


此作业要求详见https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126
代码界面HTTP: https://git.coding.net/gongylx/wf3.git
需求分析
1.写入一个输入文本小程序。
2.写入一个统计文本单词数小程序,要求包含total (总数不包括重复)以及字数最多的前10个单词个数以及排列显示。
3.完成将文档名作为参数在控制台输入,完成文档打开控制。
功能分析
1.控制台输入小文本,统计词汇量,total一项中相同的单词不重复计数数。
2.支持命令行输入英文作品的文件名。
3.支持命令行输入存储有英文作品文件的目录名,批量统计。
4.从控制台读入英文单篇作品,能提供更适合嵌入脚本中的作品
功能实现
1.功能1要求控制台显示文本内容,写了一个简单的写入文本代码,这个可以写入同一路径下的文本文档。项目代码采用python3.7编写,用的TortoiseGit自带的Notepad2编辑器编写,完成功能是运行type.py程序,将文本打开,输入内容进行保存。
1 import sys 2 3 if __name__ == '__main__': 4 filename = sys.argv[1] 5 with open(filename, 'w+') as f: 6 f.writelines(input())
具体实现如下:

功能1中比较困难的地方是文本的读取,利用命令行参数将文本打开并执行命令。python有读入文件等比较方便的函数操作,open()函数提供方便的打开文本方式,其中包括encoding读入文档编码方式.。打开读入文件代码如下
def wf(filename): with open(filename,encoding='utf-8') as f: lines = f.readlines()
另一项比较难控制的是将文本中所读入的字符判断,首先要确定什么样的算是具体的一个单词,先思考解决犹如did't这种两词合成一个的特殊例子,然后还要考虑标点符号,例如...you,but...,这时候单词you和单词but之间仅有一个标点符号相隔,这时候就不能仅仅利用判断是否是空格的方式去截断单词,这也是我认为最难的地方,通过在网上参考资料,研究学长学姐的代码,以及和舍友的讨论,最后采用的方法是将利用strip()方法将空白符删除,并利用line.lower()方法将所有单词小写,利用re.spit将带有标点符号的地方进行切割。最后分成单个单词,每行去判断是否是单词并进行累加计数。实现代码如下
for line in lines: line = re.split("[ ,.?!;]", line.lower().strip('\n')) for word in line: if word == '': continue if word not in d: d[word] = 1 else: d[word] += 1
然后将所得结果进行分类,total类是总数,这里和老师的结果不相同的原因是我的程序把所有的符号全部隔断了,也就是说我统计的单词数是不包括重复的不包括标点的纯单词数,这里利用Lambda匿名函数和sorted()函数操作刚才的单词列表并进行逆向排序。然后输出单词总数以及列表中排名前10重复的单词及它们的个数。代码如下
d_sorted = sorted(d.items(), key=lambda x: x[1], reverse=True) print('total', len(d_sorted),) print(' ') for i in range(min(len(d_sorted), 10)): print(d_sorted[i][0], d_sorted[i][1])
具体实现如下
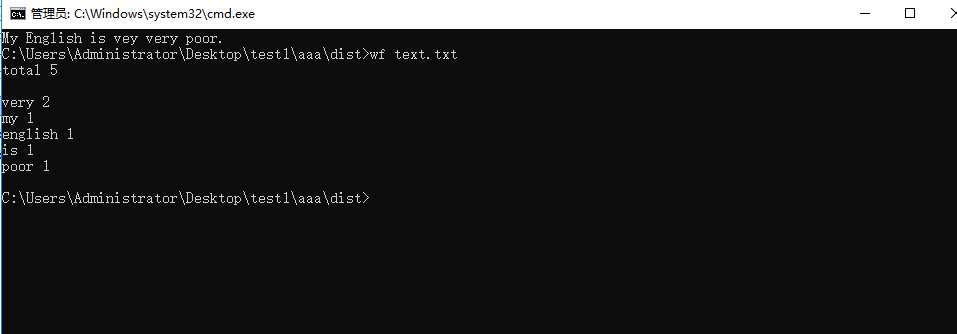
2.功能2实现的重点在于在控制台读取文件,就是将文件参数从控制台读入,进行运算。这时候利用sys.argv去在控制台传递参数,将文件作为参数去控制。这时候需要判定路径是否是文件,这里用os.path.isfile()方法去判断所给路径是否是文件,如果是文件,则满足功能2要求,在控制台读入文件参数并进行字符统计。代码如下
if __name__ == '__main__': if os.path.isfile(sys.argv[1]): wf(sys.argv[1])
具体实现如下
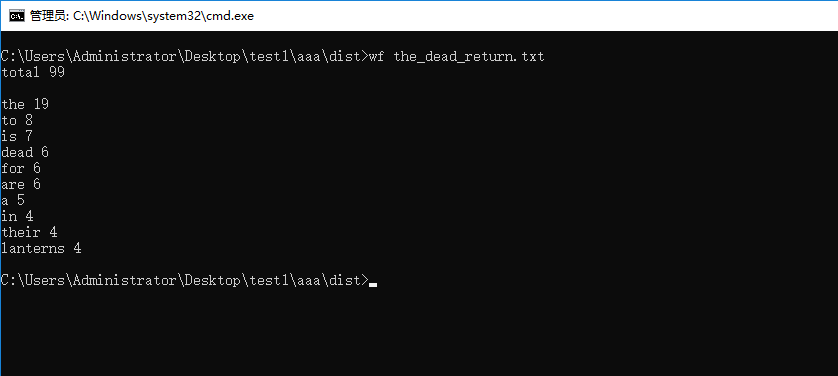
3.功能3看似和功能2一样,实则浪费了很多的时间和精力,因为开始并没有接触过批量读取文件夹中所有文档,一边网上百度,一边翻找python教程,找到了这里的处理方法。这里还是和功能2中的判断类似,判断如果所给路径不是文件,而是一个文件夹目录,利用os.path.isdir方法,如果满足目录条件,将路径输入,这时候用一个for循环去挨个处理文本,首先输出文件名,然后利用os.path.join方法将多个路径文档组合返回,挨个去实现功能,并在每个文档后用间隔线间隔开。如果所给路径不含文件或者路径不正确,则输出提示。具体代码如下
elif os.path.isdir(sys.argv[1]): path = sys.argv[1] for file in os.listdir(sys.argv[1]): print(file) wf(os.path.join(path, file)) print('--------------------') else: print(sys.argv[1], 'is not a file or path')
具体实现如下

这里遇到的困难是和老师测试结果不一致,第一个the_dead_return这本书和老师结果相同,当我测试《简爱》也是正确的,但是运行到《战争与和平的》的时候,统计的单词总数和老师不相同,而且单词的个数也有一丁点偏差,这时候我去统计前面短的文本文档,通过word字符统计和跑出来的结果相同,但是长的文本比如战争与和平就会有误差,这里我看了文档内容,里面包括*等一些特殊符号在上传的coding上的第一版上没有隔离,在之后的第二版上我把这些特殊符号隔离了,但是还是有疑惑的地方就是为什么单词数也会有差距,想着在终版的时候处理掉这个问题。
4.功能4所要求的利用重定向输入输出,我了解到,Linux Shell 环境中支持输入输出重定向,用符号<和>来表示。0、1和2分别表示标准输入、标准输出和标准错误信息输出,可以用来指定需要重定向的标准输入或输出,比如 2>a.txt 表示将错误信息输出到文件a.txt中。 但是具体功能我还没有实现。我会继续研究,争取早日实现此功能。
总结声明:从杨老师开始布置这个小项目开始,真的是不知所措,想从头开始学也知道时间不允许,幸亏舍友杨磊同学的帮助,我们俩各有分工,我代码比较强,而他之前对这类项目有一定的了解,但是对编程手段不太熟悉,如果分开完成,我知道我不会完成到这个程度,所以我们俩选择了互帮互助结对完成,虽然离老师的要求还有很远,但是我们努力了。
PSP阶段表格
| 预计花费时间 | 实际花费时间 | 花费时间差距 | 原因分析 | |
| 实现功能1 | 60min | 232min | 172min | 开始分析功能并构建框架的时候以为只用简单的C语言便可以实现,但是由 于VS环境没装明白,所以还是选择了使用假期学的python语言去编写,大 体的看了一遍基础教程,又在单词划分的地方浪费了很多时间,所以导致时 间比较长。 |
| 实现功能2 | 120min | 476min | 356min | 这段时间主要是遇到了将文件作文参数在控制台输入的困难,这一点在我所 用的python教程里没有,所以解决这个问题用了大量的时间,从网上搜索 解决办法再去学习,最后实现下来实属不易。 |
| 实现功能3 | 60min | 212min | 152min |
这个时间差主要是开始低估了这个问题,简单的以为和功能2差不多,没想 到这也是之前没了解的领域,从网上搜索资料才找到解决办法,浪费了时间。 |
| 实现功能4 | 120min | 136min | 16min | 这个功能实在是没读懂,然后百度了知乎了也没理解,大多数时间浪费在咨 询学长学姐那儿,但是也没有得到有效的答复。 |
| 测试功能1 | 10min | 18min | 8min | 第一个功能写完运行出现了低级错误,就是单词分隔错误。改正后测试成功。 |
| 测试功能2 | 30min | 69min | 39min | 第二个功能跑出来的结果一直不正确,多次分析再测试还是没消除这个问题。 |
| 测试功能3 | 10min | 16min | 6min | 这个功能是完全从网上学习来的,将文件夹目录下所有文档挨个测试,成功。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号