
Lab9 file system
预备知识
Xv6文件系统
文件系统的目的是组织和存储数据。通常支持用户和应用程序之间的数据共享以及持久性,以便数据在重新引导后仍然可用。它需要解决以下几个问题:
- 文件系统需要磁盘上的数据结构来表示命名目录和文件的树,以记录保存每个文件内容的块的标识,并记录磁盘的哪些区域是空闲的。
- 文件系统必须支持崩溃恢复。如果发生崩溃(例如,电源故障),文件系统必须在重新启动后仍能正常工作。风险在于崩溃可能会中断更新序列,并在磁盘上留下不一致的数据结构(例如,在文件中使用并标记为空闲的块)。
- 不同的进程可能同时在文件系统上运行,因此文件系统代码必须协调以维护不变量。
- 访问磁比访问内存慢几个数量级,因此文件系统必须维护某些块的内存缓存。

如图,Xv6文件系统分为7层实现:
File descriptor:文件描述符层 使用文件系统接口抽象了许多Unix资源(比如管道、设备、文件等);
Pathname:路径名层 提供了分层路径名,如/usr/rtm/xv 6/fs.c;
Directory:目录层 将每个目录实现为一种特殊的inode,其内容是一系列目录条目,每个条目包含文件名和索引号;
Inode:索引结点层 提供单独的文件,每个文件表示为一个索引结点,其中包含唯一的索引号(i-number)和一些保存文件数据的块;
Logging:日志记录层 允许更高的层在一次事务中将更新推送到多个块,并确保在遇到崩溃时自动更新这些块(即,所有块都已更新或无更新);
Buffer cache:缓冲区/高速缓存层 缓存磁盘块并同步对它们的访问,确保每次只有一个内核进程可以修改存储在任何特定块中的数据;
Dsik:磁盘层 读取和写入virtio硬盘上的块。
下面详细介绍一下实验中会用到的相关层。
磁盘层
Xv6系统使用 块 对磁盘进行抽象,文件系统中的操作都是对块的操作。因此从操作系统的角度来看,磁盘就是很多个 块 组合在一起。
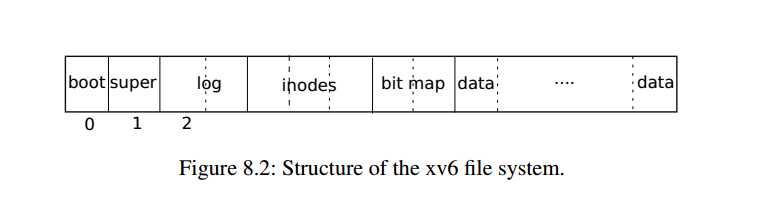
- 文件系统不使用块0(它保存引导扇区)
- 块1称为超级块:它包含有关文件系统的元数据(文件系统大小(以块为单位)、数据块数、索引节点数和日志中的块数)。超级块由一个名为 mkfs的单独的程序填充,该程序构建初始文件系统;
- 从2开始的块保存日志;
- 日志之后是索引节点,每个块有多个索引节点;
- 然后是位图块,跟踪正在使用的数据块;
- 其余的块是数据块:每个都要么在位图块中标记为空闲,要么保存文件或目录的内容;
缓冲区层
这一层其实在上个实验已经了解的差不多了(bio.c), 就不多写了。主要了解一下缓冲区层的工作过程。
bread 获取一个buf,其中包含一个可以在内存中读取或修改的块的副本;
bwrite 将修改后的缓冲区写入磁盘上的相应块;
内核线程必须通过调用 brelse 释放缓冲区。Buffer cache为每个缓冲区使用一个睡眠锁,以确保每个缓冲区(即磁盘块)每次只被一个线程使用;bread 返回一个上锁的缓冲区,brelse 释放该锁。
索引层
inode有两种,一种是磁盘上的数据结构 dinode,大小为64B:
//kernel/fs.h
struct dinode {
short type; // 文件类型,表明inode是文件(1)、目录(2)还是设备(3),或者未使用(0)
short major; //主设备号,标识设备类型,文件类型为设备时有效
short minor; //从设备号,标识具体设备,文件类型为设备时有效
short nlink; //记录引用该dinode的数目,为0时释放该inode和占有的数据块
uint size; //文件大小,单位为字节
uint addrs[NDIRECT+1]; //记录保存文件内容的数据块地址
//前NDIRECT(12)为直接索引,即直接指向数据块号
//最后一个为一级间接索引,指向保存数据块号的数据块,这个间接索引可以保存:1KB(块大小)/ 4B(uint)= 256个数据块
//因此Xv6最大支持的文件大小为:(12+256)*1KB = 268KB
};
一种是内存inode,当文件被访问时系统会加载 dinode 到内存中,并维护这个副本。只有有指针引用 dinode 时才会在内存中:
struct inode {
uint dev; //设备号
uint inum; // inode 号
int ref; // 引用计数,为0时从内存中清理该inode
struct sleeplock lock; //保护以下内容
int valid; // inode是否与磁盘状态一致
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};
内存inode有四种锁机制:
- icache.lock: 保护全局 inode 缓存(icache),确保每个 inode 在缓存中最多只有一个副本,保护 inode中 ref 字段的正确性,即记录指向该 inode 的内存指针的正确数量;
- inode的 struct sleeplock lock 字段: 每个 inode 的独立锁,用于对该 inode 的独占访问,确保对 inode 的元数据字段和其内容块的修改是线程安全的;
- inode的 ref 字段: 管理内存 inode 的生命周期,记录指向该 inode 的C指针数量。如果 ref 减少到 0,表示内存中已没有任何代码持有该 inode 的引用,缓存可以移除该inode,但 inode 在磁盘上仍然存在;
- inode的 nlink 字段: 管理磁盘 inode 的生命周期,记录指向该inode的目录项(创建硬链接)。当nlink 减少到 0,表示没有任何目录项指向该 inode,如果 inode 的内容已经不在内存中(即 ref ==0),该 inode 将被完全释放,包括inode 本身和它占用的所有数据块。
但这里有个问题,关于 nlink :即使文件的 nlink 降为 0,某些进程仍可能持有该 inode 的引用(比如进程打开了该文件并正在读写)。如果在最后一个进程关闭该文件之前发生崩溃,inode 会以一种不一致状态留存在磁盘上:文件在磁盘上被标记为“已分配”,但磁盘上没有任何目录项指向该 inode,导致用户无法访问该磁盘inode。随着时间推移,磁盘空间会被这些“不再使用但未释放”的 inode 逐渐耗尽。
现代文件系统通过两种方式解决这一问题:
文件系统在崩溃后重新启动时,扫描整个磁盘上的所有 inode,查找标记为“已分配”但没有任何目录项引用的 inode,释放它们的空间,回收资源;
文件系统维护一个列表(比如记录在超级块中),用来跟踪nlink为0,但引用计数不为0的inode.当系统重新启动时,只需检查这个列表中的 inode 是否仍然有进程引用,如果没有引用(ref为 0)释放它们。
几个重要的函数:
struct inode* ialloc(uint, short):从磁盘中分配一个空闲的dinode,并返回内存inode
void ilock(struct inode):获取inode的睡眠锁,并在valid为0时从磁盘读对应的dinode数据
void iput(struct inode):释放内存inode的引用,即ref-1;当ref和inode.nlink为0,则释放磁盘inode和数据块
void iunlock(struct inode):释放该Inode的睡眠锁
void iunlockput(struct inode):iunlock()+iput()
void iupdate(struct inode):更新该inode的信息到磁盘中
struct inode namei(char* path):返回该path对应文件的inode
int readi(struct inode* ip, int user_dst, uint64 dst, uint off, uint n):从inode对应的文件中的指定偏移量(off)开始读取指定长度(n)的数据到目标地址中(dst),user_dst字段指示目的地址是用户地址还是内核地址
int writei(struct inode* ip, int user_dst, uint64 dst, uint off, uint n):从源地址(dst)向inode对应的文件中的指定偏移量(off)开始写入指定长度(n)的数据,user_dst字段指示源地址是用户地址还是内核地址
void itrunc(struct inode):删除inode的数据块数据,同时回收该inode对应的磁盘中的dinode
static struct inode create(char* path, short type, short major, short minor):创建一个指向path文件的类型为type的node
Large files
修改 xv6 文件系统,使得支持的最大文件由当前的268个扩展到 65803 个块组成:256 * 256 + 256 + 11 = 65803。因此采用11个直接块+1个一级间接块+1个二级间接块。
修改inode
修改dinode
//kernel/fs.h
#define NDIRECT 11
#define N2INDIRECT (NINDIRECT*NINDIRECT) //二级间接块最多能保存的块数目
#define MAXFILE (NDIRECT + NINDIRECT + N2INDIRECT)
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1+1]; // Data block addresses
};
同样还有修改内存中的dinode副本
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1+1];
};
修改映射逻辑
先看一下原来的逻辑。
//kernel/fs.c
//输入:ip是指向inode的指针,bn是文件内的逻辑块号。
//输出:返回磁盘上的物理块地址。
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
//直接映射
if(bn < NDIRECT){
if((addr = ip->addrs[bn]) == 0) //如果addr为0则说明该块还为分配
ip->addrs[bn] = addr = balloc(ip->dev);//执行分配
return addr;
}
//一级间接映射
bn -= NDIRECT;
if(bn < NINDIRECT){
//如果间接块未分配则执行分配
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
//还要检查bn对应的块是否分配
//bread函数会返回一个上锁的缓冲区
bp = bread(ip->dev, addr);
//将缓冲区bp视为一个整数数组处理
//因为bn减去了NDIRECT,所以bn就是间接块的偏移量
a = (uint*)bp->data;
if((addr = a[bn]) == 0){
a[bn] = addr = balloc(ip->dev);
log_write(bp);//将修改后的间接块写入日志
}
brelse(bp);//释放缓冲区
return addr;
}
panic("bmap: out of range");
}
修改:
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
//直接映射
...
//一级间接映射
bn -= NDIRECT;
...
//新增二级间接块的处理
bn -= NINDIRECT;
if( bn < N2INDIRECT){
if((addr = ip->addrs[NDIRECT + 1]) == 0)
ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev);
//检查对应的中间一级间接块
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn / NINDIRECT]) == 0){
a[bn / NINDIRECT] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
//对应的数据块
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn % NINDIRECT]) == 0){
a[bn % NINDIRECT] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
panic("bmap: out of range");
}
修改释放逻辑
直接看代码,注意从底往上释放就行
//kernel/fs.c
void
itrunc(struct inode *ip)
{
int i, j;
struct buf *bp;
uint *a;
for(i = 0; i < NDIRECT; i++){
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
if(ip->addrs[NDIRECT]){
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
//先释放数据块再释放间接块
if( ip->addrs[NDIRECT + 1]){
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for( i = 0; i < NINDIRECT; ++i){
if(a[i]){
struct buf* bp2 = bread(ip->dev, a[i]);
uint* a2 = (uint*)bp2->data;
for(j = 0; j < NINDIRECT; ++j){
if(a2[j])
bfree(ip->dev, a2[j]);
}
brelse(bp2);
bfree(ip->dev, a[i]);
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT + 1]);
ip->addrs[NDIRECT + 1] = 0;
}
ip->size = 0;
iupdate(ip);
}
最后make qemu执行bigfile
$ bigfile
//很多.
wrote 65803 blocks
bigfile done; ok
同样usertests也都能通过。
Symbolic links
为Xv6添加符号链接(软链接):实现symlink(char* target, char* path)系统调用,该调用在 path 路径下创建一个新的符号链接,指向由 target 指定的文件。
系统调用注册
//user/user.h
//system calls
int symlink(const char*, const char*);
//系统调用入口
//user/usys.pl
enter("symlink");
//Makefile
$U/_symlinktest\
//系统调用号
//kernel/syscall.h
#define SYS_symlink 22
//声明处理函数,并与系统调用号关联
//kernel/syscall.c
extern uint64 sys_symlink(void);
[SYS_symlink] sys_symlink,
补充相关常量
//新增文件类型为符号链接
//kernel/stat.h
#define T_SYMLINK 4 //符号链接
//新增标志,这个标志是为了与open系统调用配合
//kernel/fcntl.h
#define O_NOFPOLLOW 0x800
实现symlink
//kernel/sysfile.c
uint64
sys_symlink(void)
{
char target[MAXPATH], path[MAXPATH];
if(argstr(0, target ,MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0)
return -1;
struct inode* node;
begin_op(); //所有FS文件系统的系统调用的开始都需要调用
node = create(path, T_SYMLINK, 0 ,0);//创建一个路径为path的T_SYMLINK类型的 inode
if( node == 0 ){
end_op();
//printf("err_sys_sumlink_create_inode\n");
return -1;
}
if(writei(node, 0, (uint64)target,0, strlen(target)) < 0){//将target写入node
end_op();
//printf("err_sys_sumlink_writei_inode\n");
return -1;
}
iunlockput(node);//create创建的inode会加锁
end_op();
return 0;
}
除此外还要修改open()系统调用:也就是当打开的是一个软链接要不断递归,直到找到真正的文件;或者递归深度超过10.
//kernel/sysfile.c
//sys_open()
...
else {
if((ip = namei(path)) == 0){
end_op();
return -1;
}
ilock(ip);
int count = 0; //记录递归的次数
while( count < 10 && ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)){
if(readi(ip, 0, (uint64)path, 0, MAXPATH) < 0){
iunlockput(ip);
end_op();
return -1;
}
iunlockput(ip);
if( (ip = namei(path)) == 0){
end_op();
return -1;
}
ilock(ip);
count++;
}
if( count >= 10){
iunlockput(ip);
end_op();
return -1;
}
if(ip->type == T_DIR && omode != O_RDONLY){
iunlockput(ip);
end_op();
return -1;
}
}
...
最后测试,能够通过symlinktest和usertests
$ symlinktest
Start: test symlinks
test symlinks: ok
Start: test concurrent symlinks
test concurrent symlinks: ok

 浙公网安备 33010602011771号
浙公网安备 33010602011771号