配函数随便找一个匹配
修改里面的代码,匹配分组步骤名的单列名称。
成功。
需要设计代码操作,我把源表格放在下面:
效果见下图:
<img src="https://picx.zhimg.com/50/v2-21bd19f37ebea450d7f70fc7d8fece27_720w.jpg?source=2c26e567" data-caption="" data-size="normal" data-rawwidth="946" data-rawheight="1228" data-original-token="v2-7f03dfdfa9bd6f669c51aa8195205769" data-default-watermark-src="https://picx.zhimg.com/50/v2-11a17ccf592db09b35b2962ad421fef9_720w.jpg?source=2c26e567" class="origin_image zh-lightbox-thumb" width="946" data-original="https://picx.zhimg.com/v2-21bd19f37ebea450d7f70fc7d8fece27_r.jpg?source=2c26e567"/>
代码如下:
let
源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content],
筛选的行 = Table.SelectRows(源, each ([类别] <> null)),
分组的行 = Table.Group(筛选的行, {"字段X"}, {{"字段X分组计数 ", each Table.RowCount(_), Int64.Type}}),
源重复引用 2 = 筛选的行,
合并的查询 = Table.NestedJoin(源重复引用2, {"字段X"}, 分组的行, {"字段X"}, "字段X计数 ", JoinKind.LeftOuter),
#"展开的“字段X计数”" = Table.ExpandTableColumn(合并的查询, "字段X计数", {"字段X分组计数"}, {"字段X计数.字段X分组计数"})
in
#"展开的“字段X计数”"
为了方便 大家理解和套版,我把源数据上传到百度网盘,方便大家下载参考:
链接:https://pan.baidu.com/s/1FwkTq4o2sedMHNnurFYwZw?pwd=yink
提取码 :yink
你看看这个,大概只有这样了.如果你想多个字段合并计数,多个表格.你就不能用Power query,这个太低效,你要用 Power BI Desktop ,的界面 用线条关联,用 dax函数,就是Power BI 的pivot超级透视 , 他的计算能力强过 query,适合多个表格数据关联和计算. query只适合处理数据.
解释下关于步骤 源重复引用2 源代码 里面修改,修改步骤名为上一个的上一个。每一个步骤名就相当于一个表格,日常所以我们是根据上一个步骤的表格进行修改的,这次是要直接跳过正常步骤,往上一步的上一步走,所以你要理解每一个步骤的生成的表格,然后去用这个生成的表格就是步骤名
我还列出以下三个的方案:运行速度较慢:总体来说没有上面的速度快,2小时7w行数据都没有加载出来,电脑功率直接上升100%。 。下面的数据是网上搜集的,并非自己原创。只是整理出来给大家参考,并不推荐使用。
方法1可以运行。
添加列计数 = Table.AddColumn(上一个步骤名, " 字段X计数", each List.Count(Table.SelectRows(源,(x)=>x[字段X]=[字段X])[字段X])),
<img src="https://picx.zhimg.com/50/v2-df6aa4f45cf11159e3f657bf37b731c7_720w.jpg?source=2c26e567" data-caption="" data-size="normal" data-rawwidth="1462" data-rawheight="616" data-original-token="v2-b08a3a516da168dbc1f80969d13a0d36" data-default-watermark-src="https://picx.zhimg.com/50/v2-8c056aa13f50ab1bdcd5a5c62fa5c198_720w.jpg?source=2c26e567" class="origin_image zh-lightbox-thumb" width="1462" data-original="https://pic1.zhimg.com/v2-df6aa4f45cf11159e3f657bf37b731c7_r.jpg?source=2c26e567"/>
方法2,List.Select (上一个步骤名[字段X],each _=x[字段X]))>1)
<img src="https://pica.zhimg.com/50/v2-44adfa0339b5378074169c1eada89231_720w.jpg?source=2c26e567" data-caption="" data-size="normal" data-rawwidth="1441" data-rawheight="595" data-original-token="v2-035f47fa6d596d481596a02afe3b396f" data-default-watermark-src="https://pica.zhimg.com/50/v2-484c792a37190cf4929e7d3cd4f57871_720w.jpg?source=2c26e567" class="origin_image zh-lightbox-thumb" width="1441" data-original="https://pic1.zhimg.com/v2-44adfa0339b5378074169c1eada89231_r.jpg?source=2c26e567"/>
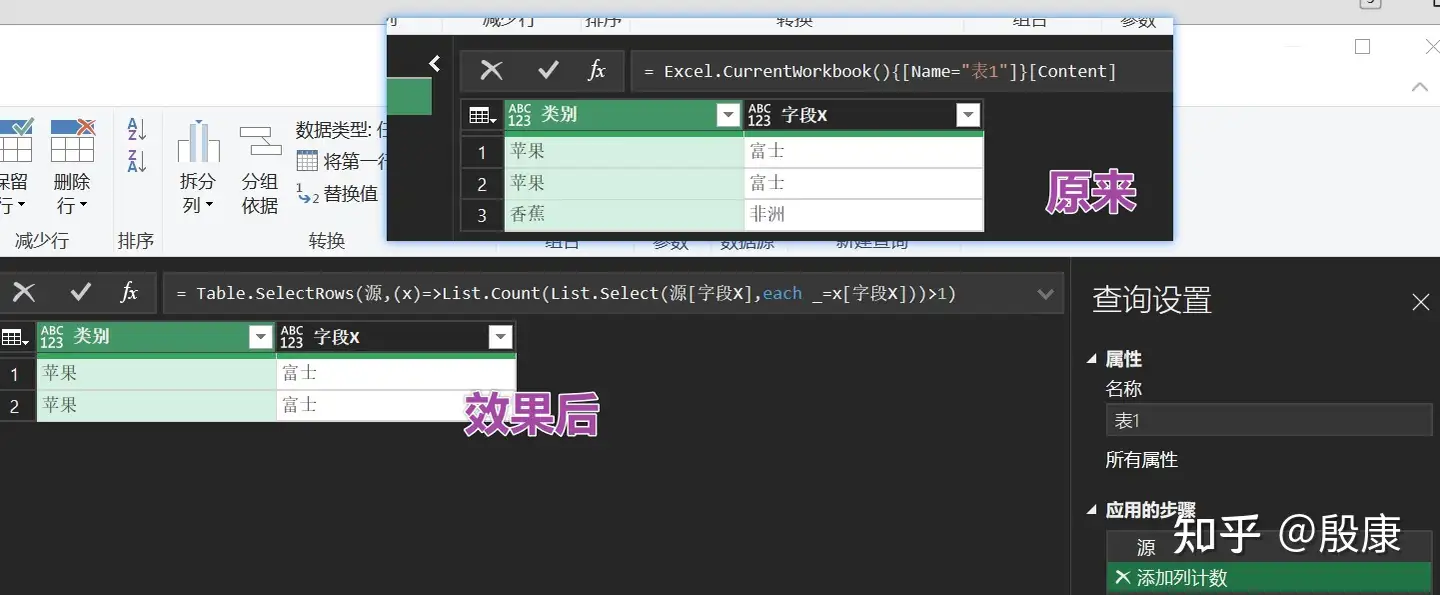
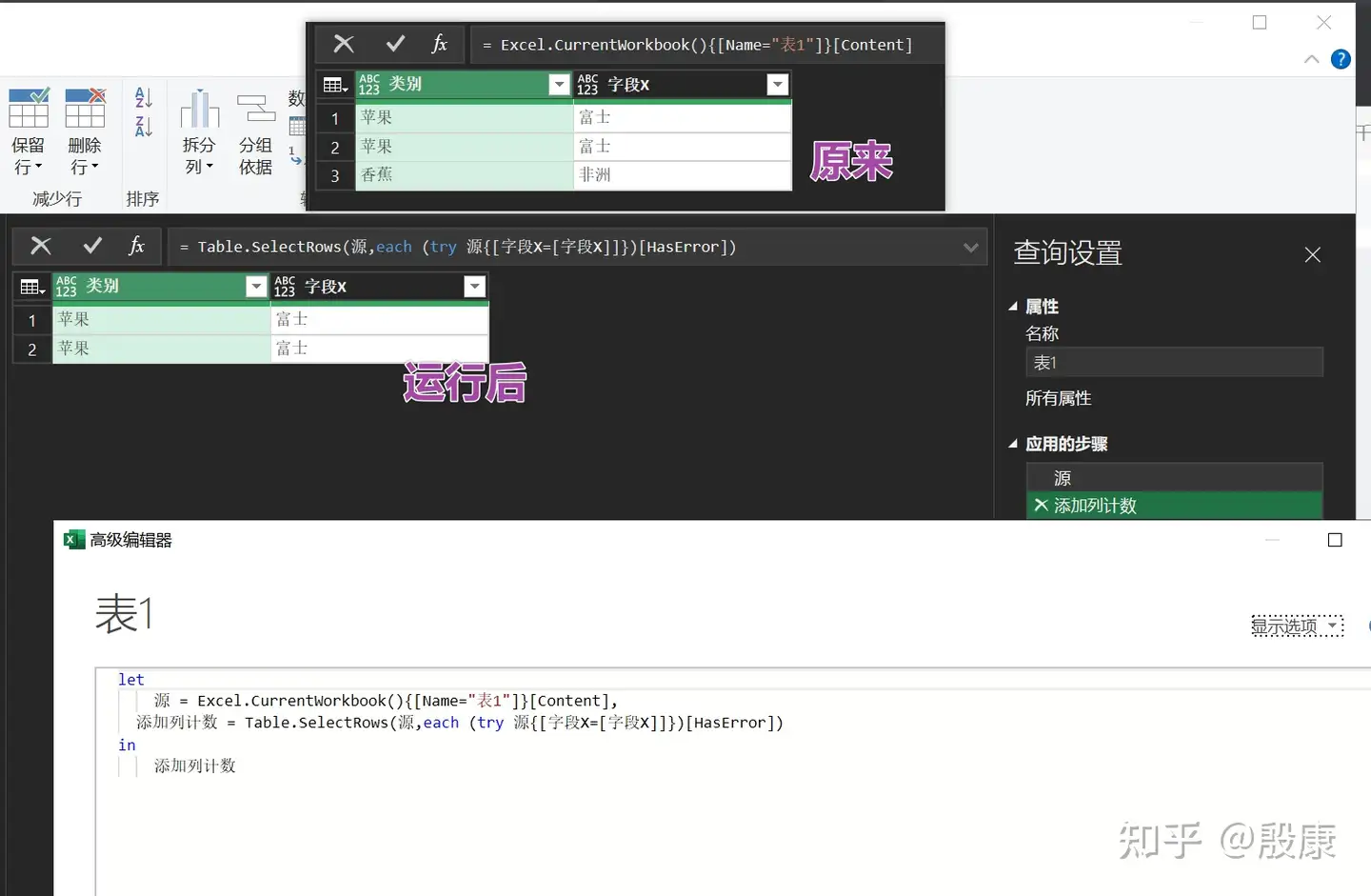
方法3:
保留重复项x2 = Table.SelectRows(上一个步骤名,each (try 上一个步骤名{[字段X=[字段X]]})[HasError])
<img src="https://pic1.zhimg.com/50/v2-42cac024d89c0bdfc8ae8045c157bbff_720w.jpg?source=2c26e567" data-caption="" data-size="normal" data-rawwidth="1507" data-rawheight="985" data-original-token="v2-b42acc515e48034a4a42c74493514dff" data-default-watermark-src="https://picx.zhimg.com/50/v2-fb60a9baf9a22f496b346fa8f9b09c56_720w.jpg?source=2c26e567" class="origin_image zh-lightbox-thumb" width="1507" data-original="https://pic1.zhimg.com/v2-42cac024d89c0bdfc8ae8045c157bbff_r.jpg?source=2c26e567"/>