
mysql数据库索引调优
一、mysql索引
1、磁盘文件结构
innodb引擎:frm格式文件存储表结构,ibd格式文件存储索引和数据。
MyISAM引擎:frm格式文件存储表结构,MYI格式文件存储索引,MYD格式文件存储数据
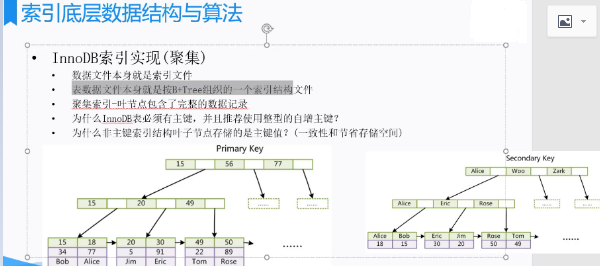
2、mysql数据库数据范问原理(innodb、BTREE)
(1)ibd文件中主键构建b+tree,主键树的叶子结点包含了所有的主键值,存储主键值和对应的表数据
(2)其他索引构建b+tree,树的叶子结点包含了所有该索引字段的值,存储索引值和主键值。
原理图如下图所示:
3、索引类型
普通索引:无任何限制的索引
唯一索引:列值唯一的索引,可以为空值
主键索引:表的主键,特殊的唯一性索引,不能为空值
组合索引:多个字段上的索引,遵循左前缀集合
全文索引:来查找文本中的关键字
4、使用explain+sql语句进行调优
(1)explain包含的信息包含:
![]()
主要从id、type、key、rows、Extra分析。
(2)id
表示执行的先后顺序,id值大的先执行,小的后执行,id值相同的从上到下执行。
(3)type
访问类型,结果值从好到坏依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL。
建议尽量达到range级别,常见类型介绍如下:
const:通过索引一次找到,通常用于主键或唯一性索引。
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描。
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。
range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。一般就是在where语句中出现了bettween、<、>、in等的查询。
index:Index与ALL虽然都是读全表,但index是从索引中读取,而ALL是从硬盘读取。
all:Full Table Scan,遍历全表以找到匹配的行 。
(4)key
实际使用的索引,如果为NULL,则没有使用索引。查询中如果使用了覆盖索引,则该索引仅出现在key列表中 。
(5)rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数。
(6)Extra
Using index: 表示相应的select操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高 。Using where,表明索引被用来执行索引键值的查找,如果没用同时出现Using where,表明索引用来读取数据而非执行查找动作。
Using where:表示使用了where条件过滤。
Convering Index:覆盖索引表示直接从索引中读取数据,sql中查询字段、where条件等涉及的字段都在覆盖索引包含的字段里面。
Using Index Condition:优化器在索引存在情况下通过符合range范围的条数和总数比例来确定进行索引还是全表遍历。
Using filesort:无法利用索引完成的排序操作。
Using temporary:使用临时表保存中建结果,如order by和group by,出现临时表需要优化sql。
5、组合索引
(1)使用组合索引时需要遵循索引最左匹配原则,使用了最左原则type可以为eq_ref (组合索引为唯一索引)、ref、index,可以使用算法来
查询索引值。如果组合索引为(a,b),使用where a ='value'或者where a ='value' and b='value1'时type为ref。
(2)使用组合索引时需要遵循索引最左匹配原则,没有使用了最左原则type可以为index,直接扫描索引全表查找索引值。如果组合索引为(a,b),使用where b ='value1'或者where a ='value' or b ='value1' 时type为index。
(3)组合索引和多个单列索引
在(a,b,c)3列上建立组合索引和3个单列索引时,where条件为a、b、c3列时,组合索引性能更优,3个单列索引只会走一个最优的单列索引。
6、mysql不走索引的原因
1) 没有查询条件,或者查询条件没有建立索引。
2) 在查询条件上没有使用引导列。
3) 查询的数量是大表的大部分,应该是30%以上。
4) 索引本身失效。
5) 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
错误的例子:select * from test where id-1=9; 正确的例子:select * from test where id=10。
6) 对小表查询。
10)隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误。
由于表的字段tel_num定义为varchar2(20),但在查询时把该字段作为number类型以where条件传给数据库,这样会导致索引失效,
错误的例子:select * from test where tel_nume=13333333333;正确的例子:select * from test where tel_nume='13333333333'。
11) 注意使用的特殊符号
1、<> 、!=。
2、单独的>,<,(有时会用到,有时不会)。
12)like "%_" 百分号在前.
select * from t1 where name like 'linux培训%'。
13) not in ,not exist。
15)当变量采用的是times变量,而表的字段采用的是date变量时.或相反情况。
16)B-tree索引is null不会走,is not null会走。
17)联合索引 is not null 只要在建立的索引列(不分先后)都会走
in null时 必须要和建立索引第一列一起使用,当建立索引第一位置条件是is null 时,其他建立索引的列可以是is null(但必须在所有列 都满足is null的时候),或者=一个值;当建立索引的第一位置是=一个值时,其他索引列可以是任何情况(包括is null =一个值),以上两种情况索引都会走。其他情况不会走。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号