层次分析法笔记【零基础数模系列】
前言
看了很多讲解新概念新模型的文章,这些文章往往要么讲的很浅不讲原理只讲应用,让人知其然不知其所以然。要么讲的很深小白看不懂,同时总是忽略关键部分,经常性引入陌生概念让初学者疑惑,因此有了本文,任何能熟练掌握线性代数知识且逻辑思维能力尚可的人都可以理解,而无需其他数模知识,涉及任何新概念都会先讲解后使用
算法流程
先给出目标层(1层)、准则层(1~n层)、方案层(1层),
准则层既为评价指标,方案层既为“候选人”,准则层的评价指标我们无法直接给出比较客观的权重向量W,那么定义判断矩阵A,其中aii=1,aji=1/aij,aij就是标度,我们用标度来表述各指标重要程度的差别,比如aij=1代表ij指标重要重要,aij=5代表i比j明显重要,aij=9代表i比j强烈重要,234678则代表重要程度中间值。
然后便要进行层次单排序了,即根据判断矩阵A求出权重向量W,有两种求法,分别为方根法和和法
方根法求出A每行的几何平均数得到未归一化的权重列向量,然后进行归一化即可得到权重列向量
和法将A矩阵的每个列向量归一化,然后求每行的算数平均数得到为归一化的权重列向量,在进行归一化即可得到权重列向量。
//要注意区分单位化和归一化,单位化和归一化都是在确保向量各元素比值不变的情况下调整变量,即方向不变大小伸缩,单位化是把向量伸缩到模为1为止,归一化是把向量伸缩到元素之和为1为止
然后要求解最大特征根Lambda_max和C.I值,我们有
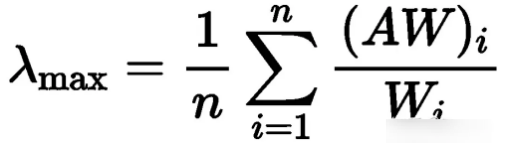
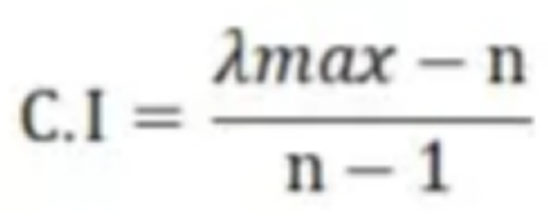
其中W是权重向量,AW是A·W的每一行的sum值构成的列向量,AW/W是向量的元素点乘,得到了评价指标i的特征,然后每个指标的特征值的平均数即为最大特征根Lambda_max,随后即可得到C.I值
根据矩阵阶数,我们查表可知对应的R.I值,然后即可得到CR值(CR=CI/RI)
表是类似于这样的:

CR值刻画的是这个评价体系有没有逻辑问题,比如aijajk>1而aik<1便是犯了逻辑错误,我们很难让aik完全等于aijajk,但无疑aik完全等于aij*ajk恒成立是最好的,最符合逻辑的,那么,我们将这个定义为“好”,CR值刻画的就是我们给出的这样一个评价体系是否足够“好”
CR<0.1即可认为A的一致性程度被认为在容许的范围内,如果CR>=0.1说明我们给出的判断矩阵出现了逻辑错误,需要对判断矩阵进行修正。
这次,我们便完成了层次单排序(即确定权值向量)和一致性检验(检验确定权值向量的判断矩阵的合理性),我们已经得到了准则层的权值向量,接下来便要进行层次总排序和第二次一致性检验了
想要得出候选人的评分,我们既需要个指标的权重,还对方案层的各个“候选人”的各大指标进行打分,得到候选人的各指标得分。层次总排序就是确定每个指标下各个候选人的得分情况,其中我们把每个指标的得分情况用一个向量来表示,这个向量的确定用和此前权值向量的确定类似的做法,先给出各个候选人在这一指标上的判断矩阵,然后进行“层次单排序和一致性检验”即可得到该指标的各候选人得分列向量,得分向量绑在一起就得到了得分矩阵,每个人的综合得分自然就是各指标得分的加权平均数,不难意识到得分矩阵和权值向量做向量乘法所得的向量的各个数便代表每个候选人的综合得分。
然后,抽象的地方来了,让我们冷静一下,以面对下面这个头脑风暴:
假设我们已知W向量,对于指标i而言,Aij(1<=j<=n)无疑刻画了指标i相对于其他指标的重要程度,将A的第i行抽出来组成行向量bi,那么设yi=bi·W这个对乘积无疑就是相对于其他指标的重要程度的加权平均数,即综合重要程度,这个“权”就恰恰是各指标的重要程度。那么列向量Y=(y1 ... yn)’无疑就描述了各个指标的综合重要程度,很显然Y理应和w成正比即Y=λW,这样的W才是“好”的W,又由A=[b1;b2;...;bn],yi=bi·W得Y=A·W,因此AW=λW,换句话说好的W就应该是A的特征向量。
因为根据A的性质(aij=1/aji)不难从数学上证得rank(A)=1,|A|>0也就是说A有且只有一个正实数特征值,因此A的正特征值对应的特征向量就是一个好的权重向量了,由这种方法确定出来的权重向量要比“方根法”和“和法”要合理的多。
但是,由于matlab的计算是用浮点数来完成的,三分之一会被截断成0.3333..,计算过程中还会发生各种浮点数误差,因此计算机计算出来的rank(A)极有可能不等于1,计算出来的实特征向量也很可能不止有一个,但我们要清楚,其他的实特征变量不论正负都不过是浮点误差所带来的,根据特征值的几何意义即该矩阵所表示的线性变换在另一基向量描述的线性空间中伸缩的倍数,我们可以知道浮点误差所带来假实数特征值的绝对值必定是很小的,因此我们只要去最大的正实数特征值,就可以确保取到正确的那个特征值,对应的特征向量a就是未归一化的权值向量。我们还可以根据最大特征根的定义进一步从数学上证明,Lambda_max就等于这个最大正特征值,便可更好地理解到最大特征根为什么叫最大特征根了。
因此我们拿到评价矩阵后,只需要求出最大特征值所对应的特征向量,在将这个特征向量归一化即可得到权值向量,最大特征值即为最大特征根,然后轻松求出CI,查表得RI,轻松得到CR即完成一致性检验,代码如下:
A=[1 3 5;0.33 1 3;0.2 0.33,1];
[n,n]=size(A);
[V,D]=eig(A);%求得特征向量和特征值
%求出最大特征值和它所对应的特征向量
tempNum=D(1,1);
pos=1;
for h=1:n
if D(h,h)>tempNum
tempNum=D(h,h);
pos=h;
end
end
w=abs(V(:,pos));%w要么全正要么全负,abs确保全正化
w=w/sum(w);
t=D(pos,pos);
disp('准则层特征向量w=');disp(w);disp('准则层最大特征根t=');disp(t);
%以下是一致性检验
CI=(t-n)/(n-1);RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59 1.60 1.61 1.615 1.62 1.63];
CR=CI/RI(n);
if CR<0.10
disp('此矩阵的一致性可以接受!');
disp('CI=');disp(CI);
disp('CR=');disp(CR);
else disp('此矩阵的一致性验证失败,请重新进行评分!');
end
最后,如果准则层指标太多怎么办?分层!把准则层分为准则层和子准则层(还可以有子子准则层etc),每个“点-下一层”的评价矩阵并求出权值矩阵,然后进行一致性检验。在根据权值向量求出最底准则层的权值向量,在得出每个方案层的候选人综合评分即可。
改进方法:每层指标数不要超过9个,若超过则分层。评价矩阵可以有三人独立提出最后用德尔菲法综合得到最终评价矩阵
(不要用什么“询问专家得权值法”,那评委肯定怀疑你怎么还作弊问老师呢)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号