深度学习分布式模型
背景
随着各大企业和研究机构在PyTorch、TensorFlow、Keras、MXNet等深度学习框架上面训练模型越来越多,项目的数据和计算能力需求急剧增加。在大部分的情况下,模型是可以在单个或多个GPU平台的服务器上运行的,但随着数据集的增加和训练时间的增长,有些训练需要耗费数天甚至数周的时间,我们拿COCO和Google最近Release出来的Open Image dataset v4来做比较,训练一个resnet152的检测模型,在COCO上大概需要40个小时,而在OIDV4上大概需要40天,这还是在各种超参数正确的情况下,如果加上调试的时间,可能一个模型调完就该过年了吧。单张CPU卡、或者单台服务器上的多张GPU卡,已经远远不能够满足内部训练任务的需求。因此,分布式训练的效率,即使用多台服务器协同进行训练,现在成为了深度学习系统的核心竞争力。
一、分布式训练系统架构
分布式训练系统架构主要有两种:
- Parameter Server Architecture(就是常见的PS架构,参数服务器)
- Ring-allreduce Architecture
![]()
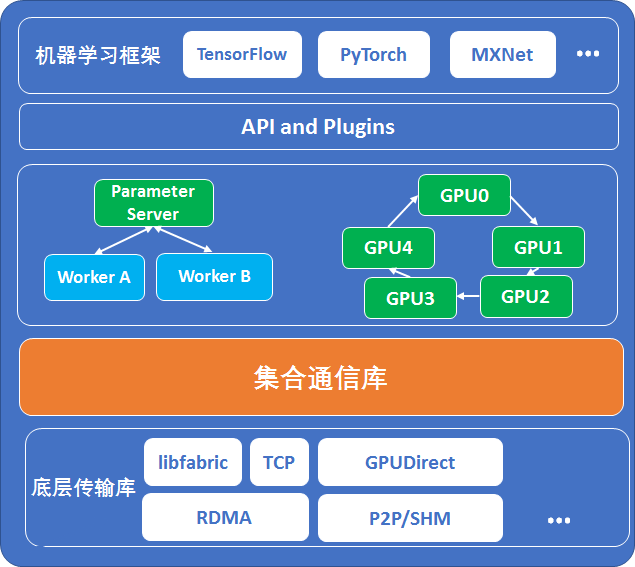
1.1 Parameter Server架构
在Parameter Server架构(PS架构)中,集群中的节点被分为两类:parameter server和worker。其中parameter server存放模型的参数,而worker负责计算参数的梯度。在每个迭代过程,worker从parameter sever中获得参数,然后将计算的梯度返回给parameter server,parameter server聚合从worker传回的梯度,然后更新参数,并将新的参数广播给worker。见下图的左边部分。
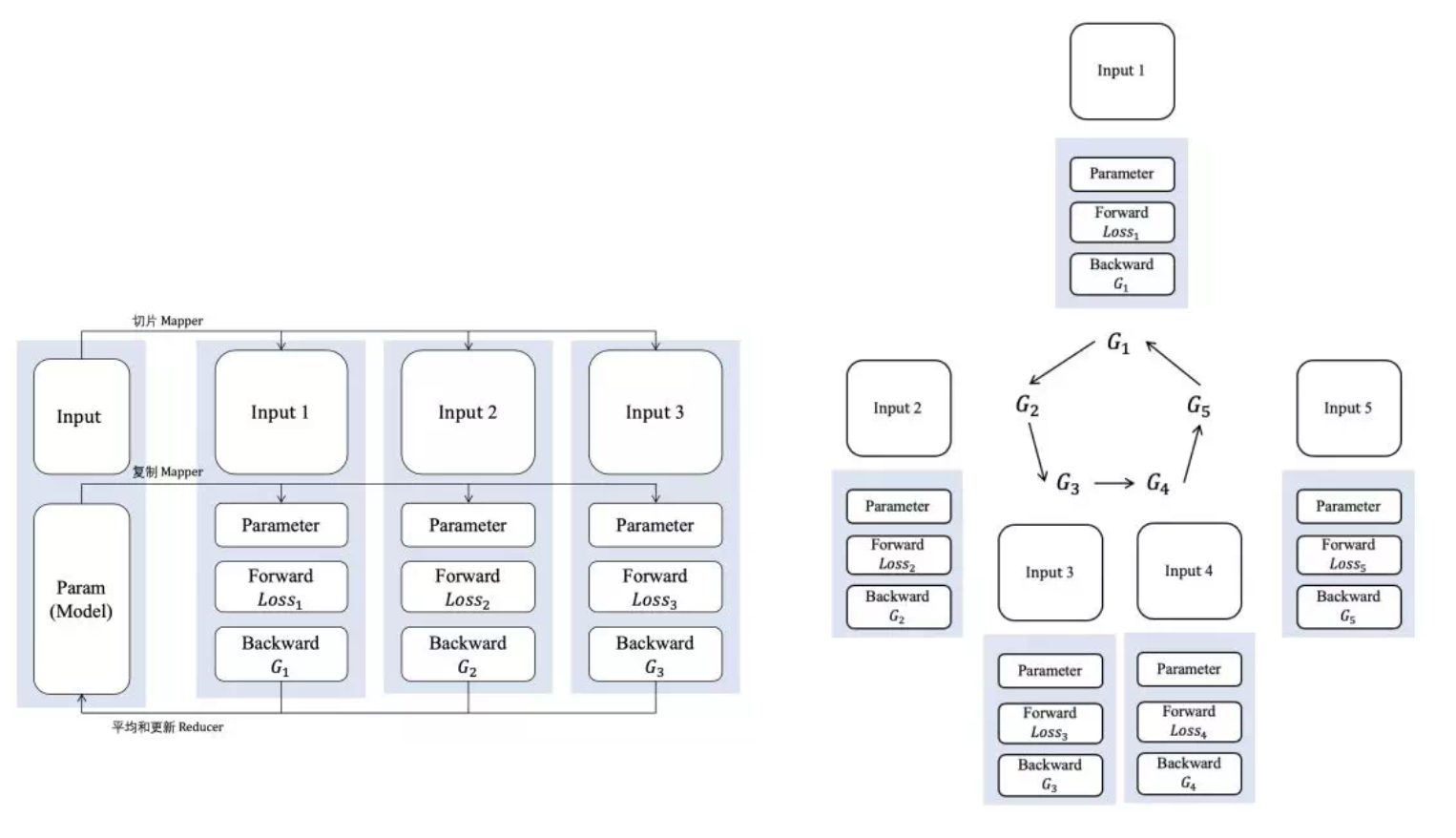
1.2 Ring-allreduce架构
在Ring-allreduce架构中,各个设备都是worker,并且形成一个环,如上图所示,没有中心节点来聚合所有worker计算的梯度。在一个迭代过程,每个worker完成自己的mini-batch训练,计算出梯度,并将梯度传递给环中的下一个worker,同时它也接收从上一个worker的梯度。对于一个包含N个worker的环,各个worker需要收到其它N-1个worker的梯度后就可以更新模型参数。其实这个过程需要两个部分:scatter-reduce和allgather,百度开发了自己的allreduce框架,并将其用在了深度学习的分布式训练中。
相比PS架构,Ring-allreduce架构有如下优点:
- 带宽优化,因为集群中每个节点的带宽都被充分利用。而PS架构,所有的worker计算节点都需要聚合给parameter server,这会造成一种通信瓶颈。parameter server的带宽瓶颈会影响整个系统性能,随着worker数量的增加,其加速比会迅速的恶化。
- 此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。在百度的实验中,他们发现训练速度基本上线性正比于GPUs数目(worker数)。
二、通用机器学习框架对分布式模型的支持
2.1 Tensorflow原生PS架构
通过TensorFlow原生的PS-Worker架构可以采用分布式训练进而提升我们的训练效果,但是实际应用起来并不轻松:
- 概念多,学习曲线陡峭:tensorflow的集群采用的是parameter server架构,因此引入了比较多复杂概念
- 修改的代码量大:如果想把单机单卡的模型,移植到多机多卡,涉及的代码量是以天记的,慢的话甚至需要一周。
- 需要多台机子跑不同的脚本:tensorflow集群是采用parameter server架构的,要想跑多机多卡的集群,每个机子都要启动一个client,即跑一个脚本,来启动训练,100个机子,人就要崩溃了。
- ps和worker的比例不好选取:tensorflow集群要将服务器分为ps和worker两种job类型,ps设置多少性能最近并没有确定的计算公式。
- 性能损失较大:tensorflow的集群性能并不好,当超过一定规模时,性能甚至会掉到理想性能的一半以下。
2.2 Pytorch分布式简介
PyTorch用1.0稳定版本开始,torch.distributed软件包和torch.nn.parallel.DistributedDataParallel模块由全新的、重新设计的分布式库提供支持。 新的库的主要亮点有:
- 新的 torch.distributed 是性能驱动的,并且对所有后端 (Gloo,NCCL 和 MPI) 完全异步操作
- 显着的分布式数据并行性能改进,尤其适用于网络较慢的主机,如基于以太网的主机
- 为torch.distributed package中的所有分布式集合操作添加异步支持
- 在Gloo后端添加以下CPU操作:send,recv,reduce,all_gather,gather,scatter
- 在NCCL后端添加barrier操作
- 为NCCL后端添加new_group支持
1.0的多机多卡的计算模型并没有采用主流的Parameter Server结构,而是直接用了Uber Horovod的形式,也是百度开源的RingAllReduce算法。
2.3 分布式Horovod介绍
Horovod 是一套支持TensorFlow, Keras, PyTorch, and Apache MXNet 的分布式训练框架,由 Uber 构建并开源,Horovod 的主要主要有两个优点:
- 采用Ring-Allreduce算法,提高分布式设备的效率;
- 代码改动少,能够简化分布式深度学习项目的启动与运行。
Horovod 是一个兼容主流计算框架的分布式机器学习训练框架,主要基于的算法是 AllReduce。 使用 horovod 有一定的侵入性,代码需要一定的修改才能变成适配分布式训练,但是有一个好处就是适配的成本不高,并且 horovod 提供的各种框架的支持可以让 horovod 比较好的在各个框架的基础上使用,他支持 tensorflow/keras/mxnet/pytorch,MPI 的实现也有很多,比如 OpenMPI 还有 Nvidia 的 NCCL,还有 facebook 的 gloo,他们都实现了一种并行计算的通信和计算方式。而且 horovod 的本身的实现也很简单。
参考文献:
https://eng.uber.com/horovod/
https://www.aiuai.cn/aifarm740.html
https://zhuanlan.zhihu.com/p/40578792
https://ggaaooppeenngg.github.io/zh-CN/2019/08/30/horovod-实现分析/
https://blog.csdn.net/zwqjoy/article/details/89552432
https://www.jiqizhixin.com/articles/2019-04-11-21
https://zhuanlan.zhihu.com/p/50116885
https://zhuanlan.zhihu.com/p/70603273
https://juejin.im/post/5cbc6dbd5188253236619ccb
https://zhpmatrix.github.io/2019/07/18/speed-up-pytorch/
https://cloud.tencent.com/developer/article/1117910
https://www.infoq.cn/article/J-EckTKHH9lNYdc6QacH

 浙公网安备 33010602011771号
浙公网安备 33010602011771号