
scrapy框架学习(二)项目创建及seting基本配置
项目创建
1.创建项目
1.创建项目:进入要创建项目的目录,并在终端内输入命令 scrapy startproject 项目名
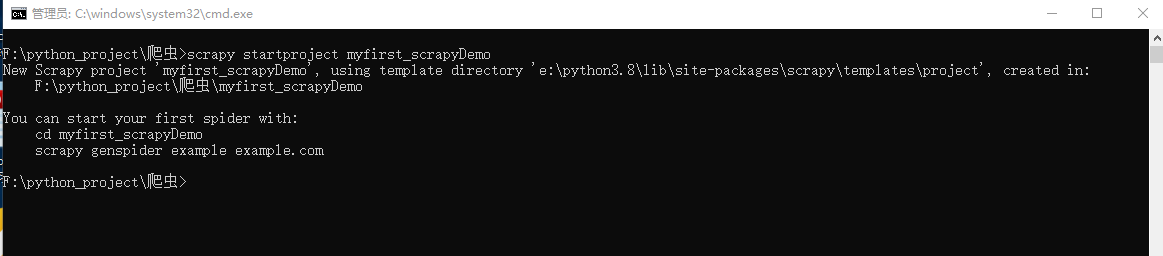
2.创建爬虫文件:进入创建的爬虫项目目录,并在终端内输入命令 scrapy genspider 爬虫名 域名

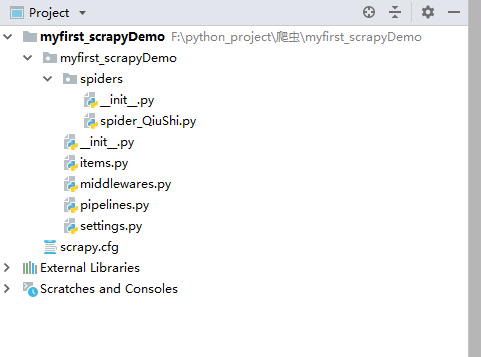
3.项目目录结构
myfirst_scrapyDemo
myfirst_scrapyDemo 真正的项目文件
__pycache__ // 缓存文件夹,存放编译好的字节码文件
spiders //爬虫文件存放的地方
__pycache__ //缓存文件夹,存放编译好的字节码文件
__init__.py //包的标志
spider_QiuShi.py //爬虫文件(*),此文件要执行第2步操作后才会被创建,文件名即为输入的爬虫名,其余目录及文件均为 第1步操作时创建
__init__.py //包的标志
items.py // 定义数据结构的地方(*)
middlewares.py //中间件
pipelines.py //管道文件(*)
settings.py //配置文件(*)
scrapy.cfg //项目基本配置文件,不用管
2.爬虫文件
spider_QiuShi.py

name: 爬虫名字
allowed_domains: 允许的域名
start_urls: 起始url
parse: 自动回调的解析内容函数
3.配置文件
settings.py
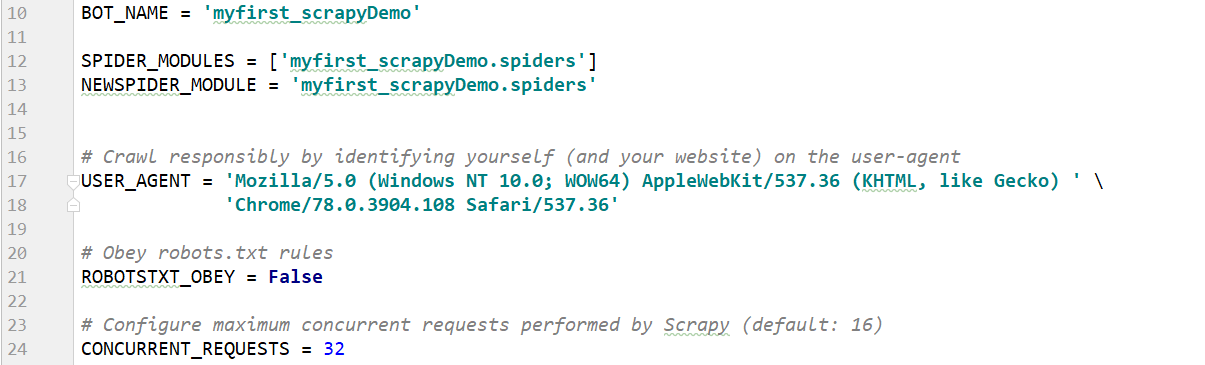
BOT_NAME:项目名
USER_AGENT:默认是注释的,这个东西非常重要,如果不写很容易被判断为电脑
ROBOTSTXT_OBEY:是否遵循机器人协议,默认是true,需要改为false,否则很多东西爬不了
CONCURRENT_REQUESTS:最大并发数,很好理解,就是同时允许开启多少个爬虫线程
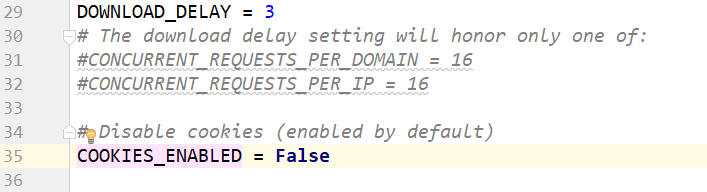
DOWNLOAD_DELAY:下载延迟时间,单位是秒,控制爬虫爬取的频率,根据你的项目调整,不要太快也不要太慢,默认是3秒,即爬一个停3秒,设置为1秒性价比较高,如果要爬取的文件较多,写零点几秒也行
COOKIES_ENABLED:是否保存COOKIES,默认关闭,开启可以记录爬取过程中的COKIE,非常好用的一个参数

ITEM_PIPELINES:项目管道,300为优先级,越低越爬取的优先度越高。需要使用管道存储数据时,此项必须打开。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号