

More Effective C++: 04效率
16:牢记80-20准则
80-20准则说的是大约20%的代码使用了80%的程序资源;大约20%的代码耗用了大约80%的运行时间;大约20%的代码使用了80%的内存;大约20%的代码执行80%的磁盘访问;80%的维护投入于大约20%的代码上。当提到80-20准则时,不要在具体数字上纠缠不清,一些人喜欢更严格的90-10准则。不管准确的数字是多少,基本的观点是一样的:软件整体的性能取决于代码组成中的一小部分。
80-20准则意味着如果你的软件出现了性能问题,你必须能找到导致问题的那一小块代码的位置。因此需要使用某个程序分析器识别出令人讨厌的程序的20%部分,并且用尽可能多的数据来分析你的软件,必须确保每组数据在客户如何使用软件方面能有代表性。
17:考虑使用lazy evaluation(惰性计算法)
所谓lazy evaluation(惰性计算法),是指采用某种方式撰写class,使它们延迟计算,直到那些运算结果确实被需要为止,如果其运算结果一直不被需要,则运算也就一直不执行。下面是lazy evaluation的应用示例:
1:引用计数
// 一个string 类 (标准库中的string类可能按照下面介绍的方法实现,但也不是非得要这样)
class String { ... };
String s1 = "Hello";
String s2 = s1; //调用拷贝构造函数
拷贝构造函数的通常做法是让s2被s1初始化后,s1和s2都有自己的"Hello"拷贝。这种拷贝构造函数会引起较大的开销:这通常需要用new操作符分配堆内存,需要调用strcpy函数拷贝s1内的数据到s2。这是一个eager evaluation(立即求值):只因为调用了拷贝构造函数,就要制作s1值的拷贝并把它赋给s2。然而实际上这时的s2并不需要这个值的拷贝,因为s2没有被使用。
如果使用lazy evaluation实现的话,不赋给s2一个s1的拷贝,而是让s2与s1共享一个值。我们只须做一些记录以便知道谁在共享什么,就能够省掉调用new和拷贝字符的开销。s1和s2共享一个数据结构,对于client来说是透明的。
这种方法对于读操作而言,并没有什么差别,仅当这个或那个String的值被修改时,共享同一个值的方法才会造成差异,例如s2.convertToUpperCase(); 此时应仅修改s2的值,而不是连s1的值一块修改。因此String的convertToUpperCase函数应该制作s2值的一个拷贝,在修改前把这个私有的值赋给s2。因此,如果不修改s2,我们就不用制作它自己值的拷贝。继续保持共享值直到程序退出。
2:区分读和写
继续讨论上面的reference-counting String对象。考虑这样的代码:
String s = "Homer's Iliad"; // 假设是一个 reference-counted string
cout << s[3]; // 调用 operator[] 读取s[3]
s[3] = 'x'; // 调用 operator[] 写入 s[3]
首先调用operator[]读取String,然后调用operator[]完成写操作。我们应能够区别对待读操作和写操作,因为读取reference-counted String是很容易的,而写入这个String则需要在写入前对该String值制作一个新拷贝。
为了能够这样做,需要在operator[]里采取不同的措施。问题是如何判断调用operator[]的上下文是读操作还是写操作呢?事实是我们不可能判断出来,然而通过使用lazy evaluation和条款30中讲述的proxy class,我们可以推迟做出是读操作还是写操作的决定,直到我们能判断出正确的答案。
3:Lazy Fetching(惰性提取)
假设你的程序使用了一些包含许多字段的大型对象,这些对象保存在数据库里。每一个对象都有一个唯一的对象标识符,用来从数据库中重新获得对象:
class LargeObject { // 大型持久对象
public:
LargeObject(ObjectID id); // 从数据库中恢复对象
const string& field1() const; // field 1的值
int field2() const; // field 2的值
double field3() const; // ...
const string& field4() const;
const string& field5() const;
...
};
void restoreAndProcessObject(ObjectID id)
{
LargeObject object(id);
if (object.field2() == 0) {
cout << "Object " << id << ": null field2.\n";
}
}
LargeObject对象很大,为这样的对象使用数据库操作获取所有的数据开销将非常大,而在这种情况下,不需要读取所有数据。上面的代码中,仅需要filed2的值,所以为获取其它字段而付出的努力都是浪费。
这种情况下, 延迟做法是,当LargeObject对象被建立时,不从数据库中读取所有的数据,这时建立的仅是一个对象“壳”,当需要某个数据时,这个数据才被从数据库中取回:
class LargeObject {
public:
LargeObject(ObjectID id);
const string& field1() const;
int field2() const;
double field3() const;
const string& field4() const;
...
private:
ObjectID oid;
mutable string *field1Value;
mutable int *field2Value;
mutable double *field3Value;
mutable string *field4Value;
...
};
LargeObject::LargeObject(ObjectID id) : oid(id), field1Value(0), field2Value(0), field3Value(0), ...
{}
const string& LargeObject::field1() const
{
if (field1Value == 0) {
//从数据库中为filed 1读取数据,使field1Value 指向这个值;
...
}
return *field1Value;
}
对象中每个字段都用一个指向数据的指针来表示,LargeObject构造函数把每个指针初始化为NULL,这表示该字段还没有从数据库中读取数值。每个LargeObject成员函数在访问字段指针所指向的数据之前必须字段指针检查的状态。如果指针为空,在对数据进行操作之前必须从数据库中读取对应的数据。
因为所有成员函数中都有可能需要初始化空指针使其指向真实的数据,包括const成员函数里,因此,这里使用mutable关键字。
4:Lazy Expression Evaluation(惰性表达式计算)
template<class T>
class Matrix { ... };
Matrix<int> m1(1000, 1000); // 一个 1000 * 1000 的矩阵
Matrix<int> m2(1000, 1000);
Matrix<int> m3 = m1 + m2; // 计算m1+m2
通常operator+的实现使用eagar evaluation,上面的代码中,它会计算并返回m1与m2的和。这个计算量相当大(1000000次加法运算),而且系统也会分配内存来存储这些值。
lazy evaluation方法说这样做工作太多,所以还是不要去做。而是应该建立一个数据结构于m3中,表示m3的值是m1与m2的和。这样的数据结构可能只是两个指针和一个enum构成,两个指针分别指向m1和m2,enum表示运算动作是加法。很明显,建立这个数据结构比m1与m2相加要快许多,也能够节省大量的内存。假设之后像这样使用m3:cout << m3[4]; 这里要打印m3的第四行,因此我们不能再懒惰了,应该计算m3的第四行值。但是没有理由计算m3第四行以外的结果,因此m3其余的部分仍旧保持未计算的状态直到确实需要它们的值。
我们怎么可能这么走运呢(仅仅需要部分结果)?矩阵计算领域的经验显示这种可能性很大。实际上lazy evaluation就存在于APL语言中。APL能够进行基于矩阵的交互式的运算。APL表面上能够进行进行矩阵的加、乘,甚至能够快速地与大矩阵相除!它的技巧就是lazy evaluation。这个技巧通常是有效的,因为一般APL的用户加、乘或除以矩阵不是因为他们需要整个矩阵的值,而是仅仅需要其一小部分的值。
以上这四个例子展示了lazy evaluation的作用:能避免不必要的对象拷贝;能区别operator[]的读和写操作;能避免不必要的数据库读取操作;避免不需要的数学操作。但是它并不总是有用,实际上,如果你的计算都是必要的,lazy evaluation可能会减慢速度并增加内存的使用,因为除了进行所有的计算以外,还必须维护数据结构让lazy evaluation尽可能地在第一时间运行。
lazy evaluation能被运用于各种语言里,几种语言例如著名的APL、dialects of Lisp都把这种思想做为语言的一个基本部分。然而主流程序设计语言采用的是eager evaluation,C++是主流语言。不过C++特别适合用户实现lazy evaluation,因为它对封装的支持使得能在类里加入lazy evaluation,而根本不用让类的使用者知道。这就是说我们可以直接用eager evaluation方法来实现一个类,但是如果你通过profiler调查显示出类实现有一个性能瓶颈,就可以用使用lazy evaluation的类实现来替代它。
18:分期摊还预期的计算成本
所谓over-eagar evaluation(超前计算),是指超进度的做“要求以外”的更多工作,也就是在被要求之前就把事情做好。比如下面的代码:
template<class NumericalType>
class DataCollection {
public:
NumericalType min() const;
NumericalType max() const;
NumericalType avg() const;
...
};
有三种方法实现min, max, avg这三种函数:使用 eager evaluation,当 min,max 和 avg 函数被调用时,检测集合内所有的数值,然后返回一个合适的值;使用 lazy evaluation,令这些函数返回某些数据结构,用来在“这些函数的返回值真正需要用时”,才决定其适当返回值;使用 over-eager evaluation,随时记录目前集合的最小值,最大值和平均值,这样当 min,max 或 avg 被调用时,可以不用计算就立刻返回正确的数值,如果频繁调用 min,max 和 avg,这种方法能够分期摊还“随时记录集合最小、最大、平均值”的成本,而每次调用所需付出的成本(摊还后的),将比eager evaluation 或 lazy evaluation低。
over-eager evaluation背后的观念是:如果预期程序常常会用到某值,可以降低每次计算的平均成本,办法就是设计一份数据结构,以便能极有效率的处理需求。
over-eager evaluation最简单的一种做法是:将已经计算好而有可能再被需要的数值保存起来。比如:
int findCubicleNumber(const string& employeeName)
{
// 定义一个局部缓存,记录(employee name, cubicle number)
typedef map<string, int> CubicleMap;
static CubicleMap cubes;
// 尝试在cache中寻找employeeName,如果能找到,则it就指向该记录
CubicleMap::iterator it = cubes.find(employeeName);
// 如果cache中找不到,则查询数据库,然后将其记录到cache中
if (it == cubes.end()) {
int cubicle = the result of looking up employeeName’s cubicle
number in the database;
cubes[employeeName] = cubicle; // 记录到cache中
return cubicle;
}
else {
// cache中能找到,则直接返回对应的值
return (*it).second;
}
}
上面的代码使用局部缓存,将相对昂贵的数据库操作用以相对廉价的内存查找取代,如果上面的函数常被调用,则使用cache就可以降低平均成本。
over-eager evaluation还有一种做法是prefetching(预先取出),例如从磁盘读取数据时,读取整个数据块,即使当前只需要其中少量数据,因为一次读一大块数据要比分成两三次读取小数据快得多,而且,根据局部性原理,如果某处的数据被需要,通常其临近的数据也会被需要。
动态分配空间时,分配比需要量更大的内存,也属于prefetching的做法:
template<class T>
T& DynArray<T>::operator[](int index)
{
if (index < 0) throw an exception;
if (index > the current maximum index value) {
int diff = index - the current maximum index value;
call new to allocate enough additional memory so that
index+diff is valid;
}
return the indexth element of the array;
}
通常做法是,动态数组需要扩张时,每次分配两倍内存。
所谓over-eager evaluation,实际上就是以空间换时间。本条款和上一条款的lazy evaluation并不矛盾:当你必须支持某些操作而不总需要其结果时,lazy evaluation可以改善程序效率;当你必须支持某些操作而其结果几乎总是被需要或被不止一次地需要时,over-eager evaluation可以改善程序效率。
19:了解临时对象的来源
只要你产生一个non-heap 对象而没有为他命名,它就是一个临时对象。临时对象通常发生于两种情况:为了使函数成功调用而进行隐式类型转换时;当函数返回对象时。
下面是隐式类型转换的例子:
// 返回ch在str中出现的次数
size_t countChar(const string& str, char ch);
char buffer[MAX_STRING_LEN];
char c;
size_t res = countChar(buffer, c);
countChar接受的参数类型是const string&,但是实参是char数组,为了能调用成功,编译器以buffer为参数建立一个string类型的临时对象,countChar的参数str绑定到该临时对象上,当countChar返回时,临时对象自动释放。
从效率的观点来看,临时对象的构造和释放是不必要的开销。通常有两个方法可以消除它。一种是重新设计你的代码,不让发生这种类型转换,这种方法在条款05中被研究和分析。另一种方法是通过修改软件而不再需要类型转换,条款21讲述了如何去做。
注意,仅仅当通过by value或by reference-to-const接收参数时,才会发生这样的转换,当参数是reference-to-non-const时,就不会:
class Array {
public:
Array(int size)
{
printf("Array size is %d\n", size);
}
void fun() const
{
printf("this is Array::fun\n");
}
};
void fun(Array &ary) {
ary.fun();
}
fun(3);
上面的代码,fun的参数是reference-to-non-const,调用时传递的参数为int类型,编译报错:invalid initialization of non-const reference of type ‘Array&’ from an rvalue of type ‘Array’。
创建临时对象的第二种环境是函数返回对象时。比如:
const Number operator+(const Number& lhs, const Number& rhs);
这种情况下,如果不想付出临时对象创建的开销,可以利用编译器的返回值优化技术。
综上所述,临时对象是有开销的,所以应该尽可能地去除它们,然而更重要的是能找到可能建立临时对象的地方。在任何时候只要见到reference-to-const参数,就存在建立临时对象而绑定在参数上的可能性。在任何时候只要见到函数返回对象,就会有一个临时对象被建立。
20:协助完成返回值优化
参考《C++返回值优化》一文。
21:使用重载避免隐式类型转换
下面的代码,调用operator+完成UPInt的加法操作:
const UPInt operator+(const UPInt& lhs, const UPInt& rhs);
UPInt upi1, upi2;
UPInt upi3 = upi1 + upi2;
如果operator+的参数之一为int:
upi3 = upi1 + 10;
upi3 = 10 + upi2;
这种情况下,就会发生隐式类型转换,产生构造临时对象的开销。通过声明下面的函数,可以避免隐式类型转换:
const UPInt operator+(const UPInt& lhs, const UPInt& rhs);
const UPInt operator+(const UPInt& lhs, int rhs);
const UPInt operator+(int lhs, const UPInt& rhs);
这样就能支持UPInt和int类型的加法操作了。不过,必须谨记80-20规则:没有必要实现大量的重载函数,除非你有理由确信程序使用重载函数以后其整体效率会有显著的提高。
注意不要顺手声明下面的函数:
const UPInt operator+(int lhs, int rhs);
两个参数都是int,这是编译器不允许的,C++规定重载操作符,必须带有一个用户自定义类型的参数。
22:考虑用运算符的赋值形式(op=)实现其单独形式(op)
x=x+y也可以这样写:x += y。但是如果x和y是用户自定义的类型,就不能确保这样。operator+、operator=和operator+=之间没有任何关系,因此如果你想让这三个operator同时存在并具有你所期望的关系,就必须自己实现它们。
确保operator的赋值形式(如operator+=)与一个operator的单独形式(如operator+) 之间存在正常的关系,一种好方法是后者(operator+)根据前者(operator+=)来实现:
const Rational operator+(const Rational& lhs, const Rational& rhs)
{
return Rational(lhs) += rhs;
}
使用这种方法,只用维护operator的赋值形式就行了。而且如果operator赋值形式在类的public接口里,这就不用让operator的单独形式成为类的友元。
如果不介意把所有的operator的单独形式放在全局域里,就可以使用模板来替代单独形式的函数的编写:
template<class T>
const T operator+(const T& lhs, const T& rhs)
{
return T(lhs) += rhs;
}
使用该模板,只要为某种类型定义了operator赋值形式,一旦需要,其对应的operator单独形式就会被自动生成。
总的来说operator的赋值形式比其单独形式效率更高,因为单独形式要返回一个新对象,operator的赋值形式把结果写到左边的参数里,因此不需要生成临时对象来容纳operator的返回值。
做为一个库程序设计者,应该两者都提供,做为一个应用程序的开发者,在优先考虑性能时你应该考虑考虑用operator赋值形式实现其单独形式。
23:考虑使用其他程序库
程序库的设计就是一个折衷的过程。理想的程序库应该是短小的、快速的、强大的、灵活的、可扩展的、直观的、普遍适用的、具有良好的支持、没有使用约束、没有错误的。现实中这种库是不存在的。
不同的设计者面对这些规范给予不同的优先级,他们的设计各有取舍,因此很容易出现两个提供相同功能的程序库却有着完全不同的性能表现。比如iostream和stdio程序库,iostream程序库与C中的stdio相比有几个优点,它是类型安全的,它是可扩展的。然而在效率方面,iostream程序库总是不如stdio,stdio产生的可执行文件通常比iostream产生的可执行文件尺寸小而且执行速度快。
因此,一旦你找到软件的瓶颈,你应该考虑是否可能通过替换程序库来消除瓶颈。
24:了解虚函数,多继承,虚基类,运行时类型识别(RTTI)的成本
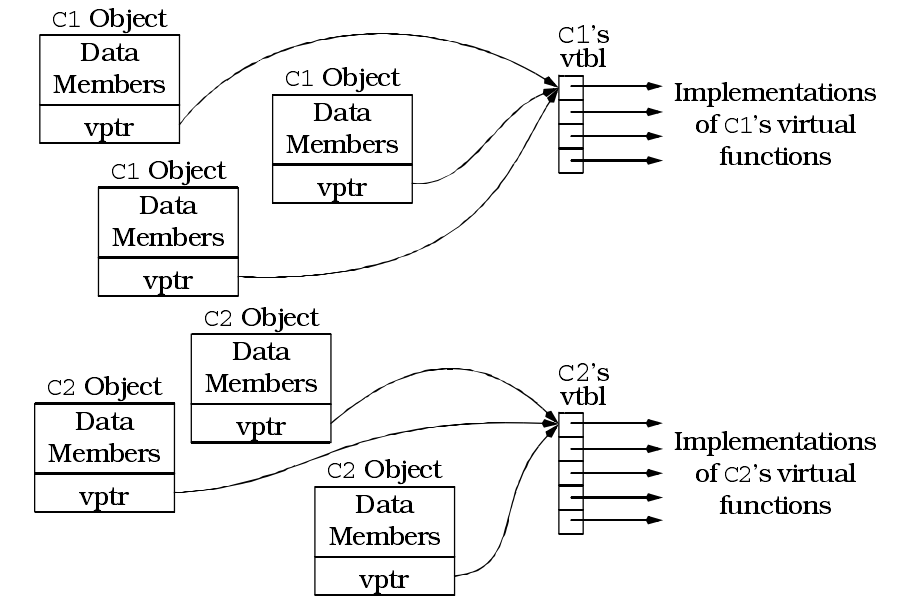
大部分编译器使用所谓的virtual table(vtbl)和virtual table pointer(vptr)来实现虚函数的动态绑定。
vtbl通常是一个函数指针数组。某个类只要声明了虚函数或继承了虚函数,它就有自己的vtbl,vtbl中的条目就是指向该类的各个虚函数实现体的指针。例如:
class C1 {
public:
C1();
virtual ~C1();
virtual void f1();
virtual int f2(char c) const;
virtual void f3(const string& s);
void f4() const;
...
};
class C2: public C1 {
public:
C2(); // 非虚函数
virtual ~C2(); // 重定义的虚函数
virtual void f1(); // 重定义的虚函函数
virtual void f5(char *str); // 新的虚函数
...
};
C1的vtbl看起来如下图所示:

C2的vtbl看起来如下图所示:

因此,包含虚函数的类要耗费一个vtbl的空间。其大小视虚函数的个数(包括从基类继承的虚函数)而定。
每个类应该只有一个vtbl,编译器必须解决一个问题:把它放在哪里。大多数程序和程序库由多个object文件连接而成,每个object文件之间是独立的。哪个object文件应该包含给定类的vtbl呢?
针对该问题,编译器厂商分成两个阵营。对于提供集成开发环境(包含编译程序和连接程序)的厂商,一种干脆的方法是为每一个需要vtbl的目标文件生成一个vtbl拷贝,最后由连接程序去除重复的拷贝,在最后的可执行文件或程序库中,只有一个vtbl实体。
更常见的设计是采用启发式算法来决定哪一个目标文件应该包含类的vtbl。通常做法是这样的:类的vtbl产生于“内含第一个non-inline, non-pure虚函数定义”的目标文件中。因此上述C1类的vtbl将被放置到包含C1::~C1定义的目标文件里(前提是该函数不是内联),C2类的vtbl被放到包含C1::~C2定义的目标文件里。这种启发式算法是可行的,但是如果在类中的所有虚函数都声明为内联函数,启发式算法就会失败,此时编译器会在使用它的每个目标文件中生成一个类的vtbl。在大型系统里,这会导致程序包含同一个类的成百上千个vtbl拷贝!
vtbl只是虚函数实现机制的一半而已,还需要virtual table pointer(vptr)指示出每个对象对应于哪一个vtbl。每个声明了虚函数的对象都带有一个隐藏的数据成员vtpr,用来指向类的vtbl。这就是实现虚函数所需的第二个代价:在每个包含虚函数的类的对象里,必须为额外的指针付出代价。
包含有虚函数的对象的布局可能是这样的,注意vptr不一定就位于对象的底部,不同的编译器放置它的位置也不同:

如果一个程序包含几个C1和C2对象,则如下图所示:
考虑这段这段程序代码:
void makeACall(C1 *pC1)
{
pC1->f1();
}
通过指针pC1调用虚拟函数f1。仅仅看这段代码,不会知道它调用的是那一个f1函数,因为pC1可以指向C1对象也可以指向C2对象。尽管如此编译器仍然得为在makeACall的f1函数的调用生成代码,它必须确保无论pC1指向什么对象,函数的调用必须正确。假设f1在vtbl中的索引为i,则pC1->f1()产生的代码将是:
//调用pC1->vptr指向的是vtbl中,第i个条目所指的函数,
//而pC1被做为this指针传递给函数
(*pC1->vptr[i])(pC1);
这几乎与调用非虚函数的效率相当。因此,调用虚函数所需的成本基本上与通过函数指针调用函数一样。虚函数本身通常不是性能的瓶颈。
虚函数真正的运行时成本发生在和inline互动的时候,实际上虚函数不能是内联的。因为“内联”是指“在编译期间用被调用的函数体本身来代替函数调用的指令”,而虚函数的“虚”是指“直到运行时才能知道要调用的是哪一个函数”。这就是虚函数的第三个代价:不能使用内联函数。
到现在为止我们讨论的东西适用于单继承和多继承,但是多继承的引入,事情就会变得更加复杂。多重继承情况下,单个对象里有多个vptr(因为派生类包含基类部分,每个基类对应一个vptr);而且除了我们已经讨论过的单独的自己的vtbl以外,还会针对基类生成特殊的vtbl。因此虚函数对每一个对象和每一个类所造成的的空间负担又增加了一些。
struct a { void foo(); }; // no need for virtual table
struct b : a { virtual foo1(); }; // need vtable, and vptr
struct c : b { void bar(); }; // no extra virtual table, 1 vptr (b) suffices
struct d : b { virtual bar(); }; // extra vtable, need b.vptr and d.vptr
struct e : d, b {}; // 3 vptr, 2 for the d subobject and one for
// the additional b
struct f : virtual b {};
struct g : virtual b {};
struct h : f, g {}; // single vptr, only b needs vtable and
// there is a single b
(https://stackoverflow.com/questions/3342035/how-many-vptr-will-a-object-of-classuses-single-multiple-inheritance-have)
多继承经常导致对虚基类的需求,虚基类的实现通常是使用指针,指向虚基类成分,以消除复制行为。因此对象内可能出现一个(或多个)这样的指针。比如下面的代码:

A是一个虚基类,因为B和C虚拟继承了它。使用一些编译器(特别是比较老的编译器),D对象会产生这样布局:
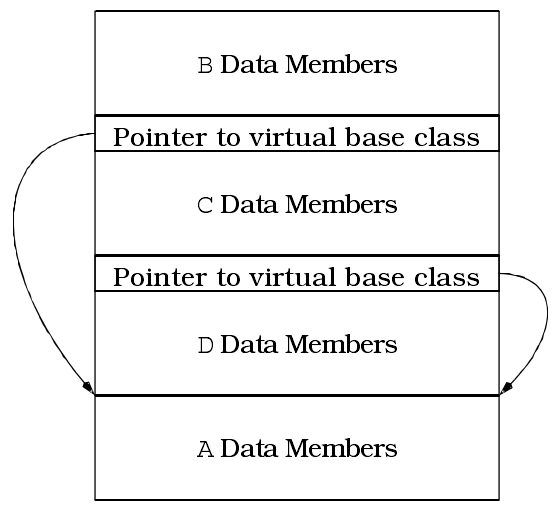
把基类的数据成员放在对象的最底端,这显得有些奇怪,但是它经常这么做。当然如何实现是编译器的自由。这幅图只是为了说明虚基类会导致对象需要额外的指针。
将上图和之前展示如何把virtual table pointer加入到对象里的图片合并起来,我们就会认识到如果在上述继承体系里的基类A有任何虚函数,对象D的内存布局就是这样的:
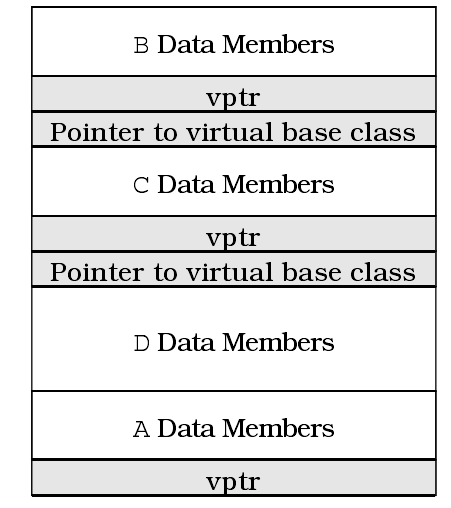
上图一个诡异之处在于:虽然涉及四个类,但只出现了三个vptr。三个已经足够了(它发现B和D能够共享一个vptr),大多数编译器会利用这个机会来减少额外负担。
最后看一下运行时类型识别(RTTI)。RTTI能让我们在运行时找到对象和类的有关信息,所以肯定有某个地方存储了这些信息。这些信息被存储在类型为type_info的对象里,可以通过typeid操作符访问一个类的type_info对象。
一个类只需要一个RTTI信息,实际上这叙述得不是很准确。C++语言规范上这样描述:只有当某种类型拥有至少一个虚函数时,才保证能够获得一个对象的动态类型信息。因此,RTTI信息听起来像vtbl,这种RTTI和vtbl之间的相似点并不是巧合:RTTI被设计为在类的vtbl基础上实现。
例如,vtbl数组的索引0处可以包含一个type_info对象的指针,这个对象属于该vtbl相对应的类。因此上述C1类的vtbl看上去象这样:

使用这种实现方法,RTTI耗费的空间只是在每个类的vtbl中增加一个条目,再加上每个类所需的一份type_info对象空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号