《Non-local Neural Networks》论文阅读笔记
原文链接: 《Non-local Neural Networks》
这是收录在2018年CVPR中的一篇文章,受计算机视觉中Non-local means算法启发,文中提出non-local block以获取long-range dependencies。由non-local block构建的模型在Kinetics、Charadees数据集和COCO相关任务中都取得较好的效果。
1.研究背景和研究动机
获取long-range dependencies在深度神经网络中至关重要。针对不同数据,获取long-range dependencies的方式也不同。
序列数据主要通过循环操作获取;图像数据主要是通过卷积操作堆叠获取。
卷积和循环操作都是在空间或时间上处理局部邻域;只有重复应用这些操作,才能获取long-range dependencies。重复这些局部区域的操作有以下限制因素:
- 计算效率低;
- 优化更加困难
- 信息在相聚较远位置时难以传递
所以设计了non-local block作为一种高效、简单和通用的组件,用于深度神经网络获取long-range dependencies。
2.使用non-local 的优点
- 与循环和卷积操作相比,non-local操作通过计算任意两个位置之间的交互直接获取long-range dependencies,而不管它们的位置分布如何;
- 即使很少层数也能取得较好的效果;
- 输入大小可变,并且可以很容易地与其他操作(例如,卷积)相结合。
3. non-local networks
定义深度神经网络的non-local操作公式如下:
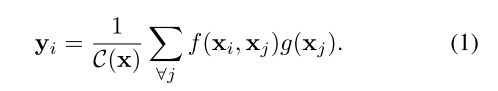
i代表计算其响应的输出位置(空间、时间或时空)的索引,j 是枚举所有可能位置的索引。x是输入信号(图像、序列、视频;通常是它们的特征),y是与x大小相同的输出信号。 ![]() 计算i和所有j之间的标量(表示关系,相关或影响程度)。
计算i和所有j之间的标量(表示关系,相关或影响程度)。![]() 计算位置j处的特征。最后通过
计算位置j处的特征。最后通过![]() 做标准化处理。
做标准化处理。
论文在这个地方也说明了non-local与卷积、循环以及全连接层的不同之处。
- non-local将所有的位置(j)都考虑到;卷积操作是对输入的局部相邻区域进行加权求和;循环操作总是基于当前时间和前一时间进行操作。
- non-local使用相关的函数来表示不同位置间的关系;全连接层则是使用学习到的权重,丢失了不同位置间的相关性;
- non-local的输入是可变化的,并且保证其输出也具有相同的size;全连接层需要固定输入、输出的大小;
- non-local可以用于深度神经网络中的浅层部分;全连接层往往被设置在最后。
论文中将![]() 设置为线性形式,即
设置为线性形式,即![]() ,其中
,其中![]() 是可学习的权重矩阵,对于公式(1)中
是可学习的权重矩阵,对于公式(1)中![]() 函数的选取,论文中提供了四种方案,分别是:
函数的选取,论文中提供了四种方案,分别是:
- Gaussian
![]()
设置![]() 。
。
- Embedded Gaussian
![]()
![]()
![]()
设置![]() ,论文还说明了self-attention模块是嵌入式高斯形式non-local操作的特例;(附上self-attention的表达式:
,论文还说明了self-attention模块是嵌入式高斯形式non-local操作的特例;(附上self-attention的表达式:![]() )
)
- Dot product
![]()
设置![]() ,N是x中的位置数量,这样做简化了梯度计算。
,N是x中的位置数量,这样做简化了梯度计算。
- Concatenation
![]()
设置![]() ,[...,...]表示concatenate,
,[...,...]表示concatenate,![]() 是一个权重向量,它将连接向量转化为一个标量。
是一个权重向量,它将连接向量转化为一个标量。
- 但是通过实验证明,non-local模型对于f、g函数的选择并不敏感,真正使性能提升的原因还是在于non-local这一操作。
定义non-local block如下:
![]()
![]() 是由公式一的non-local操作得到的,与
是由公式一的non-local操作得到的,与![]() 进行一个残差连接( Residual connection),残差连接可以将一个新的non-local block插入其他任何预训练模型中。
进行一个残差连接( Residual connection),残差连接可以将一个新的non-local block插入其他任何预训练模型中。
下图是论文中提供的non-local block样例:
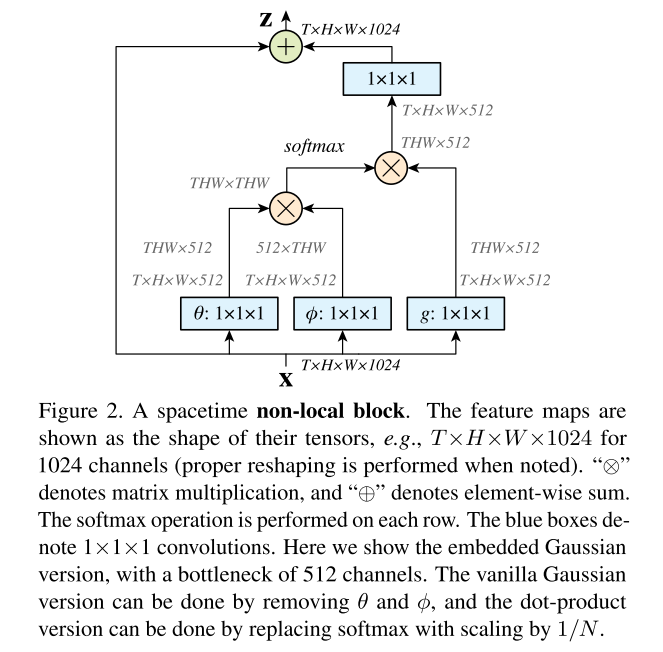
文中提出提升non-local block的方法:
- 将 Wg、Wθ 和 Wφ 表示的通道数设置为 x 中通道数的一半;
- 使用subsampling trick进一步减少计算量。
4.介绍实验针对视频分类所使用的baseline网络
- 2D ConvNet baseline (C2D):以ResNet-50为主干网络,输入 视频剪辑有 32 帧,每帧 224×224 像素。具体结构如下图:

- Inflated 3D ConvNet (I3D):通过inflate操作将上面的C2D模型转化为3D卷积模型;文中提出了两种inflate方式:(1)将残差块中3×3的卷积核inflate成3×3×3;(2)将残差块中1×1的卷积核inflate成3×1×1。
将non-local block插入上述的C2D和I3D网络中,就构建出non-local 网络。
5.实验具体操作细节
- 训练:模型在ImageNet上进行训练;输入是32帧的视频剪辑片段,尺寸是224×224;总共训练400k次迭代次数;初始学习率为0.01,并且每150k衰减10倍学习率;动量和权重衰减分别设置为0.9和0.0001;在全局池化层之后采用 dropout 技术,dropout 比率为 0.5;同时使用 BatchNorm (BN) 来微调的模型。
- 验证:在空间域,将视频短边缩放到256进行卷积推理;在时间域,从全长视频中均匀采样 10 个剪辑,分别计算它们的 softmax 分数。 最终预测是所有剪辑的平均 softmax 分数。
6.在Kinetics数据集上的实验及结果分析
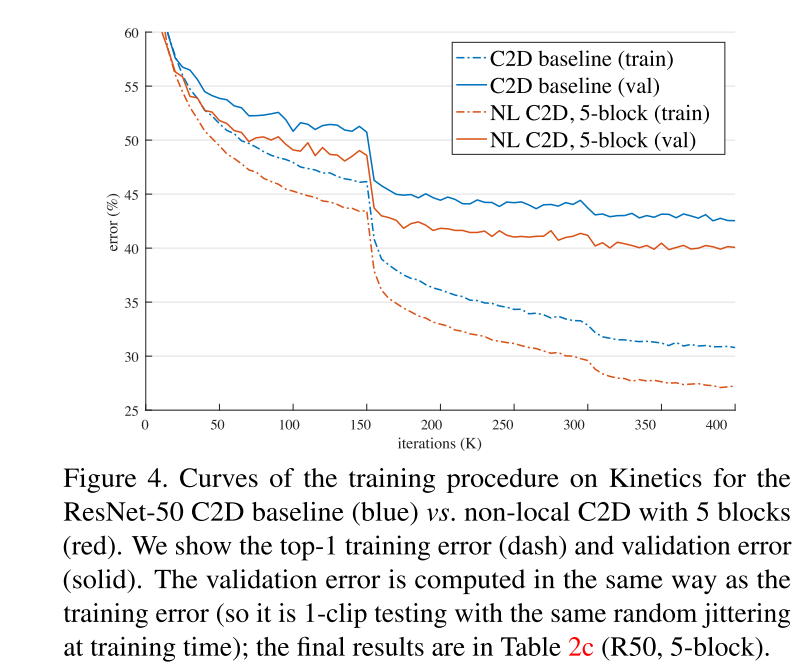
- 图 4 显示了 ResNet-50 C2D baseline与具有 5 个non-local block的 C2D baseline的训练过程曲线。 在整个训练过程中,我们的non-local block C2D 模型在训练和验证错误方面始终优于 C2D baseline。
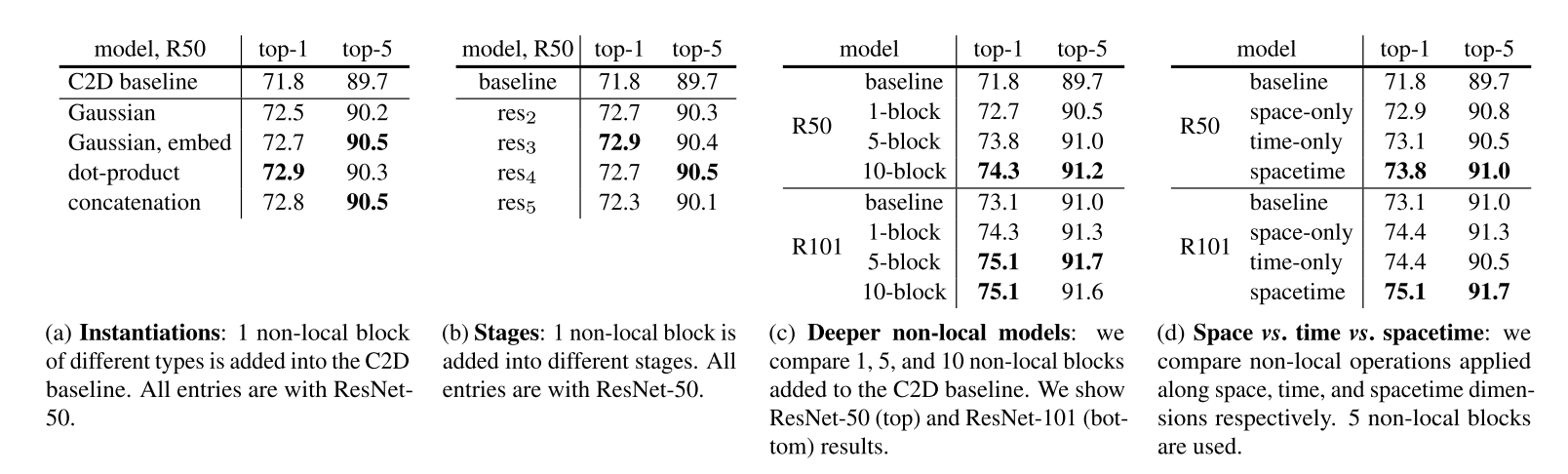
- Table 2a 比较了添加到 C2D baseline的不同类型的单个non-local block。 即使只添加一个non-local block也可以比baseline提高 1%。(这一地方也验证了真正使性能提升的在于non-local这一操作,而不是non-local的类型(因为使用不同non-local得到的结果很接近));
- Table 2b 比较了添加到 ResNet 不同阶段的单个non-local block。 block被添加到的最后一个残差块之前。 non-local block在 res2、res3 或 res4 上的结果提升很相似,在 res5 上较差一些。 一种可能的解释是 res5 的空间尺寸很小(7×7),不足以提供精确的空间信息。(说明non-local block应该被insert到哪个地方);
- Table 2c 显示插入更多non-local block的结果。 插入方法是在 ResNet-50 中添加 1 个块(到 res4)、5 个块(3 个到 res4 和 2 个到 res3,每隔一个残差块)和 10 个块(到 res3 和 res4 中的每个残差块); 在 ResNet-101 中,以相同的方式将它们添加到相应的残差块中。 得到的结论是更多的non-local block会导致更好的结果。 论文说明多个non-local block可以帮助传递在时空中的较远位置的信息。 非局部块的改进不仅仅是因为它们增加了基线模型的深度。;
- Table 2d 表示将non-local block应用在spacetime比单纯应用在space和time上效果好,non-local block可以获取时空信号。
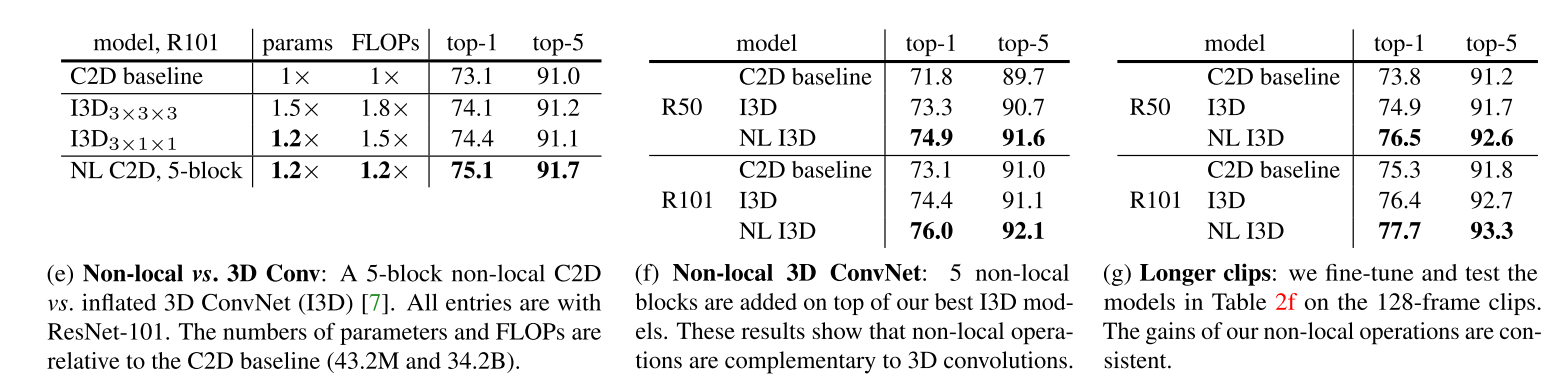
- Table 2e 比较了使用non-local block C2D模型和3D卷积模型在参数、计算量以及精度的结果。证明non-local block+C2D比3D卷积模型更有效(精度比3D模型更高,计算量却更少);
- Table 2f 中non-local block+I3D的组合相较于原来相应的I3D模型有更好地精度提升,验证non-local block和3D卷积是互补的;
- Table 2g 显示了 输入128 帧剪辑的结果,与表 2f 中的 输入32 帧对应模型结果比较得出,所有模型在更长的输入上都有更好的结果。 这表明论文提出的模型在更长的序列上表现更好。
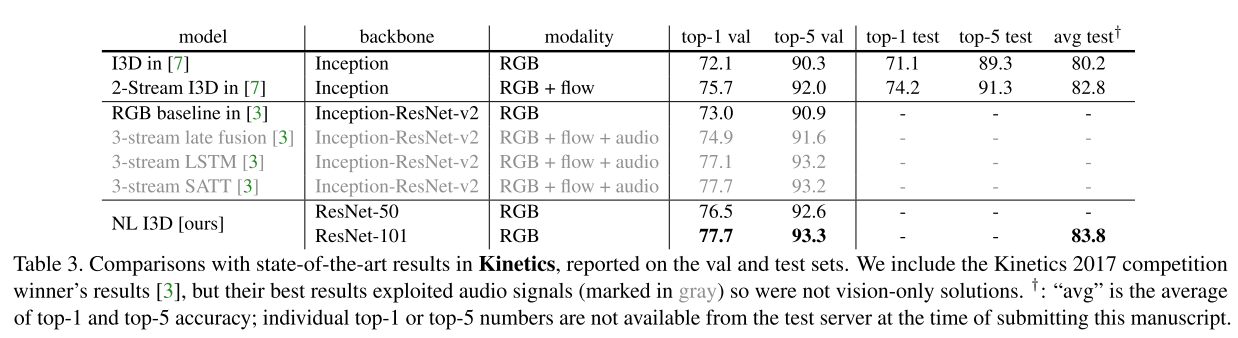
- Table 3 中显示non-local block+I3D的模型在没有使用光流和其他方法的情况下,仍然比现存的使用RGB或者RGB+光流的方法要好,并且和2017年比赛竞赛第一名的结果相当。
后面的实验是在Charades数据集和COCO相关任务中进行的,主要还是验证使用non-local block能带来更好的结果。
参考及引用:
https://zhuanlan.zhihu.com/p/33345791
https://blog.csdn.net/elaine_bao/article/details/80821306

 浙公网安备 33010602011771号
浙公网安备 33010602011771号