

Linux c/c++ 高性能后端
RocksDB
RocksDB 是 Facebook 的一个实验项目,目的是希望能开发一套能在服务器压力下,真正发挥高速存储硬件性能的高效数据库系统。这是一个 C++ 库,允许存储任意长度二进制 KV 数据。支持原子读写操作。
RocksDB 依靠大量灵活的配置,使之能针对不同的生产环境进行调优,包括直接使用内存,使用 Flash,使用硬盘或者 HDFS。支持使用不同的压缩算法,并且有一套完整的工具供生产和调试使用。
RocksDB 大量复用了 levedb 的代码,并且还借鉴了许多HBase 的设计理念。原始代码从 leveldb 1.5 上fork 出来。同时RocksDB 也借用了一些 Facebook 之前就有的理念和代码。
RocksDB 应用场景非常广泛;比如支持 redis 协议的 pika 数据库,采用 RocksDB 持久化 Redis 支持的数据结构;MySQL 中支持可插拔的存储引擎,Facebook 维护的 MySQL 分支中支持RocksDB;
rocksDB背景
- 基于leveldb
- 嵌入式kv存储引擎
- 针对写密集型的场景而提出的解决方案:日志系统、海量数据存储、海量数据分析
- 紧凑型存储:相同的数据量,更小的空间占用
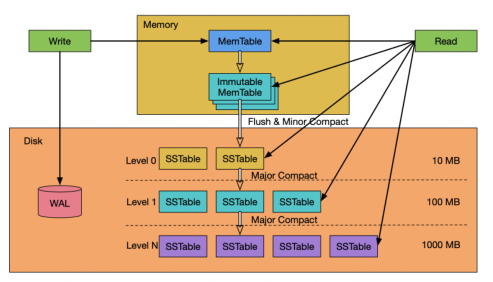
- 基于LSM-Tree的存储引擎,内存使用MemTable,磁盘使用SST、WAL
rocksDB结构及基本接口
RocksDB 是一种可以存储任意二进制KV数据的嵌入式存储。
RocksDB 按顺序组织所有数据,他们的通用操作是 Get(key),NewIterator() , Put(key, value), Delete(Key) 以及SingleDelete(key)。
RocksDB 有三种基本的数据结构:memtable,sstfile 以及logfile。memtable 是一种内存数据结构——所有写入请求都会进入 memtable,然后选择性进入 logfile。logfile 是一个在存储上顺序写入的文件。当 memtable 被填满的时候,他会被刷到sstfile 文件并存储起来,然后相关的 logfile 会在之后被安全地删除。sstfile 内的数据都是排序好的,以便于根据 key 快速搜索。
RocksDB 是基于 lsm-tree (log structured merge - tree) 实现;
LSM-Tree(Log Structured Merged Tree)
MySQL的存储引擎innoDB是基于B+树存储查询,rocksDB存储引擎是基于LSM-Tree
LSM-Tree 的核心思想是利用顺序写来提升写性能;LSM-Tree 不是一种树状数据结构,仅仅是一种存储结构;LSM-Tree 是为了写密集型的特定场景而提出的解决方案;如日志系统、海量数据存储、数据分析;
LO 层数据重复,文件间无序,文件内部有序;
L1 ~ LN 每层数据没有重复,跨层可能有重复;文件间是有序的;
关于访问速度
- 磁盘访问时间:寻道时间 + 旋转时间 + 传输时间;
- 寻道时间:8ms~12ms;
- 旋转时间:7200转/min(半周 4ms);
- 传输时间:50M/s(约0.3ms);
- 磁盘随机 IO << 磁盘顺序 IO ≈ 内存随机 IO << 内存顺序 IO;
MemTable
MemTable 是一个内存数据结构,他保存了落盘到 SST 文件前的数据。他同时服务于读和写——新的写入总是将数据插入到memtable,读取在查询 SST 文件前总是要查询memtable,因为 memtable 里面的数据总是最新的。一旦一个 memtable 被写满,他会变成不可修改的,并被一个新的 memtable 替换。一个后台线程会把这个 memtable的内容落盘到一个 SST 文件,然后这个 memtable 就可以被销毁了。
默认的 memtable 实现是基于 skiplist 的。影响 memtable 大小的选项:write_buffer_size: 一个 memtable 的大小;db_write_buffer_size: 多个列族的memtable 的大小总和;这可以用来管理 memtable 使用的总内存数;max_write_buffer_number: 内存中可以拥有刷盘到 SST 文件前的最大 memtable 数
落盘策略
- Memtable 的大小在一次写入后超过 write_buffer_size。
- 所有列族中的 memtable 大小超过 db_write_buffer_size了,或者 write_buffer_manager 要求落盘。在这种场景,最大的 memtable 会被落盘;
- WAL 文件的总大小超过 max_total_wal_size。在这个场景,有着最老数据的 memtable 会被落盘,这样才允许携带有跟这个memtable 相关数据的 WAL 文件被删除。
WAL(logfile)
mysql的innodb 也是这样做的
RocksDB 中的每个更新操作都会写到两个地方:
- 一个内存数据结构,名为 memtable (后面会被刷盘到SST文件)
- 写到磁盘上的 WAL 日志。
在出现崩溃的时候,WAL 日志可以用于完整的恢复 memtable中的数据,以保证数据库能恢复到原来的状态。在默认配置的情况下,RocksDB 通过在每次写操作后对 WAL 调用fflush来保证一致性。
WAL 创建时机: - db打开的时候;
- 一个列族落盘数据的时候;(新的创建、旧的延迟删除)
重要参数
- DBOptions::max_total_wal_size: 如果希望限制 WAL 的大小,RocksDB 使用 DBOptions::max_total_wal_size 作为列族落盘的触发器。一旦 WAL 超过这个大小,RocksDB 会开始强制列族落盘,以保证删除最老的 WAL 文件。这个配置在列族以不固定频率更新的时候非常有用。如果没有大小限制,如果这个WAL中有一些非常低频更新的列族的数据没有落盘,用户可能会需要保存非常老的 WAL 文件。
- DBOptions::WAL_ttl_seconds,DBOptions::WAL_size_limit_MB:这两个选项影响 WAL 文件删除的时间。非0参数表示时间和硬盘空间的阈值,超过这个阀值,会触发删除归档的WAL文件。
Immutable MemTable
Immutable MemTable 也是存储在内存中的数据,不过是只读的内存数据;当 MemTable 写满后,会被置为只读状态,变成 ImmutableMemTable。然后会创建一块新的MemTable 来提供写入操作;
Immutable MemTable 将异步 flush 到 SST 中;
SST
SST (Sorted String Table) 有序键值对集合;是 LSM-Tree 在磁盘中的数据结构;可以通过建立 key 的索引以及布隆过滤器来加快 key 的查询;LSM-Tree 会将所有的 DML 操作记录保存在内存中,继而批量顺序写到磁盘中;这与 B+ Tree 有很大不同,B+ Tree 的数据更新直接需要找到原数据所在页并修改对应值;而 SM-Tree 是直接 append 的方式写到磁盘;虽然后面会通过合并的方式去除冗余无效的数据;
文件格式
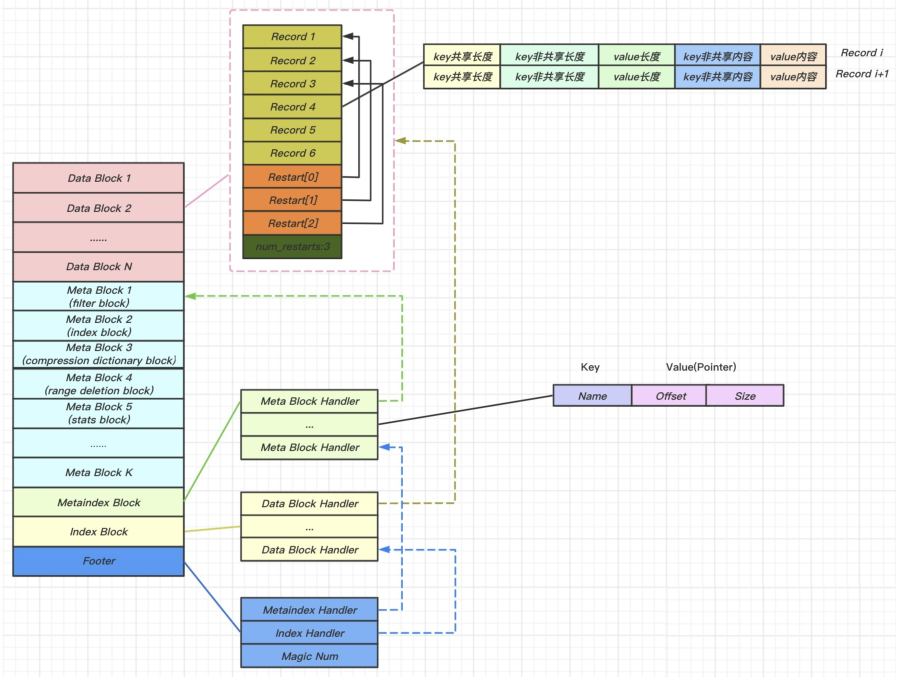
<beginning_of_file>
[data block 1]
[data block 2]
...
[data block N]
[meta block 1: filter块]
[meta block 2: stats块]
[meta block 3: 压缩字典块]
[meta block 4: 范围删除块]
...
[meta block K: 未来拓展块] (我们以后可能会加入新
的元数据块)
[metaindex block]
[index block]
[Footer] (定长脚注,从
file_size - sizeof(Footer)开始)
<end_of_file>
BlockHandle
offset: varint64
size: varint64
BlockCache
块缓存是 RocksDB 在内存中缓存数据以用于读取的地方。用户可以带上一个期望的空间大小,传一个 Cache 对象给 RocksDB实例。一个缓存对象可以在同一个进程的多个 RocksDB 实例之间共享,这允许用户控制总的缓存大小。块缓存存储未压缩过的块。用户也可以选择设置另一个块缓存,用来存储压缩后的块。读取的时候会先拉去未压缩的数据块的缓存,然后才拉取压缩数据块的缓存。在打开直接 IO 的时候压缩块缓存可以替代 OS 的页缓存。
RocksDB 里面有两种实现方式,分别叫做 LRUCache 和ClockCache。两个类型的缓存都通过分片来减轻锁冲突。容量会被平均的分配到每个分片,分片之间不共享空间。默认情况下,每个缓存会被分片到 64 个分片,每个分片至少有 512 B 空间。用户可以选择将索引和过滤块缓存在 BlockCache 中;默认情况下,索引和过滤块都在 BlockCache 外面存储;
LRU
默认情况下,RocksDB 会使用 LRU 块缓存实现,空间为 8MB。每个缓存分片都维护自己的 LRU 列表以及自己的查找哈希表。通过每个分片持有一个互斥锁来实现并发。不管是查找还是插入,都需要申请该分片的互斥锁。用户可以通过调用 NewLRUCache创建一个 LRU 缓存;
Clock缓存
ClockCache 实现了CLOCK算法。每个clock缓存分片都维护一个缓存项的环形列表。一个clock指针遍历这个环形列表来找一个没有固定的项进行驱逐,同时,如果在上一个扫描中他被使用过了,那么给予这个项两次机会来留在缓存里。
tbb::concurrent_hash_map 被用来查找数据。
与 LRU 缓存比较,clock 缓存有更好的锁粒度。在 LRU 缓存下面,每个分片的互斥锁在读取的时候都需要上锁,因为他需要更新他的 LRU 列表。在一个 clock 缓存上查找数据不需要申请该分片的互斥锁,只需要搜索并行的哈希表就行了,所以有更好锁粒度。只有在插入的时候需要每个分片的锁。用 clock 缓存,在一定环境下,我们能看到读性能的增长;
写入流程
- 写入位于磁盘中的 WAL(Write Ahead Log)里。
- 写入 memtable。
- 当大小达到一定阈值后,原有的 memtable冻结变成immutable。后续的写入交接给新的 memtable和WAL。
- 后台开启 Compaction 线程,开始将 immutable落库变成一个L0 层的 SSTable,写入成功后释放掉以前的 WAL。
- 若插入新的 SSTable后,当前层( Li)的总文件大小超出了阈值,会从 Li中挑选出一个文件,和 Li+1层的重叠文件继续合并,直到所有层的大小都小于阈值。合并过程中,会保证 L1以后,各 SSTable的Key不重叠。
读取流程
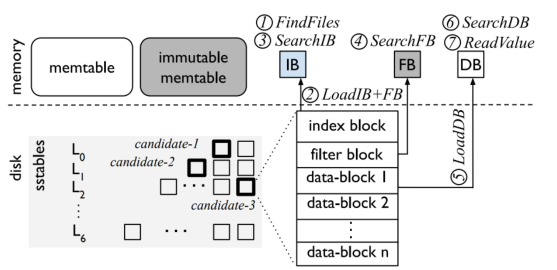
- FindFiles。从SST文件中查找,如果在 L0,那么每个文件都得读,因为 L0 不保证Key不重叠;如果在更深的层,那么Key保证不重叠,每层只需要读一个 SST 文件即可。L1 开始,每层可以在内存中维护一个 SST的有序区间索引,在索引上二分查找即可;
- LoadIB + FB。IB 和 FB 分别是 index block 和 filterblock 的缩写。 index block是SST内部划分出的block的索引; filter block 则是一个布隆过滤器(Bloom Filter),可以快速排除 Key 不在的情况,因此首先加载这两个结构;
- SearchIB。二分查找 index block,找到对应的 block;
- SearchFB。用布隆过滤器过滤,如果没有,则返回;
- LoadDB。则把这个 block加载到内存;
- SearchDB。在这个 block中继续二分查找;
- ReadValue。找到 Key后读数据,如果考虑 WiscKey KV分离的情况,还需要去 vLog 中读取;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号