

MapReduce - MIT 6.824
Intro
Insight
Should all map task be done before starting first reduce task?
When one reduce task is ready to start, it needs input. Input of reduce task is the output of map task, which means reduce task requires map task output. So does it require partial outputs of map tasks or ALL outputs? The answer is ALL. Every map task can generate data for some few specific reduce tasks by calculating the hash of data and retrieving the id of reduce task. Only when all the map tasks are done, the resources required in one reduce task are ready.
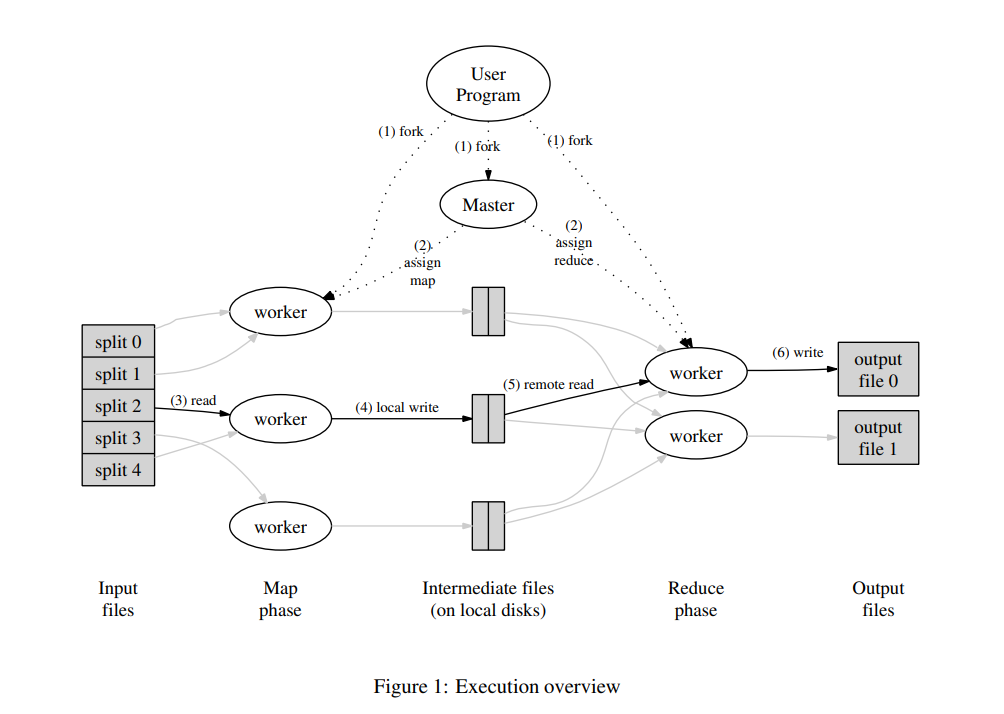
3.1 Execution Overview
The Map invocations are distributed across multiple
machines by automatically partitioning the input data into a set of M splits. The input splits can be processed in parallel by different machines. Reduce invocations are distributed by partitioning the intermediate key
space into R pieces using a partitioning function (e.g.,
hash(key) mod R). The number of partitions (R) and
the partitioning function are specified by the user.
Is it possible that one task would be executed successfully twice?
Yes. No precaution is set to avoid same task being executed twice and overwriting the artifacts.
In addition, We use os.Rename to write the output to file system. If there is a same-name file existing, the secondary will overwrite it.
Are artifacts of one task stably consistent within multiple execution?
Yes. No random factor is introduced other than hash. Fixed output goes same for every specific input.
Let's start from Data Structures
The master keeps several data structures. For each map
task and reduce task, it stores the state (idle, in-progress, or completed), and the identity of the worker machine (for non-idle tasks).
The master is the conduit through which the location
of intermediate file regions is propagated from map tasks
to reduce tasks. Therefore, for each completed map task,
the master stores the locations and sizes of the R intermediate file regions produced by the map task. Updates to this location and size information are received as map tasks are completed. The information is pushed incrementally to workers that have in-progress reduce tasks.
Actually, I did start from the data structure. At that point of time when I set about implementation, I had no idea of what to do. I read the paper back and forth and found the upper remarks. I realized I needed to define the data structure first. Then I can do with these data structures next.
Task Structure
The core concept in MapReduce is map & reduce. Coordinator and workers need to exchange essential information. In programming model, there should be places to carry information. We define a structure called Task to store Id, WorkerId, Type, Input, Output, etc.
Task ID
Every task needs an Id to represent itself. When worker gets a map task, executes the task and feeds task with some inputs which the task object brings, it is about to tell the coordinator the result of this task. Coordinator has to know which task the worker is responding about. Otherwise, result of one task would probably be computed or cumulated twice or more which would be a terrible thing because there will be many map, reduce tasks in such distributed chaos.
Worker ID
There are single coordinator and several workers in this map reduce system. At runtime, many workers are wanting to communicate with coordinator. Then every worker needs a Id to let coordinator able to identify who he is.
This Id should be allocated from coordinator. Coordinator is responsible to maintain these Ids and make sure one Id is assigned to single worker just once exactly.
Then in coordinator, we need a GetWorkerId method. We maintain a maxWorkerId and atomically increase this value on every call so that each call to this method will get an unique Id.
In worker, we need a method to call GetWorkerId of coordinator via RPC and store the result locally in order to tell the coordinator who I am on next other call.
Task Type
We unify map and reduce task into one structure. So it's necessary to define a field to distinct map from reduce.
Data: Input or Output
Map/Reduce task transfers the file splits from coordinator to worker. Worker executor processes the file input, generated intermediate outputs by Map or Reduce function and puts the outputs inside the task structure.
Here the reason I use only one field Data to represent input or output is it's wasteful to store both inputs and outputs for specific either map or reduce task at any time. At the start of task, input is desired. But at the end of
task, output needs to be set and input is unnecessary any more. Then why not unifying two fields to one.
No task status in Task structure
A task should have statuses like: idle, in-progress and completed. On coordinator side, they are necessary, but on worker side, there is only one status: in-progress. So I don't store any task status in the structure and just maintain it on coordinator side by other measures instead.
Coordinator (Dispatcher)
Nature of Correspondence
Workers communicates with coordinator each other through RPC. Then we need to expose some essential APIs in coordinator so that workers could retrieve or pass key data.
Get ready before execution
GetWorkerId
As said in Worker Id, we need to assign an Id to the worker as identification.
GetReduceCount
We also should tell the worker the total count of reduce tasks because the worker wants to partition intermediate outputs generated by Map task into R regions by hash function.
Dispatch
The most significant part in MapReduce system is how to coordinate the workers with tasks. We need to assign task to worker, wait for the result from worker and cancel one task if the time it takes worker to execute the specific task is out of expectation. We also need to maintain the statuses in task pool so that all the tasks could get calculated and we can obtain a correct outcome finally.
Task Pool
I abstract taskContainer structure as task pool for map and reduce respectively. I define idleTasks and completedTasks of chan *Task type to pass tasks with distinct statuses. At runtime, many workers are applying for or committing tasks. So it's important and necessary to create a mechanism to guarantee the thread safety. In Go world, channel is the best practice to get rid of race condition. I add a member named inProgressWaitingFlags of *sync.Map type as well whose function I will illustrate later.
Create Map Task
Coordinator is given file splits as input from program host. Each file needs to be wrapped as Input into a Task object. Having constructed a map task, we put it into idleTasks of map task pool.
AssignTask
Worker need obtain a task from coordinator. Coordinator takes a task from idle pool and send it as a response back to worker. One thing needs to be noted is once a task is assigned to worker, we should start to monitor the finish signal of task on coordinator side because we make a time-out mechanism for these being-executed tasks.
monitorInProgress: In-progress Task Monitor
In distributed environment, executor (aka worker) might exit in all kinds of ways even though the task hasn't been completed so that coordinator will never receive a response as consequence from worker, thus the whole MapReduce job wouldn't get finished ever if this specific task won't be dispatched as an idle task again. It's pretty necessary to re-allocate this unfinished task if the execution time is out of expectation, which is called timeout management.
Once a task is assigned to a worker, it should be marked as in-progress. We monitor the state of the task and check whether task is done in specified time period. If not, we kick the task out from in-progress queue and put it back into idle pool so that this task could be executed on another attempt.
I create a cancel Context and put cancel token into a sync.Map with task id as key so that we can obtain and manipulate the context in other places, e.g. another goroutine. The reason I don't push it into a thread-safe go channel is it takes different time to complete distinct in-progress tasks. If a task that id is equal to 7 is done, we want to remove the specified task from in-progress pool directly rather than iterate the pool, find the task and kick it away. sync.Map is thread-safety and should be the best choice here.
After marking the task in-progress, I start a goroutine to listen to task's finish signal. If the task isn't done in preset time, cancel token of context is loaded. We release the token and send the task back to idle pool.
ReceiveTaskOutput
When one task is done by worker, worker needs to commit this task to coordinator so that the outcome of task job is aggregated and could be passed to next stage, e.g. wrapped in a reduce task. The most important stuff here is to make the task done first so that state monitor won't put it back to idle pool. The next step is to put it to completed pool.
Host shell (main goroutine)
In addition to the invocation from worker due to the demand of exchanging information, shell is responsible for startup, exit, manipulating transformation of tasks' input and output and other stuff in the interim.
createMapTasks
Given the files passed as arguments to shell, we need to wrap each file into a map task structure and send it to idle pool.
createReduceTasks
I set a counter in this function to gather the outputs from all map tasks. As we discussed at the beginning of this document, all map tasks should be completed before first reduce task runs. Once the counter reaches the number of map tasks, subsequence reduce tasks can be produced. In the meanwhile, we also need cache and convert the map task's output so that input of reduce task is got ready.
checkDone
After R reduce tasks are done, we trigger the done signal by cancelling done channel to broadcast the message that all is completed and host shall exit.
Done
Host of coordinator works on a single goroutine (i.e. main goroutine). It checks the done signal in a for loop. After all map and reduce tasks are completed, we set done signal to mark the overall progress over so that main program knows it needs to exit then.
Start - Compose and start the core engine
There is a series of stuff to prepare for the start of coordinator:
- create map task container
- create reduce task container (Actually, we can use single task container to hold map tasks or reduce tasks because the time to use them are not overlapped.)
- start a new goroutine to manipulate map task (i.e.
createMapTasks) - start a new goroutine to manipulate reduce task (i.e.
createReduceTasks) - check if all reduce tasks are done (i.e.
checkDone) - start RPC server
Worker
Actually, the entire implementation of WORKER part is simpler compared to COORDINATOR part. All stuff is very clear because it just takes time instead of MapReduce System Design. Nevertheless, I abstract some interfaces to make the design testable. This will have the final work seem a bit complex but robust.
Setup
Each worker needs an Id to represent itself, then it asks coordinator to allocate an Id by Coordinator.GetWorkerId. The number of reduce tasks is pre-assigned by host in advance. Worker needs to call Coordinator.GetReduceCount so that worker can split the output of one map task into different reduce task inputs (i.e. consequent map task output).
Execution
After setup is done, there should be a loop to retrieve a task, consume the task and commit the task's output until there is no task to be allocated.
Apply for a task
We call Coordinator.AssignTask to issue a task from the idle pool which is demonstrated before. We also check if the task obtained is DoneTask or not. If yes, which means all is done, then the worker can exit.
Execute the task
Steps performed on each task would follow the same principle: parse/decode input, map/reduce transform, encode to output.
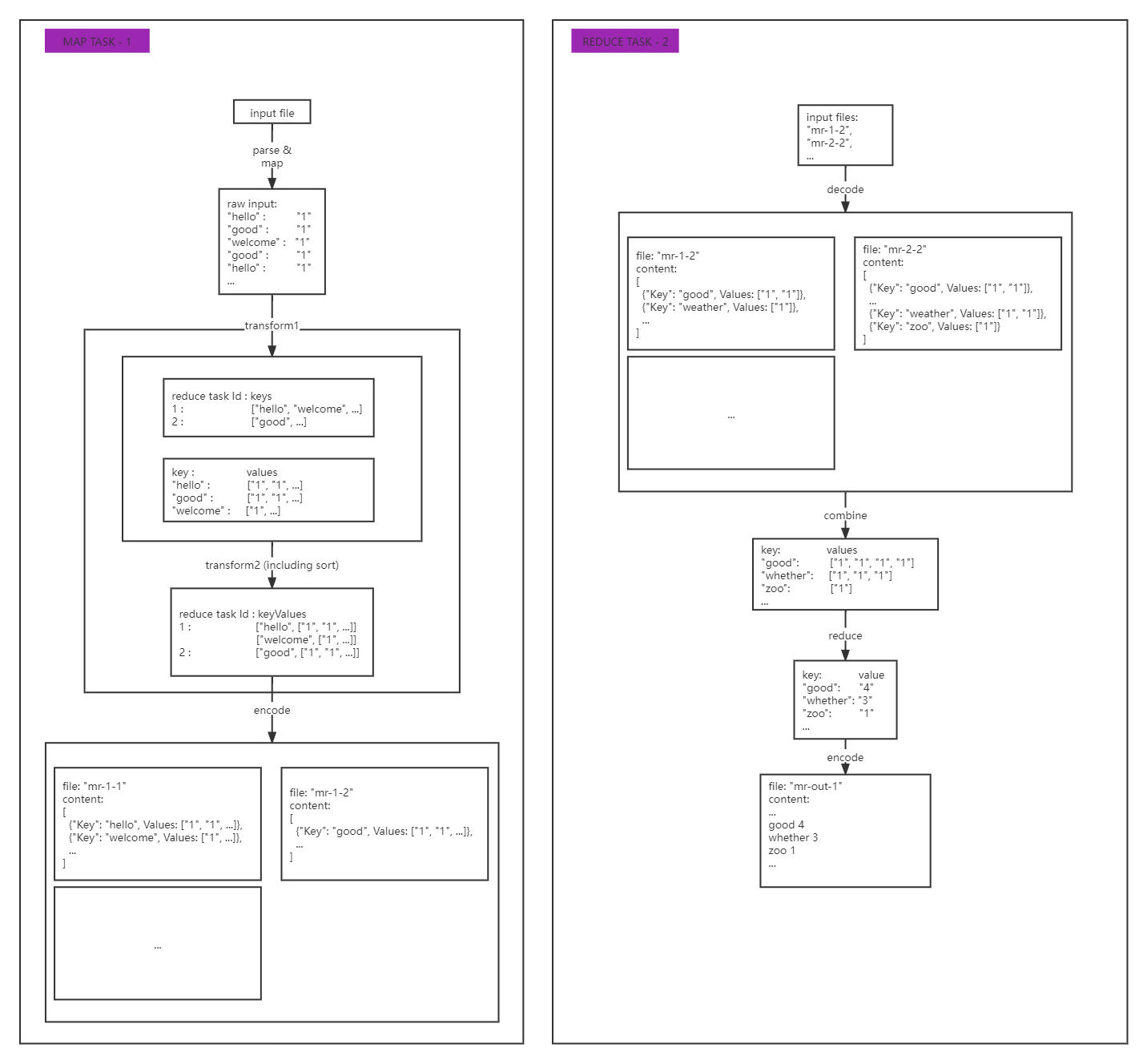
Commit task
We call Coordinator.ReceiveTaskOutput so that coordinator gets the outputs of one specific task and marks it done and prepare the work stuff for next step.
Summary
In fact, it took me a lot of spare time to complete this project. This is also the first experience for me to realize a project completely in go language. It's interesting and fulfilling that I am able to utilize goroutine and channel rather than all kinds of lock or mutex to keep thread safety and avoid race condition. "Do not communicate by sharing memory; instead, share memory by communicating." To be honest, it's practical and we can enjoy such practice. At the end, I really hope this post will help everyone who reads it achieve something valuable and useful.
github repo link: https://github.com/DaneSpiritGOD/MIT-6.824

 浙公网安备 33010602011771号
浙公网安备 33010602011771号