

Attention及Transformer工作原理概述
这篇论文是目前所有大语言模型的基石,ChatGPT、DeepSeek等等,在图像领域也有不错的应用,可以说是继NN、CNN、RNN之后新一轮AI革命的引领者。
Transformer架构和Self-Attention自注意力机制核心思想:提出QKV注意力计算模型,让序列中的每一个词(或元素)都能够与序列中的所有其他词(包括它自己)进行交互,从而根据整个上下文来动态地计算每个词的新表示。
为什么需要自注意力?
在自注意力出现之前,RNN/LSTM 是处理序列的主流方法,但它们有致命缺陷:
顺序处理:必须一个一个词地处理,无法并行,速度慢。
长程依赖问题:尽管 LSTM 有所改善,但距离很远的词之间的关系仍然难以捕捉。
自注意力机制完美地解决了这两个问题:
并行计算:所有词可以同时计算注意力。
全局视野:无论两个词相距多远,它们之间都只需要一步计算就能建立联系。
b站视频讲解:《Attention is all you need》论文解读及Transformer架构详细介绍
Transformer之前主流序列转导模型的结构:1.基于RNN/CNN;2.使用编码器-解码器结构;3.使用注意力机制增强;
Transformer结构的创新:1.完全摒弃RNN/CNN;2.(仍然使用编码器-解码器结构);3.完全基于注意力机制;
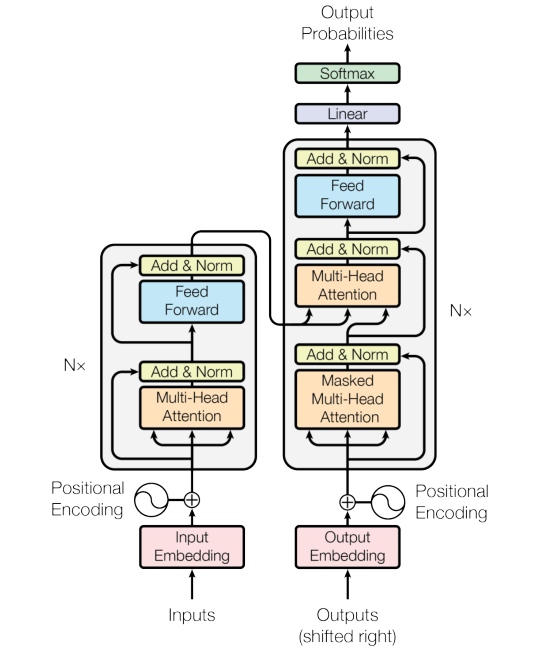
Transformer编码器
1.词嵌入与位置编码
Inputs为输入数据,Input Embedding为词嵌入向量表示,论文中词向量的维度为512,如“今天天气很好”,embedding为6*512的矩阵,这里词向量可以使用已经训练好的,也可以使用随机值初始化跟随模型一起训练,Positional Encoding为位置编码信息矩阵,位置编码由sin/cos函数计算,将Input Embedding与Positional Encoding两个矩阵相加得到最终的输入矩阵化表示。
2.QKV矩阵
Multi-Head Attention下面有三个箭头,这个为 \(W_Q,W_K,W_V\)(论文中这三个矩阵为512x512)与Positional Input Embedding矩阵相乘(例子为6x512),最终得到6x512的\(Q,K,V\)矩阵;
QKV矩阵是什么?Q是Query的缩写,K为Key的缩写,V是Value的缩写;Q矩阵就像是提出了很多问题,Key矩阵在回答这些问题,V矩阵代表词的本身含义
QKV矩阵解决了什么问题? 所有词可以同时计算注意力(也可以理解为相似度系数);无论两个词相距多远,它们之间都只需要一步计算就能建立联系。
形象化理解:
第1步:你把一个词(比如“我”)输入到一个机器里,这个机器复制三份,分别经过三个不同的处理通道,就得到了代表“我”的 Q, K, V 三个向量。
第2步:计算注意力分数,我们用“我”的 Query 向量去和序列中每一个词的 Key 向量做点积(Dot Product)。点积的结果就是“注意力分数”,它表示两个词之间的相关性。
比如句法语法分析,示例“我爱水课”中,水的 \(水_Q\) 矩阵会向 \(我_K,爱_K,水_K,课_K\) 这些Key矩阵发问,“你是名词吗?”得到的结果,\(我_K,爱_K\)回答我不是,\(水_k,课_k\)回答我是。
3.Multi-Head Attention 多头注意力机制
单头注意力机制:
\(Attention(Q,K,V)=softmax(\dfrac{{QK^T}}{\sqrt{d_k}})V\)
\(QK^T\) 就是我们上边所说的Q矩阵像K矩阵发问的数学表示(也可以理解为不同词的注意力分数),最终得到一个6x6的矩阵,矩阵中每个值表示,词与词之间的相似度
\(\sqrt{d_k}\),\(d_k\)是矩阵K的列数,在本例中为6,简而言之,是为了稳定点积的尺度,从而稳定softmax的输入,最终稳定梯度,让模型能够更有效的进行训练和学习。

\(Attention(Q,K,V)\), 带有序列化信息的softmax特征矩阵为6x6,最终再与6x512的V矩阵相乘得到注意力矩阵512x64
多头注意力:
定义多组Q,K,V,让它们分别关注不同的上下文,能够从不同角度、在不同的“表示子空间”中捕获输入序列的各种信息;计算过程是一样的,论文中将原本512x512的QKV矩阵拆成8组为64x512,最终将attention后的8组64*512矩阵做一个线性层融合,并不是简单的拼接而是线性投影
我们可以这样来想象,我们Attention矩阵去学习一张人脸图像,将人脸图像分为8个特点去学习,第一组学习人脸轮廓,第二组学习皮肤颜色皱纹,第三组学习五官等等一共给你八组,最终通过投影的方式合成一张高清的512x512的人脸图像。
4.Add & Norm
将原始的Positional Embedding Inputs矩阵 与 Attention计算的矩阵相加 再做个层归一化操作,让模型更加稳定,包括后面的残差连接
\(LayerNorm(X + Z_Attention)\)
5.Feed Forwad
前馈神经网络网络模块,同样也有个 Add&Norm模块
Transformer解码器
解码器和编码器流程上基本都是一致的,首先将答案“It's a beautiful day today”输入,通过掩码机制进行训练
Transformer 计算示例


 浙公网安备 33010602011771号
浙公网安备 33010602011771号