
人工智能学习—华为AI Day9
一、大模型概述
1、案例:chatcgpt 写诗歌、写代码、调bug依赖于大模型技术;
大模型是什么?
如何发展到现在?
大模型的分层结构
2、大模型是深度学习子类
代表最先进的人工智能,庞大的参数规模、上亿级文本语料、大规模算力机器,在上述三点相结合的体系下训练的模型体系,表现高度的理解及生成能力,和极强的泛化能力;

3、AI发展历史

4、大模型依赖GPT
Generative:生成式,输入连贯内容,输出文章或回答内容,符合人类语言逻辑的文本,例如:Deepseek、Kimi都在收集和输出用户所需的结构化的文本内容;
Pre-trained:预训练,在后端存储大数据存储集群中,从网上爬取数据、各种商家数据、潜在专业用户查询数据、线下各种买卖数据等,时刻在充实着大数据集群,为预训练提供数据;
Transformer:核心架构(处理能力),基于注意力机制的神经网络架构,有效的处理长文本序列,能够捕捉到文本中不同位置之间的关系,生成更加准确和连贯的文本;

5、人工智能模型的开发范式演变
海量数据的大模型适配不同的业务场景(多模态),通过Pre-trained学习海量数据生产出对应的模型,从而降级训练产生的成本;

二、大模型训练关键技术
1、大模型核心结构:Transformer结构,self-Attention自我学习;
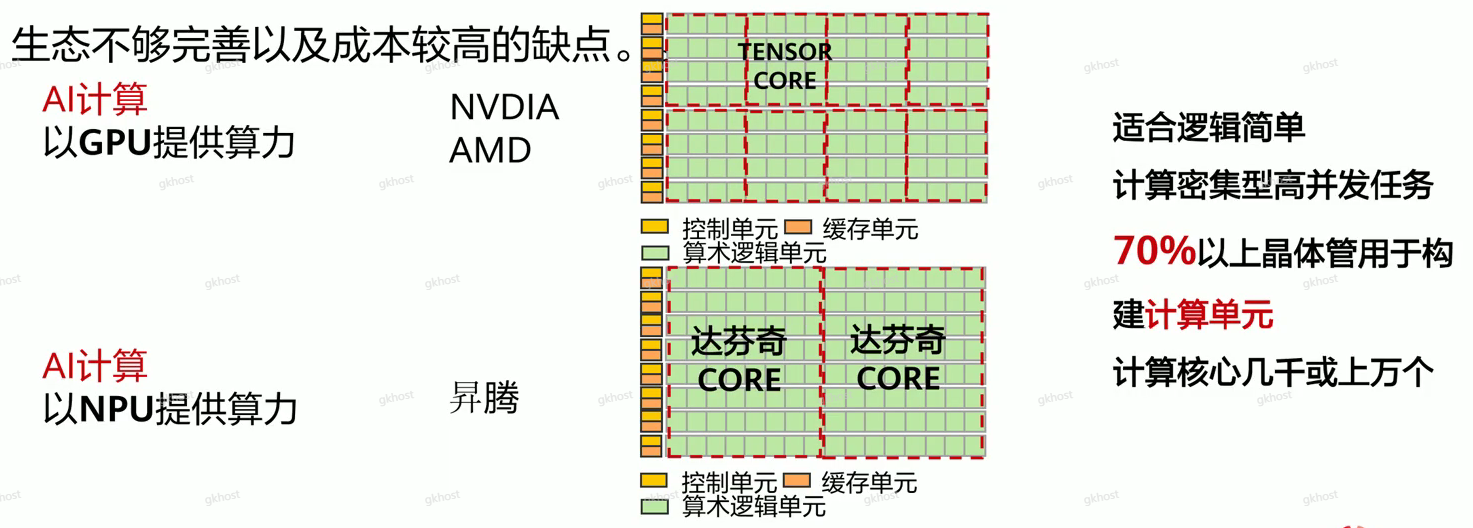
AI计算芯片:
GPU(Graphics Processing Units,图形处理器):拥有成百上千个小核心,多核心并行处理,擅长同时处理大量相似任务,天然契合需要大规模密集运算的AI训练;
NPU(Neural-Network Processing Units, 神经网络处理器):在电路层模拟人类神经元和突触一条指令完成一组神经元的处理,在处理神经网络任务时往往比GPU更节能,但是存在灵活性相对较低,升天不够完善以及成本较高的缺点。
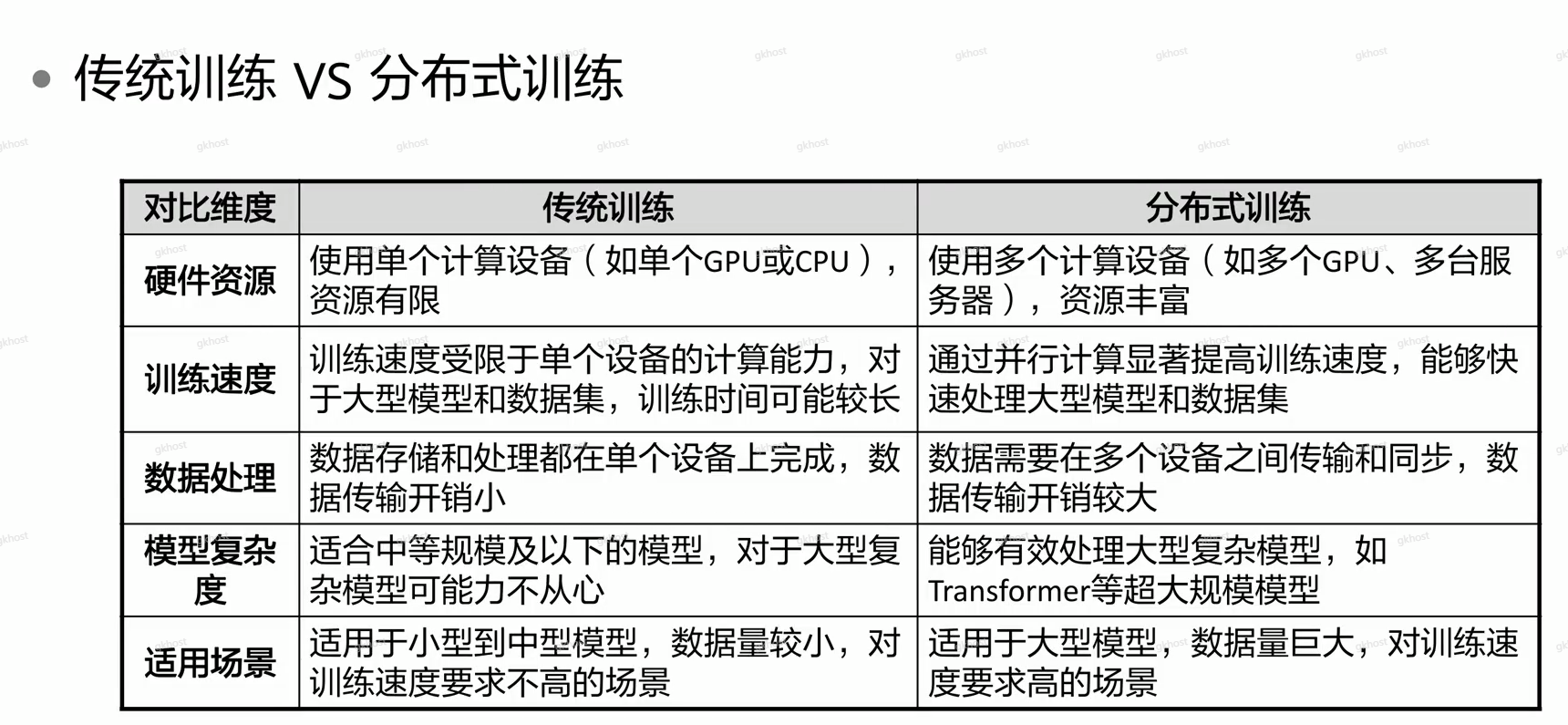
2、训练方式
分布式训练:提高模型训练速度,用来解决多算力紧缺,通过多台机器并行处理训练计算,
例如:原来10天需要处理任务,通过增加硬件算力,将计算时间缩短为1天,在分布式计算期间,将任务分成多份,分给不同算力节点的AI芯片进行计算,定期汇总计算结果,最终汇总学习成果;
数据并行:梯度,类似“多个学生分章节复习同一本书,最后互相分享笔记”。
模型并行:模型分布在不同的AI上,几个AI并行处理;
3、主流并行框架
DeepSpeed:分布式并行框架,提高大模型训练效率,有三种方式:数据并行、模型并行、混合并行;



 浙公网安备 33010602011771号
浙公网安备 33010602011771号