
oo第三单元总结
一、JML语言的理论基础、应用工具链情况
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言(Behavior Interface Specification Language,BISL),基于Larch方法构建。 可以用来为严格的程序设计提供一套有效的方法。通过JML及其支持工具,不仅可以基于规格自动构造测试用例,还整合了SMT Solver等工具以静态的方式来检查代码实现对规格的满足情况。
JML的主要内容有以下几点:
1.1 注释结构:JML以javadoc注释的方式来表示规格,每行都以@起头。有行注释和块注释两种。
行注释具体形式如下:
//@ ensures \result == nodes.length;
块注释具体形式如下:
/*@ also @ public normal_behavior @ requires obj != null && obj instanceof Path; @ assignable \nothing; @ ensures \result == ((Path) obj).nodes.length == nodes.length) && @ (\forall int i; 0 <= i && i < nodes.length; nodes[i] == ((Path) obj).nodes[i]); @ also @ public normal_behavior @ requires obj == null || !(obj instanceof Path); @ assignable \nothing; @ ensures \result == false; @*/
1.2 JML表达式
原子表达式:常用的原子表达式有以下几种
\result:表示一个非void类型的方法执行所获得的结果,即方法执行后的返回值
\old(expr):用来表示一个表达式expr在相应方法执行前的取值
\not_assigned(x,y,...):用来表示括号中的变量是否在方法执行过程中被赋值。若没有赋值,返回true,否则返回false
\not_modified(x,y,...):限制括号内变量的取值在方法执行过程中是否被改变
量化表达式:
\forall:全称量词修饰表达式
\exists:存在量词修饰表达式
\sum:返回给定范围内的表达式的和
\product:返回给定范围内的表达式的连乘结果
\max:返回给定范围内的表达式的最大值
\min:返回给定范围内的表达式的最小值
\num_of:返回指定变量中满足相应条件的取值个数
操作符:
E1<:E2:子类型关系操作符
b_expr1<==>b_expr2:等价关系操作符
b_expr1==>b_expr2:推理操作符
assignable \nothing:变量引用操作符
1.3、方法规格:
方法规格的核心内容包括三个方面,前置条件、后置条件和副作用约定。其中前置条件是对方法输入参数的限制,如果不满足前置条件,方法执行结果不可预测,或者说不保证方法执行结果的正确性;后置条件是对方法执行结果的限制,如果执行结果满足后置条件,说明方法执行正确,否则执行错误。
2.1 应用工具链情况
OpenJML:OpenJML最基本的功能就是对JML注释的完整性进行检查,检查包括经典的类型检查、变量可见性与可写性等。通过命令行使用OpenJML时,可以通过-check参数指定类型检查:
openjml [-check] options files
JMLUnit:可以用来生成对一个JAVA类文件测试的框架
SMT Solver:可以用来以静态方式来检查代码实现对规格的满足情况
二、部署JMLUnitNG,针对Graph接口的实现自动生成测试用例
我对第10次作业自动生成了测试用例,生成了如下一大坨文件:
对MyGraph_JML_Test.java进行运行,得到结果如下:
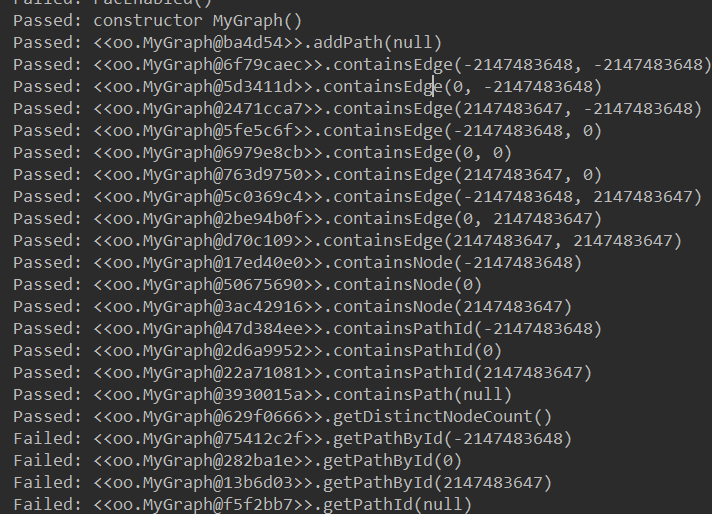
还有一些结果就不贴上来,可以看出这个测试主要是对边界条件进行测试,比如对于int类型的变量就测一下0、-2147483648、2147483647,而对于Object就会测一下null。JMLUnitNG生成测试的能力确实强大,但我感觉似乎也只是对一些边界进行了测试,可能程序中还会有别的bug没有被测出来。
三、作业的架构
1、第9次作业
在本次作业中,任务就是按照给定的JML完成Path和PathContainer两个类中的函数。类图如下:
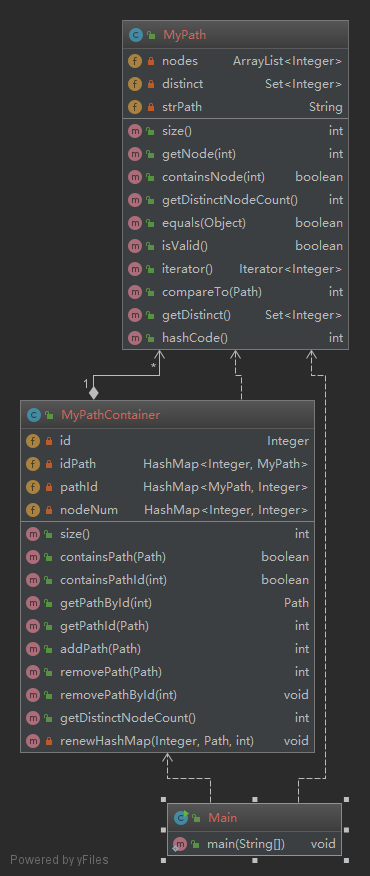
在这个单元里,我按照要求构造了 MyPath 和 MyPathContainer 这两个类。
在 MyPath 中为了方便实现求path中各不相同点这个功能,我在 MyPath 中定义了这样的属性:
private ArrayList<Integer> nodes; private Set<Integer> distinct; private String strPath; public MyPath(int... nodeList) { nodes = new ArrayList<>(); distinct = new HashSet<>(); for (int i = 0; i < nodeList.length; i++) { strPath = strPath + i; nodes.add(nodeList[i]); distinct.add(nodeList[i]); } }
在对path进行初始化时,对每个点依次进行遍历。nodes用于单纯的按顺序存储Path中的各个结点,而distinct用于存储每个path中出现的不同的点。通过这样的构造,在完成getDistinctNodeCount这个函数的功能时,只需要返回distinct集合的size即可
在 MyPathContainer 中需要完成给定id找到对应path和给定path找到对应id的功能,以及加减path还有得到容器全局范围内查找不重复的结点个数的功能,所以 MyPathContainer 中我定义的属性以及功能如下:
private Integer id = 1; private HashMap<Integer,MyPath> idPath;//id与path的映射 private HashMap<MyPath,Integer> pathId;//path与id的映射 private HashMap<Integer,Integer> nodeNum; //几号结点被几条路径所引用
为了加快速度,我采用的都是HashMap这种结构。通过idpath和pathId我能很快的完成id与path之间的相互匹配,而nodeNum则定义了容器范围内不同的结点在多少条路径中出现过,当node出现在0条路径中出现时,则将该node从这个HashMap中移去,则要得到容器全局范围内不重复结点个数则只需要返回nodeNum.size()即可。
每次addPath和removePath都会改变容器中各个HashMap的状态,我于是我写了一个用于更新HashMap的函数,在每次容器状态改变时调用:
private void renewHashMap(Integer id,Path path,int flag) { Set<Integer> tmp = ((MyPath)path).getDistinct(); //得到path的不重复的结点集合 if (flag == 1) { //表示加 idPath.put(id,(MyPath)path); //每来一个path,将其加入hashmap中 pathId.put((MyPath)path,id); for (Integer tmpint : tmp) { if (nodeNum.containsKey(tmpint)) { // 如果存在这个key int num = nodeNum.get(tmpint); nodeNum.put(tmpint,num + 1); //覆盖原来的值 } else { nodeNum.put(tmpint,1); } } } else { //表示remove idPath.remove(id); pathId.remove(path); for (Integer tmpint : tmp) { int num = nodeNum.get(tmpint); if (num != 1) { nodeNum.put(tmpint, num - 1); //覆盖原来的值 } else { nodeNum.remove(tmpint); } } } }
2、第10次作业
这次作业在上次作业的基础上增加了图结构,要求将容器中的path构建成为无向图结构,并基于无向图进行查询工作。相比上次作业,查询功能增加了对无向图中边的查询、两个点的连通性查询以及两点之间最短路径的查询。针对边查询,我新增了MyPair类,用于表示一条边,且总是保证结点号小的点在前面,并在MyPath类和MyGraph类中维护边的存在关系;针对连通性以及最短路径,我新增了MyMap类,在这个类里完成无向图的构建以及最短路径的求解。本次作业的类图如下:
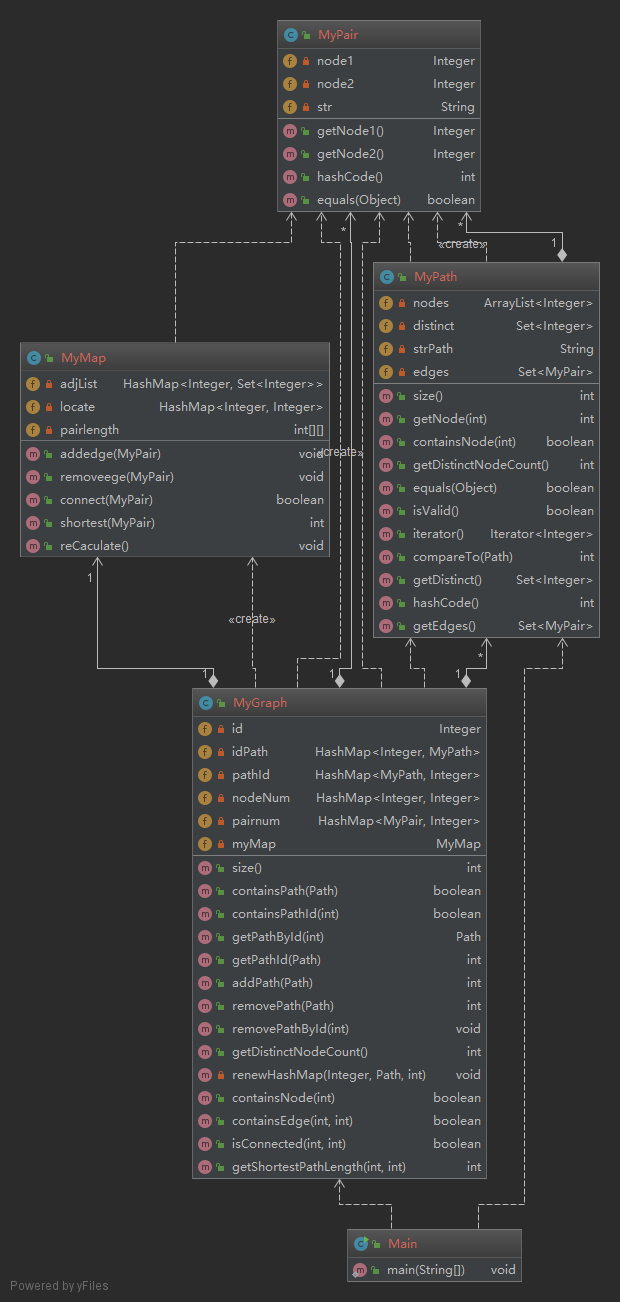
各个类的属性及功能如下:
//MyGraph private Integer id = 1; // 从1开始 private HashMap<Integer,MyPath> idPath; private HashMap<MyPath,Integer> pathId; private HashMap<Integer,Integer> nodeNum; //几号结点被几条路径所引用 private HashMap<MyPair,Integer> pairnum;//一对点在多少个路径中出现过 private MyMap myMap; //MyMap private HashMap<Integer, Set<Integer>> adjList;//邻接链表 private HashMap<Integer,Integer> locate;//完成结点到数组下标的映射 private int[][] pairlength; //存两点间的最短距离 //MyPath private ArrayList<Integer> nodes; //path的点集合 private Set<Integer> distinct; //path的不重复的点集合 private String strPath; private Set<MyPair> edges; //path中边的集合 //MyPair private Integer node1; private Integer node2; private String str;
在MyPath中新增了edges边集,所以在path初始化时对各个点进行遍历时同时将各条之间相连的边加入edges集合中,除此之外MyPath并无大变化。
在MyGraph中,除了新增的要求,其余方法与第九次作业一样。新增的pairnum映射关系用于回答边查询,则每次增减path时,还需要维护pairnum这个关系,所以需要在第九次作业中的renewHashMap中多更新一个pairnum。此外,加减的path中所有的边如果在加减后对图的结构并没有改变,则不需要更新图;而只要path中有一条边的增减导致了图结构的变化,则还需要将新增加或删减的边在图中进行更新(更新图中的邻接链表),所以需要调用mymap中的addedge或者removeege方法更新无向图,最后还需要重新计算图中各点最短距离。每当查询点的连通性和最短路径时就调用mymap中的相关函数进行查询。
在MyMap中维护了图的邻接链表以及一个二维矩阵pairlength用于存处两点之间的最短距离,并用locate完成结点到数组下标的映射。因为图结构变更指令很少,于是我采用了每次addPath和removePath的时候判断图结构是否改变(通过pairnum可以判断,addpath时如果每个pair都已经存在,则说明图结构不变,removepath类似),若图结构发生了变化,则在整个path处理完之后,用MyMap里已经更新好了的邻接表来完成对locate映射关系的更新,再对每个点进行迪杰斯特拉,最后得到更新好的最短路径矩阵。因为无向图中的边权重都是1,所以这里的迪杰斯特拉类似于广搜求树的深度。在更新了pairlength矩阵后,每次查询只需要访问矩阵中的值即可。具体代码如下:
public void reCaculate() { //每次外部增加路径或减少路径,都要重新更新图,并重新算最小路径 locate = new HashMap<>(); int num = 0; for (Integer key:adjList.keySet()) { locate.put(key,num); num++; //建立映射 } pairlength = new int [num][num]; //二维矩阵存最短路径 for (int i = 0;i < num;i++) { for (int j = 0;j < num;j++) { pairlength[i][j] = -1;//为-1表示没有连通 } } for (Integer key: adjList.keySet()) { //每个点进行迪杰斯特拉 int i; int j; //ArrayList<Integer> queue = new ArrayList<>(); Set<Integer> symbol = new HashSet<>();//symbol中的点都是已经算出来了的 Set<Integer> adjSet;//得到key的邻接点 i = locate.get(key); pairlength[i][i] = 0;//key到自己的距离为0 symbol.add(key); ArrayList<Integer> queue = new ArrayList<>(); queue.add(key); while (queue.size() != 0) { Integer node = queue.remove(0); adjSet = adjList.get(node);//得到node的邻接点 for (Integer adj: adjSet) { //对node的每个邻接点adj操作 if (!symbol.contains(adj)) { //若还不在这个里面,说明这个点还没算过最短距离 i = locate.get(key); j = locate.get(adj); int nodeIndex = locate.get(node); int length = pairlength[i][nodeIndex]; pairlength[i][j] = length + 1; pairlength[j][i] = length + 1; queue.add(adj);//入队 symbol.add(adj); } //else //说明这个点已经被算过了,也已经入过队了,所以不入队 } } } }
3、第11次作业
在本次作业中,需要构建一个简单的地铁系统,除了最短路径,还需要对最少换乘、最小不满意度、最小票价完成查询。为了完成换乘这个概念,我在本次作业中采用了分点的思想,对于无向图中每个点都用(id,pathid)来表示,即这个点本身的结点号以及它所在的path的id,然后针对每一个结点id,都创建一个上层的相应总点(id,0)。则无向图中,除了同一个path中的各个点相互相连,每个点还与自己的总点相连。总点就相当于一个换乘点,任何需要先到总点再换另一个点的路径都表示进行了一次换乘。
使用这样的方法,可以构建出能带有换乘含义的无向图,然后再通过对每条边赋上不同的权重,同样使用迪杰斯特拉算法,就能完成对最小路径、最少换乘、最小不满意度、最小票价的全部查询(比如每次查询两点之间的最小路径之类的时候,可以通过对这两个点的总点进行迪杰斯特拉算出最小距离,再进行简单的转换得到最终结果)。因为这四种查询对应需要赋的权重并不相同,于是我在MyGraph里面挂了四个MyMap,每个MyMap中都包含了一个邻接链表adjListNew(邻接链表中新增了一项用于保存两点之间边的权重)、一个缓存矩阵BuffMatrix(存储迪杰斯特拉算出来的最短距离)、和一个标志(表示这个map是用来算最小路径还是最少换乘等)。和第九次作业类似,在MyGraph中我仍然保留了一个renewHashMap函数,每次进行了addPath、removePath的操作后,都要重新更新MyGraph中各个hashmap以及让四个MyMap都进行addedge和removeedge的操作,更新四个MyMap中的邻接链表的操作。因为求解两点之间四种不同数值的方法最后都归结为了求最短路径,下面我就直接用求解最短路径代指这求解四种不同的数值了。
到上面为止,其实对第11次作业而言,基本思路和第10次作业差不多,但在计算最短距离上,我没有再像第10次作业一样,每次addPath或removePath之后当图改变时就重新计算最短路径,因为针对本次作业而言,图中结点变成了(id,pathid)的形式,也就是说图中结点个数大大增加,如果仍像第10次作业一样,那么耗时会非常高,所以这次的作业我采用了指导书中类似于滚雪球的方法,每次更新图时我更新了MyMap中的邻接链表,只有当查询某两个之间的距离时我才会调用缓存矩阵中的方法进行单源点迪杰斯特拉的求解,并将中途求出来的值也一并放入缓存矩阵中。因为再求两个点的最短距离时直接求总点之间的就行了,所以我在缓存矩阵中又放了一个二维数组pairlength,这个矩阵代表各个单纯的结点id之间的最短距离。每次查询两点之间最短路径时直接访问pairlength二维数组的值即可。但值得注意的是一旦图改变了,我虽然没有立即重新计算最小距离,但我会立即将矩阵重新初始化,因为之前算过的最短路径因为图的改变而无效了。
第11次作业的类图如下:

在BuffMatrix这个类中,我定义的属性如下:
private int[][] matrix;//存各个id,pathid到别的id,pathid的值 private int num; private String tag; private HashMap<MyNode,Integer> nodeIndex; private HashMap<Integer,MyNode> indexNode; private HashMap<MyNode, Set<NodeInfor>> adjListNew; private HashMap<Integer,Integer> nodeidIndex;//单纯的对于点id到pairlength的数组下标映射 private int[][] pairlength; //存已经查出来了的两点间的最短距离 private static final int Max = 2000000000;
其中tag标志了这个矩阵对应的是求最小路径还是最少换乘等。Max是矩阵中的初始值,查询时若发现矩阵中的值是Max,则表示这两个点不可达。因为针对四种不同的求值都转换为了使用迪杰斯特拉来计算最短路径,但其实求出来的最短路径与这四种值之间还是需要一定的转换的,我写了如下的方法,来完成取出缓存矩阵中的最短路径值并将其转换为最终结果并返回:
private int getres(int get) { //不同类型的矩阵算出最小路径后,转为所需要的值 int res; if (get == 0) { //只可能是自己到自己的时候,则直接返回0 return 0; } switch (tag) { case "S": //最小路径 res = get; break; case "T": //最少换乘 res = get / 2 - 1; break; case "P"://最少票价 res = get - 2; break; //case "U": default://最小不满意度 res = get - 32; } return res; }
四、bug分析
在这三次作业中中测和强测最终都通过了。在课下测试的时候正确性测试和极端测试都有进行,幸好最后结果也都还不错。
但在第三次作业的中,当我整体代码完成后,我进行了一个比较极端的大型测试,发现我的程序跑的十分的慢,大概要跑10几分钟,这远远超出了最大要求35s。当时整个人就崩了,开始怀疑自己的架构是不是有问题,反省到了晚上三点也没得到什么结果,草草睡觉,早上起来接着看。最后找了很久的原因之后,发现是我的迪杰斯特拉中用于标记一个点是否已经得到最短距离的数据结构有问题,我使用了hastset来标记,每当这个点完成了计算就将它放入set中,然后每次迭代时找的是不在set中的,目前到源点距离最短的点。后来我把hashset改成了一个数组,每个点与数组下标有一个映射关系,每当这个点的最短距离已经算出来时我就将数组中的值置为1,则每次找不在set中的点时只需要去看对应数组位置的置是否为1,若不为,则说明这个点的最短距离还没有被算出来。这样一改,速度就大大提高了,原本跑十多分钟的程序只需要十几秒就能结束,不得不说选择数据结构真的很重要。
五、心得体会
JML规格还是很有用很方便的,通过短短几行便能将一个方法的功能没有二义性的表述清楚。经过这三次作业,以及实验课,我体会到要写出一个方法的JML就必须对这个方法的正常情况、异常情况都清楚掌握,同时将正常情况下的各种子情况、异常情况下的各种子情况都罗列清楚才能完整的写出正确的JML。同时对于一些复杂的方法,还需要构建中间层的JML来完成表述。虽然对JML有了一定的了解,但我觉得自己掌握得并不是很好,自己来写的话可能还会有一些纰漏,自己下来还是应该再学一学。
这三次作业的整体架构是层层递进的,让我体会到了一个工程项目不断完善的感觉。这次作业前两次的架构也都不错,所以我每次作业都是不断的在之前的基础上进行扩展的,对比以前写电梯的时候,感觉自己每次作业基本都是重构,我觉得我还是有了一定的进步。
oo还有最后一个单元了,希望自己能继续加油,迎接最后一个单元!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号