浅谈InnoDB中的聚簇索引和二级索引[译]
聚簇索引 (主键索引)(Clustered Index (Primary Index))
聚簇索引与其说是索引,不如说是InnoDB用来存储记录的数据容器更为恰当。
InnoDB中的聚簇索引采用B-Tree组织起来,每个节点都是一个Page(InnoDB存储记录的最小单位);非叶节点存 Key 的值和指向孩子节点的指针,叶子节点则存储记录和指向相邻叶节点的指针(所有叶节点构成一个双向链表),下面是一个简单的示意图:
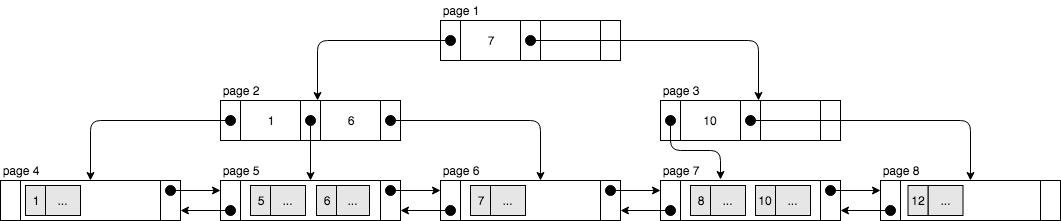
InnoDB根据Key值顺序存储记录,相邻的Node彼此通过指针连接,这样有两个好处:
- 这样相关的记录会存储的比较近,读取相关记录的时候只需要Load少数Page就好。例如上图若要读取key 5和key 6的记录,只要加载page 5就好。
- 执行范围查询时不用整棵B+树都扫描一遍,只要找到最小的key值所在的叶节点Page,一直往后读即可。例如上图查询key值在5〜10的记录,只要找到key 5所在的page 5,然后一直往后读值到key 10所在的page 7为止。
当然排好序的记录也有一些缺点,如果插入key值无序的记录时容易造成性能问题。例如上图如果插入一条key为13的记录时,MySQL会直接写入到page 8;但若是插入一条key为9的记录时会导致page 7发生页拆分(Page Split),这种情况下MySQL会在Page之间移动记录,继而影响性能。
MySQL并不会把Page的全部空间都用完,相反,它会保留一部分空间为日后添加或更新使用,如上图的page 6。根据MySQL 5.7 Reference Manual:
If index records are inserted in a sequential order (ascending or descending), the resulting index pages are about 15/16 full. If records are inserted in a random order, the pages are from 1/2 to 15/16 full.
如果index的记录是顺序插入,索引页(Index Page)的使用率会在15/16左右,但若是乱序插入的话,索引页的使用率则会在1/2到15/16之间。
由上述原因可以知道,聚簇索引是如何影响范围查询、插入记录的性能以及Page空间的使用率的,所以一个恰当的聚簇索引键值(Clustered Key)很重要。MySQL选择聚簇索引键值的规则如下:
- 有Primary Key,选Primary Key;
- 没有Primary Key,选第一个NOT NULL的UNIQUE Key;
- 若都没有,则InnoDB生成一个auto increment的隐藏字段做聚簇索引键值。
二级索引(Secondary Index)
二级索引同样使用B-Tree数据结构,不同的是叶节点只存储二级索引的键值和聚簇索引键值(通常是Primary Key),聚簇索引键值是用于回表查询该条记录。
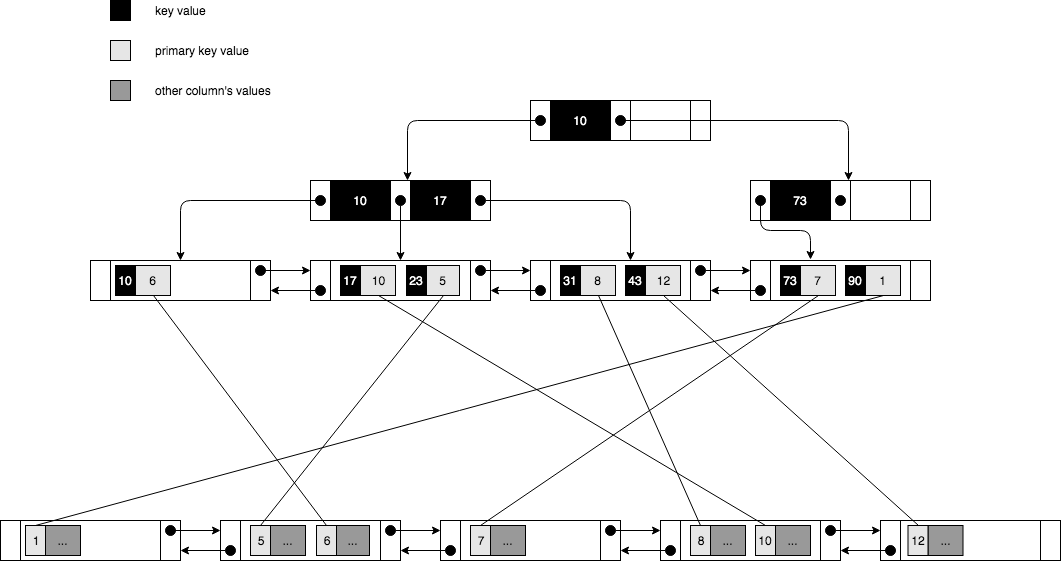
注意到上图中二级索引键值的顺序和聚簇索引键值顺序通常不同,所以二级索引做范围查询读取记录的性能通常不如聚簇索引高效(回表操作会有大量的随机IO)。因为二级索引会存储聚簇索引的键值,因此储聚簇索引键值的大小也会影响二级索引的大小,所以在选择聚簇索引键值时需要注意这点。
另外当SELECT的字段被二级索引覆盖的话,MySQL就不需要再回表查询了,这样执行速度更快。例如:
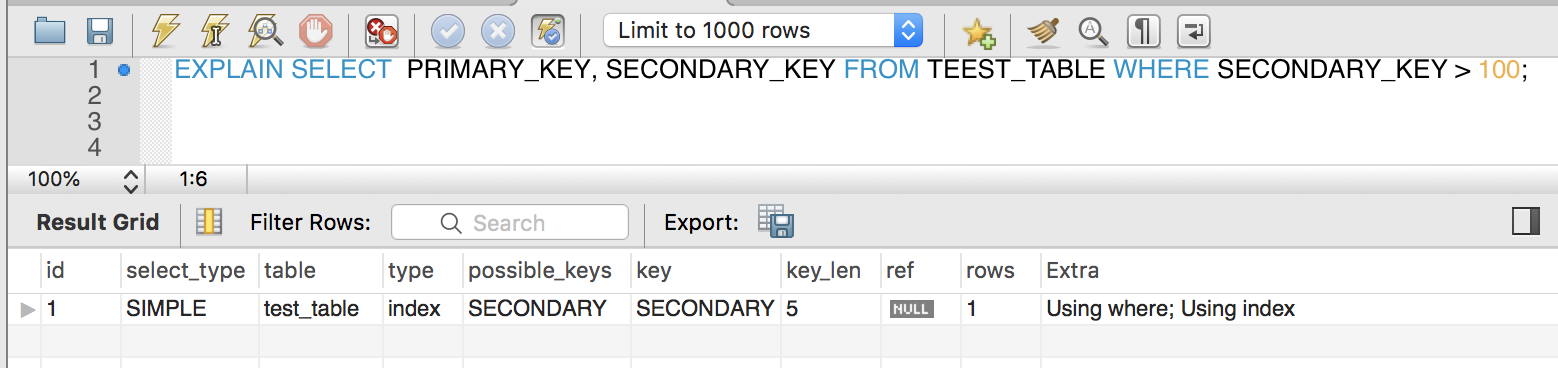
CREATE TABLE `test_table` ( `primary_key` int(11) NOT NULL, `secondary_key` int(11) DEFAULT NULL, `other_key` int(11) DEFAULT NULL, PRIMARY KEY (`primary_key`), KEY `SECONDARY` (`secondary_key`) )
用explain命令分析SELECT primary_key 和 secondary_key 的 SQL,extra 字段显示 using index,即 MySQL 执行这条语句时直接从索引取值。
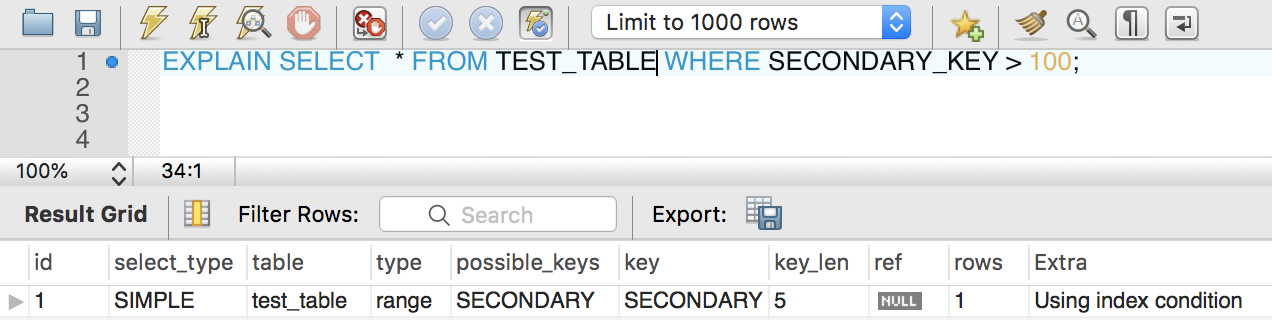
反之,则会看到extra字段显示 using index condition,即需要进行回表取需要的字段值。
小结
索引是个复杂的主题,但通过了解索引底层的运行原理可以帮助我们更精准的使用索引,基本原则如下:
- InnoDB读取记录是以Page为单位,加载一个Page只为读取一条记录是很浪费且低效的行为。挑选好Primary Key,可以利用访问局部性(Locality of Reference)提高性能(让相关的记录集中在几个Page里面,这样InnoDB加载一个Page就可以读取到多条记录)。
- 使用二级索引读取记录需要进行回表操作,正如同上面第一点提到的,加载一个Page读取一条记录是低效的。因此二级索引覆盖所有需要的字段对性能会有显著提升。
译自 A Brief Introduction to Cluster Index and Secondary Index in InnoDB

 浙公网安备 33010602011771号
浙公网安备 33010602011771号