Day6.Hadoop学习笔记4
一、MapReduce任务提交(前4步)
(源码分析——前4步发生在client node 上)
Job.java 从1292行
/**
* Submit the job to the cluster and return immediately.
* @throws IOException
*/
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
connect();
//经过connect拿到cluster,然后.getFileSystem()拿HDFS配置,.getClient()拿YarnRunner配置
final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
//不要进入doAs,匿名内部类形式,模板编程思想,重点看核心功能
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster); //核心,关注重点
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
JobSubmitter.java 从432行
//在第158行,可以看到创建的文件夹信息。
// configures -files, -libjars and -archives.
private void copyAndConfigureFiles(Job job, Path submitJobDir,
short replication) throws IOException {
Configuration conf = job.getConfiguration();
if (!(conf.getBoolean(Job.USED_GENERIC_PARSER, false))) {
LOG.warn("Hadoop command-line option parsing not performed. " +
"Implement the Tool interface and execute your application " +
"with ToolRunner to remedy this.");
}
// get all the command line arguments passed in by the user conf
String files = conf.get("tmpfiles");
String libjars = conf.get("tmpjars");
String archives = conf.get("tmparchives");
String jobJar = job.getJar(); //启动jar(代码片段)
/**
* Internal method for submitting jobs to the system.
*
* <p>The job submission process involves:
* <ol>
* <li>
* Checking the input and output specifications of the job.
* </li>
* <li>
* Computing the {@link InputSplit}s for the job.
* </li>
* <li>
* Setup the requisite accounting information for the
* {@link DistributedCache} of the job, if necessary.
* </li>
* <li>
* Copying the job's jar and configuration to the map-reduce system
* directory on the distributed file-system.
* </li>
* <li>
* Submitting the job to the <code>JobTracker</code> and optionally
* monitoring it's status.
* </li>
* </ol></p>
* @param job the configuration to submit
* @param cluster the handle to the Cluster
* @throws ClassNotFoundException
* @throws InterruptedException
* @throws IOException
*/
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//执行OutputFormat的checkOutputSprcs方法,就是判断目录是否存在
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
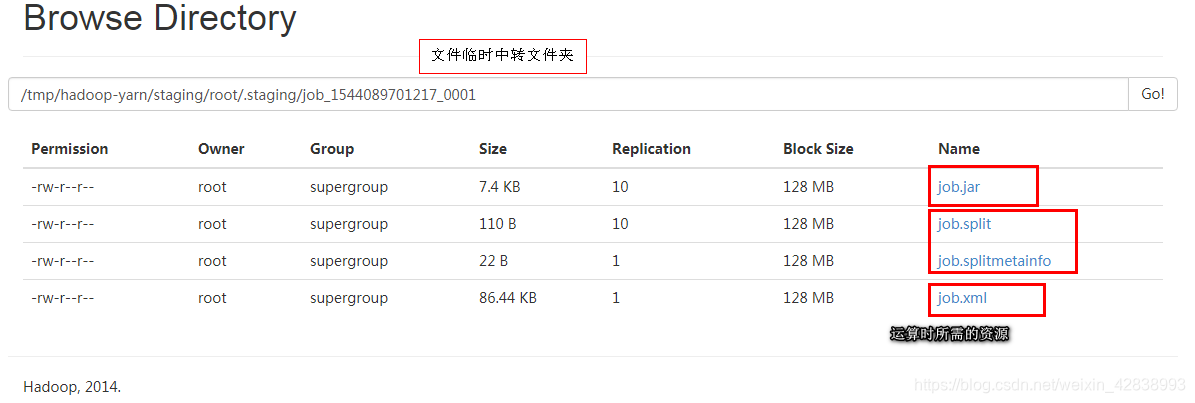
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); //文件临时中转区
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
JobID jobId = submitClient.getNewJobID(); //拿到每个jobId
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString()); //拼接成提交目录
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
int keyLen = CryptoUtils.isShuffleEncrypted(conf)
? conf.getInt(MRJobConfig.MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS,
MRJobConfig.DEFAULT_MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS)
: SHUFFLE_KEY_LENGTH;
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(keyLen);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
copyAndConfigureFiles(job, submitJobDir);
//【☆】上传运行时所需要的jar和第三方依赖,调用conf.set("temjars","~jar包路径~")
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
//调用的是,new Path(jobSubmitDir, "job.xml");
//job.xml把所有集群配置信息汇总,包括之前配置的core-site.xml、hdfs-site.xml
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
//【☆】在任务提交初期,需要进行切片计算
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
//【☆】上下文配置,生成job.xml
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
//提交.submitJob方法————>之后的步骤,去到另一端yarn中,在客户端不再影响
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
二、如何解决Jar包依赖问题
- 计算节点依赖
方案1 多测试用,跨平台远程调用,设置tmpjars
conf.set("tmpjars","file://jar1路径,file://jar2路径");
方案2 必须注意书写格式,详尽的run没有写在main函数中。
public class CustomJobSubmitter extends Configured implements Tool {
//封装job
public int run(String[] args) throws Exception {
Configuration conf=getConf();
//封装job ...
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new CustomJobSubmitter(),args);
}
}
配合:
hadoop jar xxx.jar 入口类 -libjars 依赖jar1路径,依赖jar1路径
- 提交节点依赖(ClientNode依赖)
思路,将提交依赖的jar包添加到hadoop的类路径下;classpath
[root@CentOS ~]# hadoop classpath
/usr/hadoop-2.6.0/etc/hadoop:/usr/hadoop-2.6.0/share/hadoop/common/lib/*:/usr/hadoop-2.6.0/share/hadoop/common/*:/usr/hadoop-2.6.0/share/hadoop/hdfs:/usr/hadoop-2.6.0/share/hadoop/hdfs/lib/*:/usr/hadoop-2.6.0/share/hadoop/hdfs/*:/usr/hadoop-2.6.0/share/hadoop/yarn/lib/*:/usr/hadoop-2.6.0/share/hadoop/yarn/*:/usr/hadoop-2.6.0/share/hadoop/mapreduce/lib/*:/usr/hadoop-2.6.0/share/hadoop/mapreduce/*:/usr/hadoop-2.6.0/contrib/capacity-scheduler/*.jar
一般解决办法是将通过配置HADOOP_CLASSPATH环境变量的方式解决:
[root@CentOS ~]# vi .bashrc
HADOOP_CLASSPATH=/root/mysql-connector-java-5.1.38.jar
HADOOP_HOME=/usr/hadoop-2.6.0
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
export HADOOP_CLASSPATH
[root@CentOS ~]# source .bashrc
[root@CentOS ~]# hadoop classpath
/usr/hadoop-2.6.0/etc/hadoop:/usr/hadoop-2.6.0/share/hadoop/common/lib/*:/usr/hadoop-2.6.0/share/hadoop/common/*:/usr/hadoop-2.6.0/share/hadoop/hdfs:/usr/hadoop-2.6.0/share/hadoop/hdfs/lib/*:/usr/hadoop-2.6.0/share/hadoop/hdfs/*:/usr/hadoop-2.6.0/share/hadoop/yarn/lib/*:/usr/hadoop-2.6.0/share/hadoop/yarn/*:/usr/hadoop-2.6.0/share/hadoop/mapreduce/lib/*:/usr/hadoop-2.6.0/share/hadoop/mapreduce/*:`/root/mysql-connector-java-5.1.38.jar`:/usr/hadoop-2.6.0/contrib/capacity-scheduler/*.jar
三、Shuffle浅析【重难点】
在MapTask类中,有一个方法runNewMapper,他里边有这样一段代码:
// get an output object
if (job.getNumReduceTasks() == 0) {
//是通过OutputFormat#getRecordWriter将数据直接写入目的地
output = new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
//Map Reduce 统计 数据写入磁盘 -> Map Shuffle
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
- Task任务可以只有map,而没有reduce
- 场景示例:通过 点击商品、点关注、加购物车,来计算物品推荐度;对应不同操作,有不同的权重打分,后台采集用户行为数据(日志);将数据转化成一定的分组情况。当然再复杂的日志,也可以使用正则来抽取。
这就是数据的"ETL",数据的"清洗"。
- 设置job.setNumReduceTasks(0);意义?【面试题】
不设置的话,默认为1;设置0起到短路特性,必执行第一个分支。
output = new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
//实际上,调用的是OutputFormat的write方法
答:短路shuffle过程,直接将Map端的结果作为输出。
有以下使用场景:
数据查询(海量数据)
做数据的"清洗"、“降噪”(数据有价)
小tip:“抖动降噪”,利用定时任务来写日志,进行数据的有效过滤。
- 数据清洗
如:系统推荐
采集日志数据(点击、浏览、购买行为)–> HDFS --> 数据降噪处理 (有价值数据)–>数据格式一致化转换(符合算法需要大数据格式userid,itemid,score)–> 算法分析Mahout–> 推荐数据(userid itemid recommand)–>业务干预(清洗、过滤)–> RDBMS --> 可视化,推荐
- Shuffle我们把 k-v 转成 k-v[ ] 数组,的过程,我们称之为Shuffle.
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
//当我们走下边的分支时,进入shuffle过程。
- MapOutputBuffer 一个circular分区的环状的缓冲区。
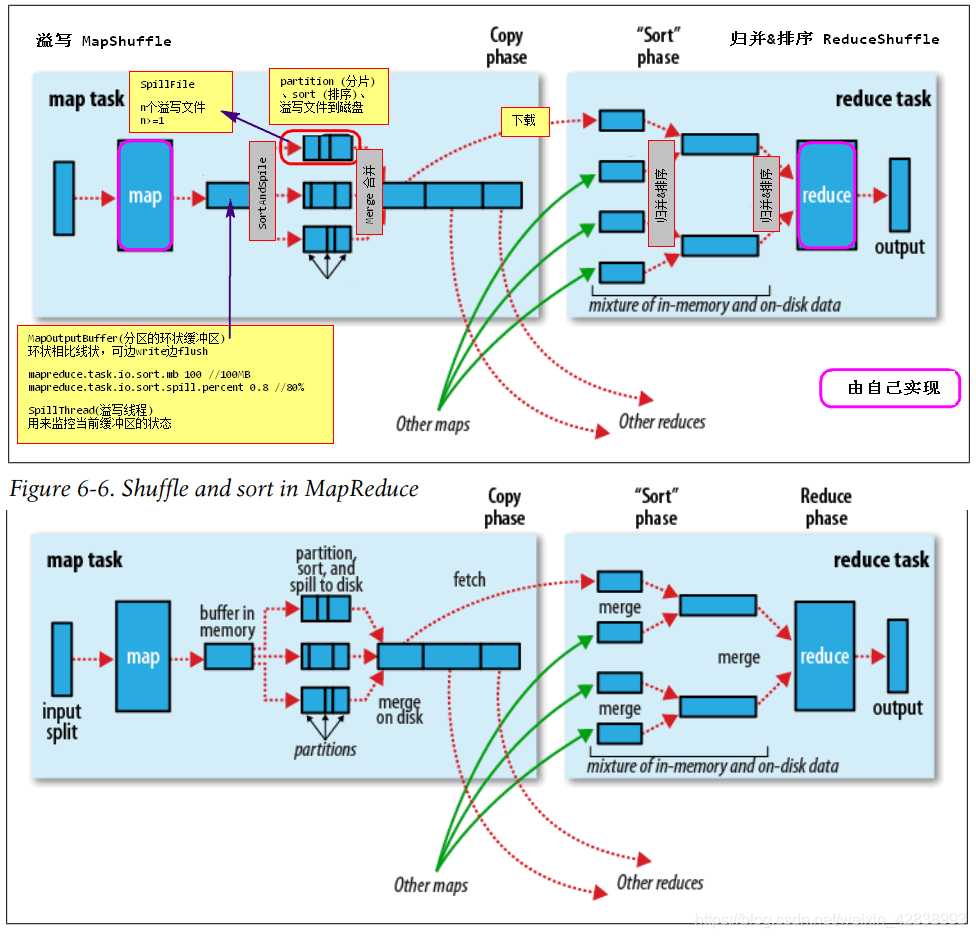
① 当我们map不停往外写数据时,为了减少磁盘io的频度,提升写出的性能,会为每个mapTask准备环状的缓冲区。这个缓冲区的大小默认100MB,环状缓冲区可以边写边flush,同时它有一个阈值80%,即达到80%再进行flush。 flush时依然可以写入。
这种机制不会覆盖数据,但当flush没有写入快时,会产生阻塞。
flush在缓冲区构建时,内部启动线程SpillThread(溢写线程),由它来监控当前缓冲区的状态。
②分区的作用?partition,负载均衡。reduce的本质是统计,统计的依据是拿到key的所有值。对应的一个key的值,应该都在一个分区中,即保证key一样的记录落在同一个分区中。所以在进入缓冲区前,已经将分区分配好了。
@Override //MapTask.java 711行
public void write(K key, V value) throws IOException, InterruptedException {
//写方法,调用collect方法 三个参数 key、value、int类型的区号
collector.collect(key, value, partitioner.getPartition(key, value, partitions));
}
最终会经过计算,拿到区号
partitions = jobContext.getNumReduceTasks(); //总分区数 == reduce数 696行
if (partitions > 1) {
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
//进入这里一定是1 返回区号0
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
②为什么排序?sort在溢写之前完成,SortAndSpile
③一次mapTask会产生n次溢写,至少一次,每次溢写产生SpillFile(溢写文件),会产生n个溢写文件。有几个maptask就会有几个溢写文件。
④每一个reduceTask下载自己分区的数据,拿到对应分区排过序的数据,但分区之间没有排序,还需要排序,并合并称为 key-value[ ] 数组
⑤综上,我们把这两个部分称为Shuffle。
Map端:溢写(分区,排序) ,溢写合并
Reduce端:下载,归并,排序
-
什么是溢写?【面试题】
答:缓冲区什么样子?溢写的时机? 结合上方的 ① 回答。
MapOutputBuffer大小 mapreduce.task.io.sort.mb 100MB mapreduce.map.sort.spill.percent 0.8 --> flush磁盘的过程(分区、SpillThread、sort、merge) -
如何自定义Map端key,value类型(如何自定义Writable或者WritableComparable接口)
- 如果是自定义Map端输出的KEY类型,必须满足
可排序、可序列化,因此用户需要实现WritableComparable - 如果自定义Map端的Value类型,只需要满足
可序列化,实现Writable
注意如何自定义Reduce端输出key、value类型取决于OutputFormat中的RecordWriter对Key/Value的要求。如果用户想干预MR的排序,可以自定义Map端Key类型,覆盖compareTo方法。
- 如何干预分区策略?
通过job.setPartitionerClass(XxxPartitioner.class);设置分区策略。
public class XxxPartitioner<K2, V2> implements Partitioner<K2, V2> {
public int getPartition(K2 key, V2 value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
注意默认MR框架做的都是分区内部排序,如果想全局排序,需要做分区排序,这有可能导致分区数据不均匀,导致计算倾斜。
-
Hadoop的MapReduce如何实现全局排序?
保全分区策略有序,结果自然是全局有序的缺点:区间设置不合理,到时数据的倾斜。hadoop提供一个TotalOrderPartitioner 实现全局排序 -
数据倾斜【面试题:什么是MapReduce计算过程中的数据倾斜问题?】
实现分区策略?(错区)
分区不均匀,不会影响map阶段,但会影响reduce阶段。
必须保证key相同的记录,落在同一个分区,因此无论如何实现Partitioner都无法解决数据倾斜。需要合理的定制用户的Key,使得分区数据相对均匀。
因为不合理的KEY,导致了数据的分布不均匀。选择合适的key作为统计依据,使得数据能够在爱分区均匀分布。一般需要程序员对分析的数据有一定的预判!
- 如何优化MR程序?(Map端Gzip压缩(通用的))
- 对Map端输出结果进行压缩,减少Reduce shuffle数据下载量(通用),可以有效,减少Reduce Shuffle过程的网络带宽占用。可以在计算过程中需要消耗额外的CPU进行数据的压缩和解压缩。
conf.setBoolean("mapreduce.map.output.compress", true);
conf.setClass("mapreduce.map.output.compress.codec",GzipCodec.class,
CompressionCodec.class);
只能在实际的环境下测试,本地仿真测试会失败.
- 如果计算具备可以迭代特性,可以考虑在Map端执行局部的Reduce,我们将该方法称为Combiner
- MR另一种优化方案——Combiner
在Map端发生溢写的时候或者是合并溢写文件的时候,对Map端的输出结果执行Reduce逻辑,但是这种执行后的,结果格式必须不改变原有Map端输出的格式类型,并且该预处理的结果不影响ReduceShuffle以及Reducer逻辑。
job.setCombinerClass(XXXReducer.class)
- CombinerReducer实际就是一个Class extends Reducer,combiner一般发生在溢写阶段和溢写文件合并阶段。
- Combiner输入k-v和输出k-v类型必须一致
- v的值,必须具备可迭代计算特点
- 即1.计算逻辑不影响(经验积累)、2.类型兼容
减少溢写文件大小,减少后续key的排序数量
其他、
- ETL(Extract-Transform-Load)
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。 ETL是BI项目重要的一个环节。 通常情况下,在BI项目中ETL会花掉整个项目至少1/3的时间,ETL设计的好坏直接关接到BI项目的成败。
ETL的设计分三部分:数据抽取、数据的清洗转换、数据的加载。在设计ETL的时候我们也是从这三部分出发。数据的抽取是从各个不同的数据源抽取到ODS(Operational Data Store,操作型数据存储)中——这个过程也可以做一些数据的清洗和转换),在抽取的过程中需要挑选不同的抽取方法,尽可能的提高ETL的运行效率。ETL三个部分中,花费时间最长的是“T”(Transform,清洗、转换)的部分,一般情况下这部分工作量是整个ETL的2/3。数据的加载一般在数据清洗完了之后直接写入DW(Data Warehousing,数据仓库)中去。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号