
十分钟读懂 Deepseek MTP(Multi-Token Prediction)
传统的大语言模型采用的训练目标是 Next-Token Prediction (NTP),即在位置 t 上预测下一个 token (t+1)。
而 Multi-Token Prediction (MTP) 的核心思想在于:
- 不仅预测下一个 token,而是能够同时预测多个未来的 token。
- 这种方式可以显著提升推理效率。例如,当 n=4(一次预测 4 个 token)时,推理速度可实现约 3 倍的加速。
DeepSeek-V3 借鉴了 Meta FAIR 团队论文 Better & Faster Large Language Models via Multi-token Prediction 中的思路,但在实现上有明显不同:它并不是直接并行预测多个 token,而是保持完整的因果链,以逐层递进的方式预测未来 token。
本文将重点介绍 DeepSeek-V3 中 MTP 的实现。在此之前,我们先回顾一下 Meta FAIR 团队提出的 MTP 思路。
1. MTP 方法
1.1 NTP (Next-token Prediction)
- 传统语言模型的训练目标:给定历史上下文 $x_{1:t}$,预测下一个 token $x_{t+1}$。
- 损失函数是标准的交叉熵:$$ L_1 = -\sum_t \log P_\theta(x_{t+1} | x_{1:t}) $$
- 这种方式虽然简单有效,但只考虑一步预测,容易陷入局部模式学习。
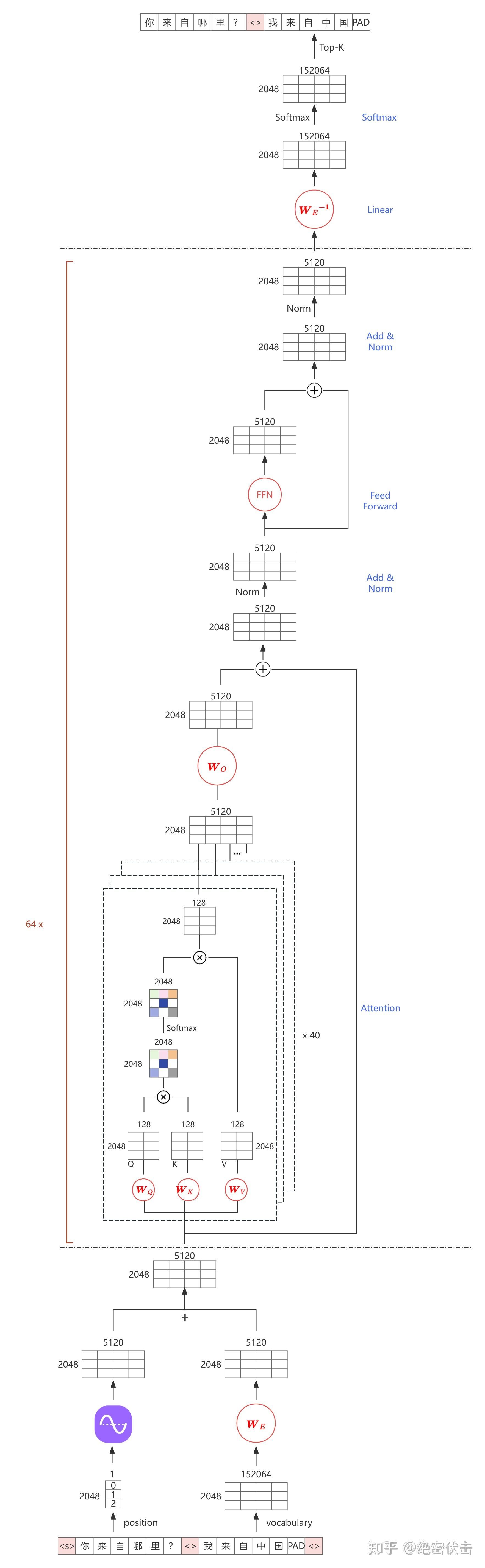
下图是 NTP 示意图,我们以 Qwen2.5-32B 为例,词表大小为 152064,hidden size 为$d_{model} = 5120$ ,num heads 为 40,Transformer block 的层数为 64,假设输入序列长度为 2048。
1.2 MTP (Multi-token Prediction)

如图 2 所示,MTP 在原有的 NTP 基础上,引入了多个额外的 head,输入为 $x_{1:t}$,head1 预测 $x_{t+1}$到 $x_{t+1+n}$ 、head2 预测 $x_{t+2}$ 到 $x_{t+2+n}$ 、head3 预测 $x_{t+3}$ 到 $x_{t+3+n}$ ,以此类推。每个位置上同时预测 未来的 n 个 token。损失函数推广为:
$$ L_n = -\sum_t \log P_\theta(x_{t+1:t+n} | x_{1:t}) $$
为了简化计算,作者将其分解为 n 个独立预测:
$$ L_n = -\sum_t \sum_{i=1}^n \log P_\theta(x_{t+i} | z_{1:t}) \cdot P_\theta(z_{1:t} | x_{1:t}) $$
其中:$ z_{1:t} \in \mathbb{R}^{T \times d_{\text{model}}} $ 就是图 2 中 64 个 Transformer Block的输出。
1.3 显存优化
直接实现 MTP 时,对于每个位置,需存储 n 个预测 head 的 logits(维度 𝑛×𝑉,其中 V 是词表大小),会占用大量 GPU 显存,为了解决这个问题,论文采用了顺序执行 forward/backward:
- 先计算 head1 的前向与反向,释放其梯度;
- 再计算 head2,以此类推;
- 这样显存复杂度从 𝑂(𝑛𝑉+𝑑) 降为 𝑂(𝑉+𝑑),几乎没有额外开销。
下面是一个具体的例子:
1.4 推理优化
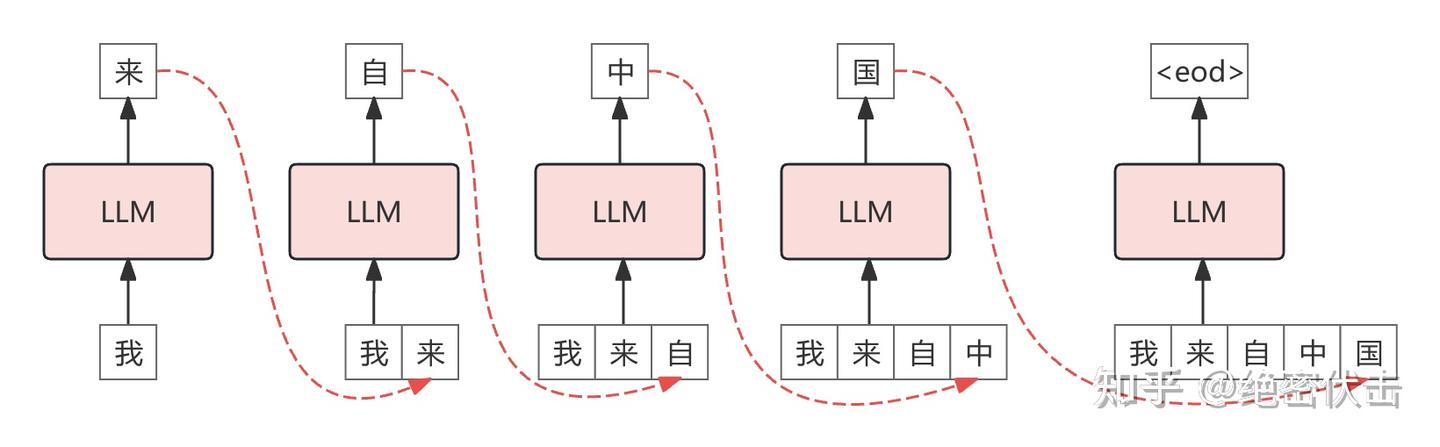
图 4: NTP 推理过程
图 4 是 NTP 的推理过程,每次预测一个 token。下图是 MTP 的推理过程:
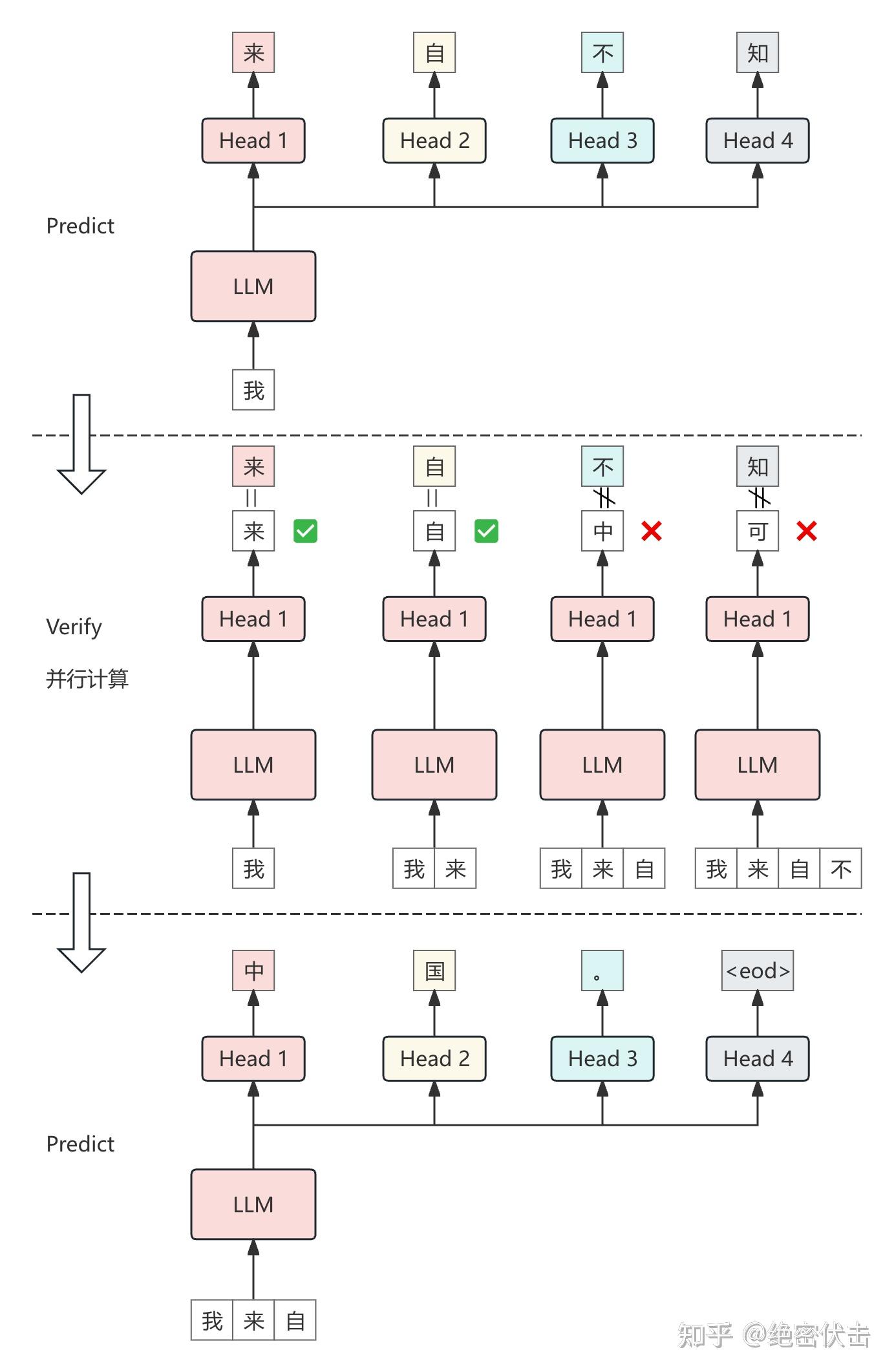
图5: MTP 推理
如图 5 所示,在有 4 个 head 的情况下:
- 阶段 1: Predict,MTP 首先根据上下文预测未来 4 个 token:“来”、“自”、“不”、“知”;
- 阶段 2: Verify,然后进行并行验证,前两个 token 通过验证,第 3 个没有通过;
- 阶段 3: Accept,将上下文和通过验证的 token concat,构成新的上下文["我", "来", "自"],然后继续重复上面的步骤。
假设输出序列长度为 𝑚 ,head 数为 𝑘 ,根据图5:
- 预测 (Predict):每次需要执行一次 Transformer trunk,一共需要执行 𝑚/𝑘 次;
- 验证 (Verify):每次验证,从第二个 token 开始需要执行一次 Transformer trunk,验证 𝑚/𝑘 次,那么需要执行 𝑚/𝑘 次 Transformer trunk;
因此,总共需要执行 2𝑚/𝑘 次 Transformer trunk。而 NTP 需要执行 𝑚 次 Transformer trunk。因此按照图 5 的方式,MTP 的推理速度是 NTP 的 𝑘/2 倍。
但是,我们理想的情况是只需要执行 𝑚/𝑘 次,这样推理速度就是 NTP 的 𝑘 倍。
论文 Blockwise Parallel Decoding for Deep Autoregressive Models 中提出了合并预测与验证的方法。如下图所示:
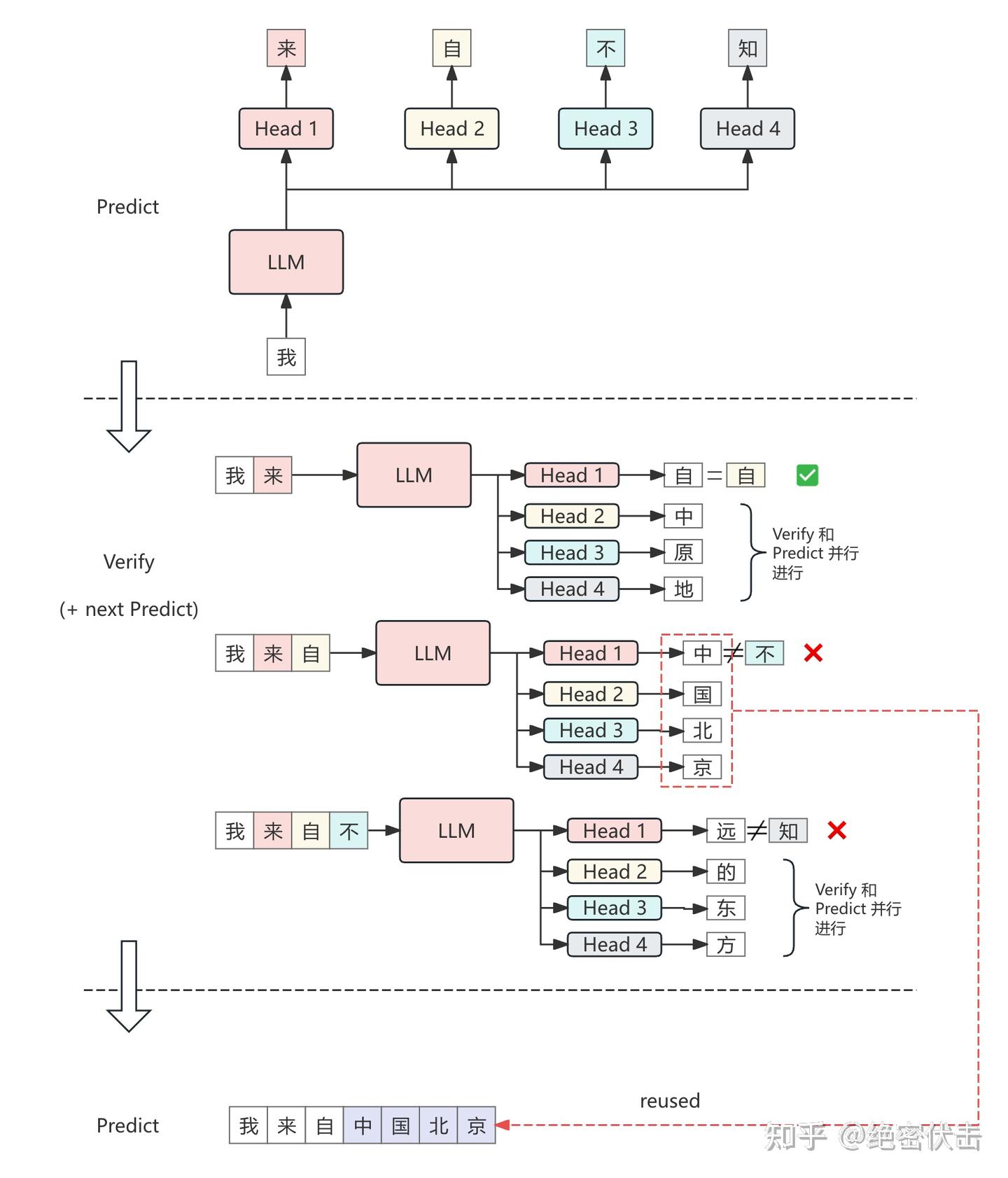
图 6: 将 MTP 的预测和验证合并
如图 6 所示:
第一步:预测与验证合并
模型在一次调用中不仅预测下一个 token,还会同时预测多个未来的 token。 在图 6 中,模型给出了几个候选序列:
- “我来自不知”
- “我来自中原地”
- “我来自中国北京”
- “我来自不远的东方”
由于基准模型判定“不”不正确,最终验证通过的前缀是:“自”。
第二步:结果复用(Predict Reused)
在验证完成后,下一次预测无需再次调用模型,而是直接复用上一步已经生成好的 𝑘 个候选 token,例如“我来自中国北京”。
重复执行上述步骤时,只需运行一次 Transformer trunk,而不是两次。这样模型调用次数由原来的 2𝑚/𝑘 降低到约 𝑚/𝑘,推理速度接近 NTP 的 𝑘 倍。
1.5 实验效果
下图展示了在不同 head 数情况下的加速情况,在 𝑛=4 的情况下,推理速度大幅提升。
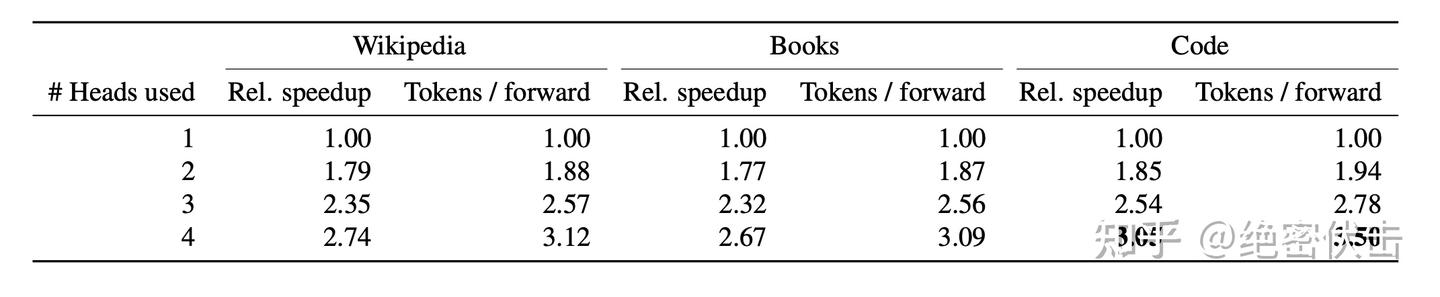
图 7: MTP 加速效果
2. DeepSeek-V3 MTP
2.1 训练过程
有了前面的知识,再来理解 DeepSeek-V3 中的 MTP 就容易得多。
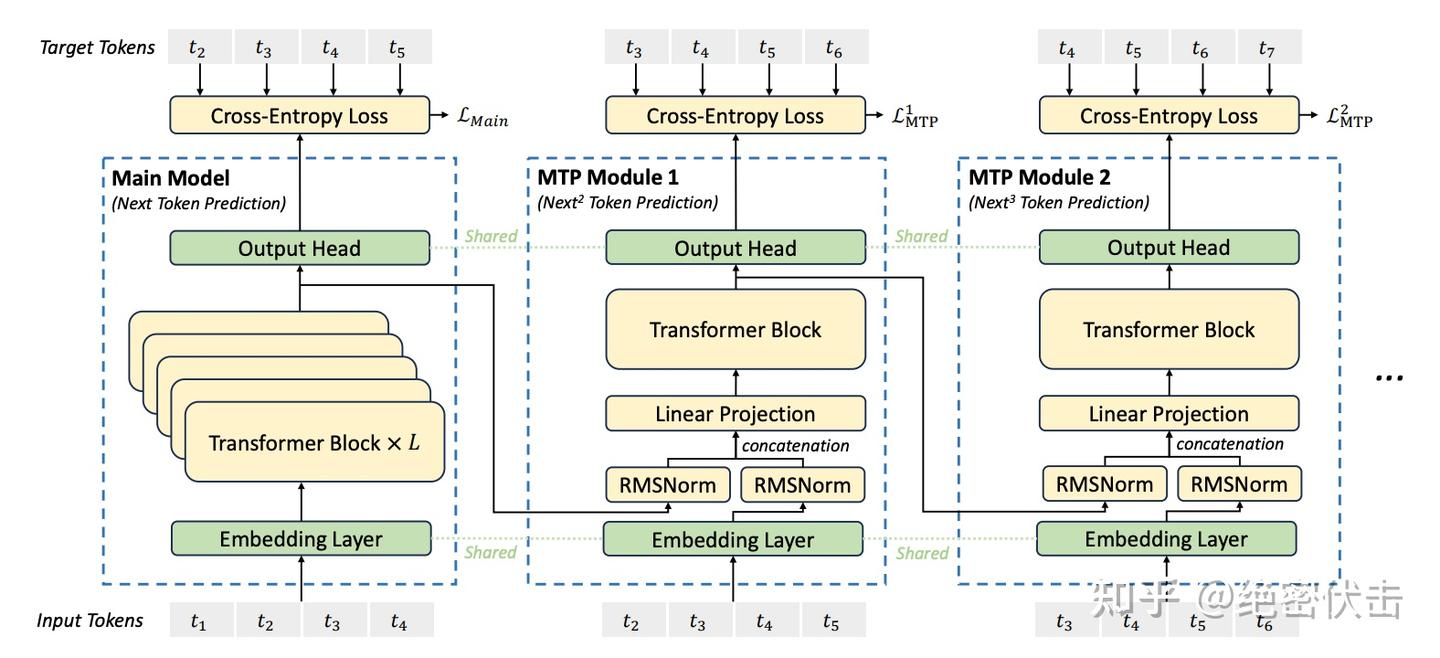
图8: DeepSeek-V3 MTP
与前面的 MTP 并行预测多个 token 不同,DeepSeek-V3 的实现是 逐层递进式(sequential):
- 保持完整因果链,即预测下一个 token 时依赖前一层预测结果。
- 如图 8 所示,DeepSeek-V3 使用 D 个 MTP 模块,逐级预测 D 个额外 token。
第 \( k \) 个 MTP 模块包括:
1. 共享的 embedding 层 \( \text{Emb}(\cdot) \);
2. 共享的输出头 \( \text{OutHead}(\cdot) \);
3. 一个 Transformer Block \( \text{TRM}_k(\cdot) \);
4. 线性投影矩阵 \( \mathbf{M}_k \in \mathbb{R}^{d \times 2d} \)。
计算过程(第 k 个 MTP,输入 token \( t_i \))
取上一个 MTP 表示 \( \boldsymbol{h}_i^{k-1} \in \mathbb{R}^d \) 与第 \( i + k \) 个 token 的 embedding \( \text{Emb}(t_{i+k}) \)
拼接并线性变换: $$\boldsymbol{h}_i^{\prime k} = \boldsymbol{M}_k[\text{RMSNorm}(\boldsymbol{h}_i^{k-1}); \text{RMSNorm}(\text{Emb}(t_{i+k}))]$$
输入 \( \text{TRM}_k \) 得到新表示: $$\boldsymbol{h}_{1:T-k}^k = \text{TRM}_k(\boldsymbol{h}_{1:T-k}^{\prime k})$$
经过共享的输出头 OutHead 计算预测分布:$$ P_{i+k+1}^k = \text{OutHead}(\boldsymbol{h}_i^k) $$
训练目标
对每个 MTP 头计算交叉熵损失: $$\mathcal{L}_{MTP}^k = -\frac{1}{T} \sum_{i=2+k}^{T+1} \log P_i^k[t_i]$$
最终损失是所有 MTP Head 的平均并加权: $$\mathcal{L}_{MTP} = \lambda \cdot \frac{1}{D} \sum_{k=1}^D L_{MTP}^k$$
其中:\(\lambda\) 是权重(训练中逐步衰减:前 10T tokens \(\lambda=0.3\),后续 \(\lambda=0.1\))。
2.2 推理阶段
与前文 1.4 节类似,DeepSeek-V3 同样可以采用图 6 所示的推理方式。不同之处在于,预测过程由并行改为串行。不过,由于 MTP 预测头的计算开销极小,因此整体开销与并行预测相比几乎没有差别。
转自:https://zhuanlan.zhihu.com/p/1947349001578997723

 浙公网安备 33010602011771号
浙公网安备 33010602011771号