Python学习总结
1.学习python目的,了解
1.1 为什么要学python? -朋友推荐 -了解 - 简单易学 - 生态圈比较强大 - 发展趋势:人工智能、数据分析
1.2 谈谈你对Python(解释型语言、弱类型语言)和其他语言的区别? 一、编译型语言:一次性,将全部的程序编译成二进制文件,然后在运行。(c,c++ ,go) 优点:运行速度快。 缺点:开发效率低,不能跨平台。 二、解释型语言:当你的程序运行时,一行一行的解释,并运行。(python , PHP) 优点:调试代码很方便,开发效率高,并且可以跨平台。 缺点:运行速度慢。 混合型:(C#,Java) 开发效率非常高,Python有非常强大的第三方库 高级语言--Python语言编写程序的时候,无需考虑诸如如何管理你的程序使用的内存一类的底层细节 可移植性--Python程序无需修改就几乎可以在市场上所有的系统平台上运行 可扩展性--可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。 可嵌入性--可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。
2.基础
字符串
字符串是一个有序的字符的集合,用于存储和表示基本的文件信息
字符串特性:
1、只能存放一个值
2、不可变
3、按照从左到右的顺序定义字符集和,索引从0开始有序访问
定义方法:a='qwe'
字符串常用方法:


s1='abc ' s2='**********abc*******' print(s1.strip(' ')) print(s2.strip('*')) 输出结果: abc abc .capitalize() 首字母大写 s1='abcdef' print(s1.capitalize()) 执行结果 Abcdef .upper 所有字母大写 s1='abcdef' print(s1.upper()) 输出结果 ABCDEF .lower 所以字母小写 s1='ABCdef' print(s1.lower()) 输出结果 abcdef .center(30,'#') 宽度为30个字符,S1居中显示,不够30个用#补满 s1='ABCdef' print(s1.center(30,'#')) 输出结果 ############ABCdef############ .count('n') 统计某个字符出现了几次 s1='aaaABCdaaefaa' print(s1.count('a')) 输出结果 7 count('n',x,y) 统计x到y中有几个n s1='aaaABCdaaefaa' print(s1.count('a',0,8)) 输出结果 4 .endswith(‘x’) 判断是否以x结尾 s1='aaaABCdaaefaa' print(s1.endswith('a')) 执行结果 True .startswith(‘x’) 判断是否以x开头 s1='aaaABCdaaefaa' print(s1.startswith('b')) 执行结果 False #括号内的b换成a就会是True .find() 找出某个字母所在的值 s1='aaaABCdaaefaa' print(s1.find('C')) 执行结果 5 .format() 格式化字符串 msg1='Name:{},age:{},sex:{}' print(msg1) print(msg1.format('egon',18,'male')) msg2='Name:{0},age:{1},sex:{0}' print(msg2.format('aaaaaaaaaaaaaaaaa','bbbbbbbbbbbbbb')) msg3='Name:{x},age:{y},sex:{z}' print(msg3.format(y=18,x='egon',z='male')) 输出结果: Name:{},age:{},sex:{} Name:egon,age:18,sex:male Name:aaaaaaaaaaaaaaaaa,age:bbbbbbbbbbbbbb,sex:aaaaaaaaaaaaaaaaa Name:egon,age:18,sex:male .index(‘x’) 查看x在第几位 s1='aaaABCdaaefaa' print(s1.index('d')) 执行结果 6 .isdigit() 判断变量是不是数字 s1='aaaABCdaaefaa' print(s1.isdigit()) 执行结果 False #很显然S1不是数字,如果是数字执行结果会是True .replace() 替换字符 s1='aaaABCdaaefaa' print(s1.replace('a','G')) 执行结果 GGGABCdGGefGG #把a替换成G s1='aaaABCdaaefaa' print(s1.replace('a','G',2)) 执行结果 GGaABCdaaefaa #第二个数字指定a替换几次 复制代码 .split() 分割 msg='/etc/a.txt|365|get' print(msg.split('|')) 执行结果 ['/etc/a.txt', '365', 'get'] .islower() 判断字符串是否全部小写 s1='aaaABCdaaefaa' print(s1.islower()) 执行结果 False .isspace() 判断是否全都是空格 s2=' ' print(s2.isspace()) 执行结果 True .istitle() 判断首字母是否大写 s1='aaaABC' print(s1.istitle()) 执行结果 False .ljust(10,‘*’) 总共十个字符左对齐不够用*填充 s1='aaaABC' print(s1.ljust(10,'*')) 执行结果 aaaABC**** .rjust 相反,右对齐 执行结果****aaaABC
列表
特性:list中的元素可以随意删除增加且list的id和type不会改变,ist是一种可变类型.列表中的所有元素可以是 int 可以是 str 也可以是list(子列表).list中的值是有序的。
列表操作方法
定义列表:li = [11,22,33,44,55,66] 取值:通过索引 print (li[1]) 切片 li =[11,22,33,44,55,66] print(l[1:5]) 追加 li.append() 向后追加元素 插入 li.insert(1,‘SB’) 在指定索引的位置插入值 删除 li.pop() 移除最后一个值 a=.pop() 在原列表中移除掉最后一个元素并赋值给a 显示索引位置 li.index() 获取指定元素的索引位置 包含 print(11 in l) 其他 .count() 查看有元素出现的次数 .extend() 批量添加元素 .remove() 移除某个元素 .reverse() 把所有元素顺序倒过来,反转 .sort() 排序 del 列表名[1] 删除索引指向的元素 #字符串——>数字 int(字符串)
字典
{花括号} dict 可变类型,key不可变,value可变
#字典的常用方法 #定义字典 d={'x':1,'y':12222} #长度 len(d) #新增 d['x']=2 print(d) #遍历 print(d.items()) for item in d.items(): #[('x', 1), ('y', 12222)] print(item) #以元组的形式取出键值对 for k,v in d.items(): #解压键值对 print(k,v) print(d.keys()) # 获取所有的key print(d.values()) # 获取所有的values print(d.itmes()) #获取所有的元素 查找 print(d.get('y')) print(d.get('y','找不到')) print(d.get('e','找不到')) 删除键值对 d.pop('x') print(d) 随机删除键值对 print(d.popitem()) print(d) 清除元素 d.clear() print(d) #快速产生字典 d1={} d2=dict() d3=dict(x=1,y=2,z=3) d4=dict({'x':1,'y':2,'z':3}) d5=dict([('x',1),('y',2),('z',3)]) d6={}.fromkeys(['name','age'],None) #把key的值都设置成None,用于创建初始的字典 print(d1,d2,d3,d4,d5,d6) #更新字典元素,覆盖 d={'name':'alex'} d1={'name':'alexsb','age':50} d.update(d1) print(d)
元组
特性:元组内的所有元素不能更改,元素可以是任意数据类型
元组中可以包含list,元组中的list中的元素是可以更改的.当然list中也可以有元组.
定义元组 name_tuple = ('alex','eric') 索引 print(name_tuple[0]) len print(name_tuple[len(name_tuple)-1]) 切片 print(name_tuple[0:1]) for for i in name_tuple: print(i) count:计算元素出现的个数 print(name_tupel.count('alex')) index:获取指定元素的索引位置 print(name_tupel.index('alex'))
集合
作用:去重,关系运算
#定义集合: #集合内的元素必须的唯一的 #集合内的元素必须是可hash(不可变)的 #集合是无序的 s={'sam',123,'sam'} print(s,type(s)) #循环 s={'1',1,(1,2),'a'} for i in s: print(i) #关系运算 python_l={'egon','alex','铁蛋','老王'} linux_l={'alex','铁蛋','矮跟','欧德博爱'} #取共同部分:交集 print(python_l & linux_l) # #取老男孩所有报名学生:并集 print(python_l | linux_l) #取只报名了python和只报名了linux的学生:差集 print(python_l - linux_l) print(linux_l - python_l) # #取没有同时报名python和linux的学生:对称差集 print(python_l ^ linux_l) #集合方法 python_l={'egon','alex','铁蛋','老王'} linux_l={'alex','铁蛋','矮跟','欧德博爱'} print(python_l.difference(linux_l))#python -linux print(python_l.intersection(linux_l))#交集 print(python_l.union(linux_l))#并集 print(python_l.symmetric_difference(linux_l))#对称差集 python_l={'egon','alex','铁蛋','老王'} linux_l={'alex','铁蛋','矮跟','欧德博爱'} python_l.difference_update(linux_l) print(python_l) #对称差集并更新 s1={'a',1} s2={'a','b',2} s1.update(s2) print(s1) #把S2的内容更新到S1里 s1={1,2} s2={1,2,3} print(s1.issubset(s2))#子集 print(s2.issuperset(s1))#父集 s1={'a',1} s1.add(1) print(s1) #添加元素,元素存在不修改 s1.discard('a') #删除元素,元素不存在也不报错 s1.discard('b') print(s1) s1.remove('nnnnnn') #删除元素,元素不存在就报错 print(s1) s1={'a',1,'b','c','d'} print(s1.pop()) #.pop随机删除 print(s1) s1={1,2,'a'} s2={1,2,3} print(s1.intersection(s2)) #判断是否有交集,有则返回值 print(s1.isdisjoint(s2)) #判断是否没有交集,有则返回False s1={'a','b'} s2={'c','d'} print(s1.isdisjoint(s2)) #没有交集返回True
深浅拷贝
在Python中对象的赋值其实就是对象的引用。当创建一个对象,把它赋值给另一个变量的时候,python并没有拷贝这个对象,只是拷贝了这个对象的引用而已。
浅拷贝:拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已。也就是,把对象复制一遍,但是该对象中引用的其他对象我不复制
深拷贝:外围和内部元素都进行了拷贝对象本身,而不是引用。也就是,把对象复制一遍,并且该对象中引用的其他对象我也复制。
###############################
浅拷贝copy ,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,与原内存地址不变。
l1 = [1,[22,33,44],3,4,] l2 = l1.copy() l1[1].append('55') print(l1,id(l1),id(l1[1])) #[1, [22, 33, 44, '55'], 3, 4] 1787518244744 1787518244808 print(l2,id(l2),id(l2[1])) #[1, [22, 33, 44, '55'], 3, 4] 1787518244616 1787518244808 ############ l1[1].append("cao") print(l1) #[1, [22, 33, 44, '55', 'cao'], 3, 4] print(l2) #[1, [22, 33, 44, '55', 'cao'], 3, 4] ######################### l1[0] = "chao" print(l1) #['chao', [22, 33, 44, '55'], 3, 4] print(l2) #[1, [22, 33, 44, '55'], 3, 4]
深拷贝deepcopy,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变。
import copy l1 = [1,[22,33,44],3,4,] l2 = copy.deepcopy(l1) print(id(l1[1])) print(id(l2[1])) print("="*20) l1[0] = 111 print(l1) print(l2) print("="*20) l1[1].append('barry') print(l1) print(l2) ############ 1742824920520 ==================== [111, [22, 33, 44], 3, 4] [1, [22, 33, 44], 3, 4] ==================== [111, [22, 33, 44, 'barry'], 3, 4] [1, [22, 33, 44], 3, 4]
函数
函数的优点:1.代码重用
2.保持一致性,易于维护
3.可扩展性好

lambda表达式:
例

闭包
def foo(): m=3 n=5 def bar(): a=4 return m+n+a return bar >>>bar = foo() >>>bar() 说明: bar在foo函数的代码块中定义。我们称bar是foo的内部函数。 在bar的局部作用域中可以直接访问foo局部作用域中定义的m、n变量。 简单的说,这种内部函数可以使用外部函数变量的行为,就叫闭包。 闭包的意义与应用:延迟计算: 闭包的意义:返回的函数对象,不仅仅是一个函数对象,在该函数外还包裹了一层作用域,这使得,该函数无论在何处调用,优先使用自己外层包裹的作用域 #应用领域:延迟计算(原来我们是传参,现在我们是包起来) 装饰器就是闭包函数的一种应用场景
常见内置函数:
- map - filter
map()函数接收两个参数,一个是函数,一个是可迭代对象,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。 def mul(x): return x*x n=[1,2,3,4,5] res=list(map(mul,n)) print(res) #[1, 4, 9, 16, 25] filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False, filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。 def is_odd(x): return x % 2 == 1 v=list(filter(is_odd, [1, 4, 6, 7, 9, 12, 17])) print(v) #[1, 7, 9, 17]
- zip
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。 >>>a = [1,2,3] >>> b = [4,5,6] >>> c = [4,5,6,7,8] >>> zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)] >>> zip(a,c) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] >>> zip(*zipped) # 与 zip 相反,可理解为解压,返回二维矩阵式 [(1, 2, 3), (4, 5, 6)]
- reduce
reduce() 函数会对参数序列中元素进行累积。 用传给reduce中的函数 function(有两个参数)先对集合中的第1、2个元素进行操作,得到的结果再与第三个数据用function函数运算,最后得到一个结果。 >>>def add(x, y) : # 两数相加 ... return x + y ... >>> reduce(add, [1,2,3,4,5]) # 计算列表和:1+2+3+4+5 >>> reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数
装饰器
什么是装饰器及作用?
在不改变原函数的基础上,对函数执行前后进行自定义操作。

迭代器
内部实现__next__方法,帮助我们向后一个一个取值。
可迭代对象:一个类中内部实现__iter__方法,且返回一个迭代器

生成器
生成器:一个函数调用时返回一个迭代器,或 函数中包含yield语法,那这个函数就会变成生成器

偏函数
偏函数: import functools def func(a1, a2, a3): return a1 + a2 + a3 new_func = functools.partial(func, 11, 2) #将11,2依次传入到func函数的前两个参数 print(new_func(3)) 应用场景 falsk中取值时 通过localproxy 、偏函数、localstack、local
3.面向对象
python中一切皆对象,函数也是对象,类也是对象。
三大特性:
继承:
将多个类共用的方法提取到父类中,子类仅需继承父类,而不必一一实现每个方法。
封装:
多态:
多态:是指基类的同一方法在不同的派生类对象中具有不同的表现和行为。
Python不崇尚多态,因为自带多态,崇尚鸭子类型
双下划线方法:
1、__init__: 在类实例化成对象时,会首先调用__init__方法。 __init__的返回值一定要是None 2、__new__: __new__方法是在一个对象实例化的时候调用的第一个方法,不过一般都是用python默认的一般很少重写,只有当继承的类是一个不可变类型的时候才会去重写,__new__方法,第一个参数是这个类(cls)。 这个方法需要返回一个实例对象,通常是cls实例化的对象,也可以是其他的。 3.__del__: 当对象将要被销毁的时候该方法就会被调用。 4.__dict__: python中__dict__存储了该对象的一些属性。是一个字典,键为属性名,值为属性值。类和实例分别拥有自己的__dict__,且实例会共享类的__dict__。在__init__中,self.xxx = xxx会把变量存在实例的__dict__中,仅会在该实例中能获取到,而在方法体外声明的,会在class的__dict__中。 5.__dir__: __dict__与dir()的区别: dir()是一个函数,返回的是list。dir()用来寻找一个对象的所有属性,包括__dict__中的属性,__dict__是dir()的子集;并不是所有对象都拥有__dict__属性。许多内建类型就没有__dict__属性,如list,此时就需要用dir()来列出对象的所有属性。 6、__getitem__(self,key): 返回键对应的值。 print(obj.["xxx"]) 7、__setitem__(self,key,value): 设置给定键的值 obj.["xxx"]=123 8、__delitem__(self,key): 删除给定键对应的元素。 9、__len__(): 返回元素的数量 10.__setattr__ 如果类自定义了__setattr__方法,当通过实例获取属性尝试赋值时,就会调用__setattr__。常规的对实例属性赋值,被赋值的属性和值会存入实例属性字典__dict__中。 12、__getattr__:实例instance(类名)通过instance.name访问属性name,__getattr__方法一直会被调用,无论属性name是否存在。找不到回去调用父类的__getattr__,如果当前类还定义了__getattr__方法,除非通过__getattr__显式的调用它,或者__getattr__方法出现AttributeError错误,否则__getattr__方法不会被调用了。如果在__getattr__方法下存在通过self.attr访问属性,会出现无限递归错误。类中中定义了__getattr__方法,实例instance获取属性时,都会调用__getattr__返回结果,即使是访问__dict__属性。 13、__call__: __call__方法用于实例自身的调用: 14、__str__: 用来返回对象的字符串表达式。 15、__mro__: 16、 - metaclass - 作用:用于指定使用哪个类来创建当前类 - 场景:在类创建之前定制操作 示例:wtforms中,对字段进行排序。 查看当前类继承了哪些类。
⾯向对象深度优先和广度优先是什么?
Python的类可以继承多个类,Python的类如果继承了多个类,那么其寻找方法的方式有两种
当类是经典类时,多继承情况下,会按照深度优先方式查找
当类是新式类时,多继承情况下,会按照广度优先方式查找
简单点说就是:经典类是纵向查找,新式类是横向查找
经典类和新式类的区别就是,在声明类的时候,新式类需要加上object关键字。在python3中默认全是新式类
什么是函数什么是方法
from types import MethodType,FunctionType class Foo(object): def fetch(self): pass Foo.fetch 此时fetch为函数 print(isinstance(Foo.fetch,MethodType)) print(isinstance(Foo.fetch,FunctionType)) # True obj = Foo() obj.fetch 此时fetch为方法 print(isinstance(obj.fetch,MethodType)) # True print(isinstance(obj.fetch,FunctionType))
4.模块
你常用的模块?
- re/json/logging/os/sys
- requests/beautifulsoup4
5.re正则
. 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线 \s 匹配任意的空白符 \d 匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 \b 匹配一个单词的结尾 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配非字母或数字或下划线 \D 匹配非数字 \S 匹配非空白符 a|b 匹配字符a或字符b () 匹配括号内的表达式,也表示一个组 [...] 匹配字符组中的字符 [^...] 匹配除了字符组中字符的所有字符 用法说明 * 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次
- 写一个常见正则:邮箱/手机号/IP
#匹配手机号 import re def phone(arg): s=re.match("^(13|14|15|18)[0-9]{9}$",arg) if s: return "正确" return "错误" print(phone("23722751552")) #匹配邮箱 re.match("^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$",arg) #匹配IP re.match("\b(?:(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\b",arg) ?: 优先匹配 \b 匹配一个单词的结尾
-match和search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
re.search匹配整个字符串,直到找到一个匹配。
import re s="fnfffidvvgf" m=re.match("fi",s) print(m) #None s=re.search("fi",s).group() print(s) #fi
-贪婪匹配与非贪婪匹配
贪婪匹配: 匹配1次或多次<.+> 匹配0次或多次<.*>
非贪婪匹配:匹配0次或1次<.?>
6.给出路径找文件
方法一: 使用os.walk file-- 是你所要便利的目录的地址, 返回的是一个三元组(root,dirs,files)。 root 所指的是当前正在遍历的这个文件夹的本身的地址 dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录) files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录) def open_2(file): for root, dirs , files in os.walk(file): print("ss",files) for filename in files: print(os.path.abspath(os.path.join(root, filename))) #返回绝对路径 open_2("F:\搜索") 方法二: import os def open(files): for dir_file in os.listdir(files): # print("ss",dir_file) #递归获取所有文件夹和文件 files_dir_file = os.path.join(files, dir_file) if os.path.isdir(files_dir_file): #是不是文件夹 open(files_dir_file) else: print(files_dir_file) open("F:\搜索") 并将下面的所有文件内容写入到一个文件中 def open_2(file): for root, dirs , files in os.walk(file): for filename in files: with open(os.path.abspath(os.path.join(root, filename)), "r") as f: for i in f.readlines(): print(i) with open("./cao.txt","a",encoding="utf-8") as f2: f2.write(i) f2.write("\n") open_2("F:\搜索") 示例
创建删除文件
1 # 创建一个文件 2 open("chao.txt","w",encoding="utf-8") 3 import os #删除文件 4 os.remove("chao.txt")
第三方软件安装:
- pip包管理器
- 源码安装
- 下载
- 解压
- python setup.py build
- python setup.py install
7.网络编程
OSI 7层协议
互联网协议按照功能不同分为osi七层或tcp/ip五层或tcp/ip四层
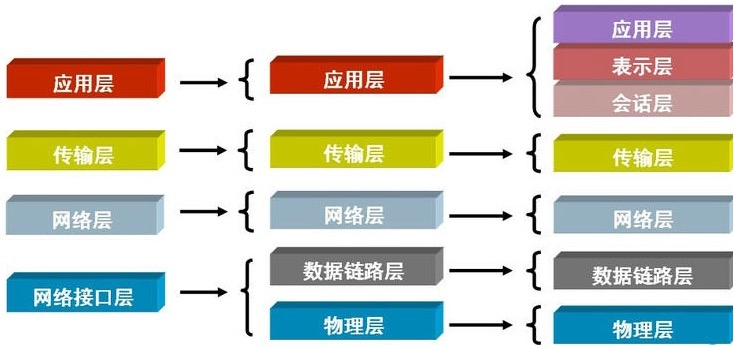
物理层:主要是基于电器特性发送高低电压(电信号),高电压1,低电压0,设备有集线器,中继器,双绞线等! 单位:bit比特
数据链路层:定义了电信号的分组方式 设备有:网桥、以太网交换机、网卡 单位:帧
网络层:主要功能是将网络地址翻译成对应的物理地址 路由
传输层:建立端口到端口之间的通信 tcp协议udp协议
会话层:建立客户端与服务端连接
表示层:对来自应用层的命令和数据进行解释,并按照一定的格式传送给会话层。如编码、 数据格式转换和加密解密,压缩解压缩"等
应用层:规定应用程序的数据格式
进程、线程、协程区别?
进程:正在执行的一个程序或者一个任务,而执行任务的是cpu 每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大, 相比线程数据相对比较稳定安全。 线程:线程是进程的一个实体,是CPU调度和分派的基本单位 线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。 协程:是一种“微线程”,实际并不存在,是程序员人为创造出来的控制程序调度的(程序执行一段代码,切换执行另一段代码) 它可以实现单线程下的并发、 1、程序执行遇到IO切换,性能提高,实现了并发 2、无IO时切换,性能降低 优点: 1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级 2. 单线程内就可以实现并发的效果,最大限度地利用cpu 1、进程多与线程比较 1) 地址空间:线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,而进程有自己独立的地址空间 2) 资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源 3) 线程是处理器调度的基本单位,但进程不是 4) 二者均可并发执行 5) 每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制 2、协程多与线程进行比较 1) 一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。 2) 线程进程都是同步机制,而协程则是异步 3) 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
进程池和线程池
进程池
from concurrent.futures import ProcessPoolExecutor import time,os def piao(name,n): print('%s '%(name)) time.sleep(2) return n**3 if __name__=='__main__': p = ProcessPoolExecutor(4) objs= [] for i in range(10): obj = p.submit(piao,'sb %s'%i,i) objs.append(obj) p.shutdown(wait=True) print("主",os.getpid()) for obj in objs: print(obj.result()) 异步调用
from concurrent.futures import ProcessPoolExecutor import time,os def piao(name,n): print('%s is pioing %s'%(name,os.getpid())) return n**2 if __name__=='__main__': p = ProcessPoolExecutor(4) for i in range(10): res = p.submit(piao,'alex %s'%i,i).result() print(res) p.shutdown(wait=True) print('主',os.getpid()) 同步调用
线程池
from concurrent.futures import ThreadPoolExecutor from threading import current_thread import time,random def task(n): print('%s is running' %current_thread().getName()) time.sleep(random.randint(1,3)) return n**2 if __name__ == '__main__': # t=ProcessPoolExecutor() #默认是cpu的核数 # import os # print(os.cpu_count()) t=ThreadPoolExecutor(3) #默认是cpu的核数*5 objs=[] for i in range(10): obj=t.submit(task,i) objs.append(obj) t.shutdown(wait=True) for obj in objs: print(obj.result()) print('主',current_thread().getName())
IO多路复用:
监听多个socket是否发生变化
HTTP协议本质?
建立在TCP协议之上,这个协议规定了请求头和请求体直接通过\r\n \r\n分割,无状态,短链接
TCP和UDP
tcp是基于连接的,必须先启动服务端,然后再启动客户端去连接服务端
udp是无连接的,先启动哪一端都可以 (应用:QQ聊天)
三次握手,四次挥手:
SYC=1(建立连接) ACK(确认请求)
1、客户端(Client)向服务端(Server)发一次请求(SYN=1,随机产生一个值seq=J)
2、服务端确认并回复客户端(ACK=1, SYC=1,并在seq基础上产生一个随机数发给客户端)
3、客户端检验确认请求(ACK=1) 此时客户端与服务端就建立了连接
四次挥手:
FAN=1(断连接) ACK=1(确认请求)
1、客户端向服务端发一次请求(FAN=1)
2、服务端回复客户端 (ACK=1) (断开客户端—>服务端)
3、服务端再向客户端发请求(FAN=1) (因为有数据传输,所以2、3不能合并)
4、客户端确认请求(ACK=1) (断开服务端--->客户端)
-GIL锁?
GIL互斥锁,将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
-进程池和线程池?
.....
8.数据库
1.引擎
innodb 支持事务(回滚)、表锁、行锁(select id,name from user where id=2 for update) myisam 支持全文索引、表锁(- select * from user for update)
2.设计表
权限表、BBS、权限
注意:FK M2M
3.数据操作
多表联查: select * from tb1,tb2 没有where条件时,笛卡尔乘积效果 left join 以左表为基准,显示所有的内容,右表没有对应项时,显示null select * from tb1 left join tb2 on tb1.id=tb2.id; inner join 只显示两张表共同内容 select * from tb1 inner join tb2 on tb1.id=tb2.id; union 显示两张表所有内容 select * from tb1 left join tb2 on tb1.id=tb2.id union select * from tb2 left join tb1 on tb1.id=tb2.id; 分组函数 select 部门ID,max(id) from 用户表 group by 部门ID having count(id)>3 group by 字段 having 判断条件 (固定语法)分组和聚合函数搭配
4.索引
创建表+索引 create table tb( id int not null primary key name varchar(32), pwd varchar(32) unique tb_pwd (pwd)) 普通索引:create index tb_name on tb(name) 联合索引:create index tb_name_age on tb(name,age)
原理:B+/哈希索引 查找速度快;更新速度慢
1、索引一定是为搜索条件的字段创建的 2、innodb表的索引会存放于s1.ibd文件中,而myisam表的索引则会有单独的索引文件table1.MYI 单列: 1、普通索引 index 加速查找 2、唯一索引 unique 加速查找+不能重复 3、主键索引 primary key 加速查找+不能重复+不能为空 多列: 1、联合索引 2、联合唯一索引 3、联合主键索引 联合索引遵从最左前缀原则 如果组合索引为:(name,email) name and email -- 使用索引 name -- 使用索引 email -- 不使用索引 其它操作: 索引合并:利用多个单例索引查找 覆盖索引:在索引表中就能查到想要的数据
创建了索引,但无法命中
- like '%xx' select * from tb1 where name like '%cn'; - 使用函数 select * from tb1 where reverse(name) = 'wupeiqi'; - or select * from tb1 where nid = 1 or email = 'seven@live.com'; 特别的:当or条件中有未建立索引的列才失效,以下会走索引 select * from tb1 where nid = 1 or name = 'seven'; select * from tb1 where nid = 1 or email = 'seven@live.com' and name = 'alex' - 类型不一致 如果列是字符串类型,传入条件是必须用引号引起来,不然... select * from tb1 where name = 999; - != select * from tb1 where name != 'alex' 特别的:如果是主键,则还是会走索引 select * from tb1 where nid != 123 - > select * from tb1 where name > 'alex' 特别的:如果是主键或索引是整数类型,则还是会走索引 select * from tb1 where nid > 123 select * from tb1 where num > 123 - order by select email from tb1 order by name desc; 当根据索引排序时候,选择的映射如果不是索引,则不走索引 特别的:如果对主键排序,则还是走索引: select * from tb1 order by nid desc;
存储过程、视图、函数、触发器
存储过程、视图、函数、触发器、都是保存在数据库中
触发器:在数据库中对某张表进行“增删改”时,添加一些操作
视图:一张虚拟表,根据SQL语句动态的获取数据集,并命名,下次使用时直接调用名称(只能查)
v = select * from tb where id <1000 select * from v 等同于: select * from (select * from tb where id <1000) as v
存储过程:将常用的sql语句命名保存到数据库中,使用时可以直接调用名称
参数有:in(入参类型) out(出参类型) inout(出入参类型)
函数:在sql语句中使用
- 聚合:max/sum/min/avg
- 时间格式化 date_format
- 字符串拼接 concat
存储过程与函数的区别:
区别: 函数 存储过程 必须有返回值 return 可以通过out、inout返回零各或多个值 不能单独使用,必须作为表达式的一部分 可以作为一个独立的sql语句执行 sql语句中可以直接调用函数 sql中不能调用过程
分页
select * form tb limit 10 offset 0
数据量过大,页数越大,查询速度越慢,因为页数越大,数据id就越大,查询时就会从头开始扫描数据,
解决办法:
方案一: 1、记录当期页,数据ID的最大值、最小值, 2、翻页查询时,先根据数据ID筛选数据,在limit查询 select * from (select * from tb where id > 22222222) as B limit 10 offset 0 如果用户自己修改url上的页码,我们可以参考rest-frameword中的分页,对url中的页码进行加密处理 方案二: 可以根据实际业务需求,只展示部分数据(只显示200-300页的数据)
慢日志查询
slow_query_log = ON 是否开启慢日志记录 long_query_time = 2 时间限制,超过此时间,则记录 slow_query_log_file = /usr/slow.log 日志文件 log_queries_not_using_indexes = ON 为使用索引的搜索是否记录
数据库导入导出
导入:mysqldump -u root -p db > F:\db.txt
导出:mysqldump -u root -p db < F:\db.txt;
执行计划
explain select * from tb; #查看sql语句执行速度
优化
- 不用 select * - 固定长度字段列,往前放 - char(固定长度)和varchar - 固定数据放入内存:choice
- 索引遵循最左前缀 - 读写分离,利用数据库的主从进行分离:主,用于删除、修改更新;从,查。 - 分库,当数据库中表太多,将表分到不同的数据库;例如:1w张表 - 分表 - 水平分表,将某些列拆分到另外一张表;例如:博客+博客详细 - 垂直分表,将历史信息分到另外一张表中;例如:账单 - 缓存:利用redis、memcache,将常用的数据放入缓存中 -查询一条数据 select * from tb where name='alex' limit 1 -text类型 为前面几个字符串创建索引
9.栈
class Stack(): def __init__(self,size): self.size=size self.stack=[] def getstack(self): """ #获取栈当前数据 :return: """ return self.stack def __str__(self): return str(self.stack) def top(self,x): # 入栈之前检查栈是否已满 if self.isfull(): raise Exception("stack is full") else: self.stack.append(x) def pop(self): """ # 出栈之前检查栈是否已空 :return: """ if self.isempty(): raise Exception("stack is empty") else: self.stack.pop() def isfull(self): """ 判断栈满 :return: """ if len(self.stack)==self.size: return True return False def isempty(self): """ 判断栈空 :return: """ if len(self.stack)==0: return True return False if __name__ == '__main__' : stack=Stack(4) for i in range(11): stack.top(i) print(stack.getstack()) for i in range(3): stack.pop() print(stack.getstack())
10.爬虫相关
- request/bs4
- requests模块
- 参数:
- url
- headers
- cookies
- data
- json
- params
- proxy
- 返回值:
- content
- iter_content
- text
- encoding="utf-8"
- cookie.get_dict()
- bs4
- 解析:html.parser -> lxml
- find
- find_all
- text
- attrs
- get
- 其他:
常见请求头:
- user-agent
- host
- referer
- cookie
- content-type
套路:
- 先给你cookie,然后再给你授权。
- 凭证
轮询+长轮询
- scrapy
- 高性能相关,单线程并发发送Http请求
- twisted
- gevent
- asyncio
本质:基于IO多路复用+非阻塞的socket客户端实现
问题:异步非阻塞?
问题:什么是协程?
- scrapy框架
- scrapy执行流程(包含所有组件)
- 记录爬虫爬取数据深度(层级),request.meta['depth']
- 传递cookie
- 手动
- 自动:meta={'cookiejar':True}
- 起始URL
- 持久化:pipelines/items
- 去重
- 调度器
- 中间件
- 下载中间件
- agent
- proxy
- 爬虫中间件
- depth
- 扩展+信号
- 自定义命令
- scrapy-redis组件,本质:去重、调度器任务、pipeline、起始URL放到redis中。
- 去重,使用的redis的集合。
- 调度器,
- redis列表
- 先进先出队列
- 后进先出栈
- redis有序集合
- 优先级队列
PS:深度和广度优先
- pipelines
- redis列表
- 起始URL
- redis列表
- redis集合
补充:
自定义encoder实现序列化时间等特殊类型:
json.dumps(xx,cls=MyEncoder)
- scrapy
----------------------整理中----------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号