Druid.io通过NiFi摄取流数据
NiFi是一个易于使用,功能强大且可靠的系统来处理和分发数据。
本文讲述如何用NiFi将Http的Json数据传到Druid。国外的一篇文章讲到如何用NiFi将推文传到Druid,https://community.hortonworks.com/articles/177561/streaming-tweets-with-nifi-kafka-tranquility-druid.html,数据来源稍有不同,但是走下来的流程大同小异,国情的原因我们使用自己Http来源代替:)
1、系统和环境
系统环境
- centos7
- jdk1.8.0_131
Http数据来源
关键软件
- NiFi.1.2.0汉化版
- Druid.0.12.0
- tranquility.0.8.0
2、摄取步骤
软件安装
略。网上可查,问题不大。
整体流程图
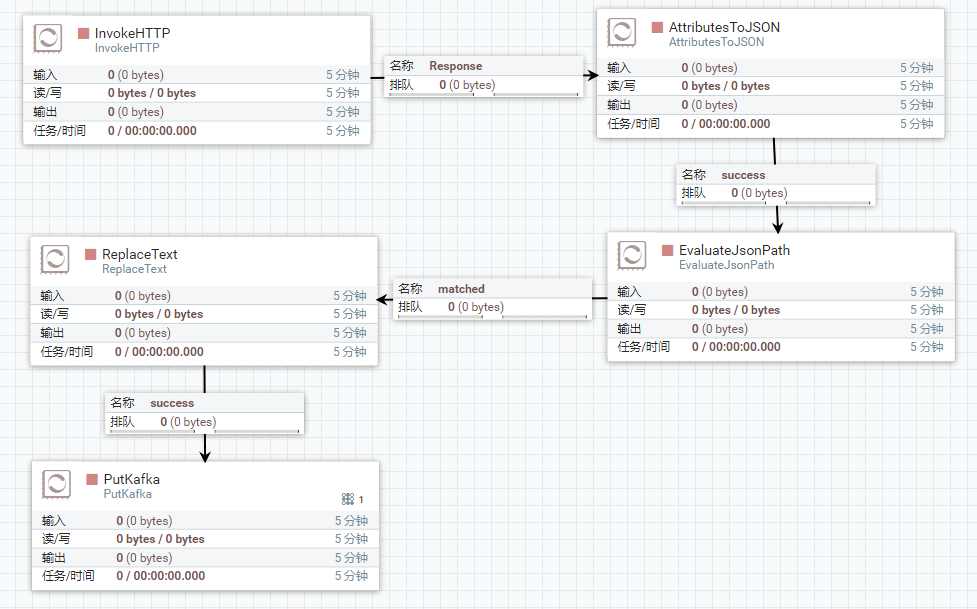
数据来源
2.1、之所以选用IPProxyTool,一是数据返回json,二是较短时间可以产生新的数据。如果有更好的模拟数据,可以替换这个数据来源。

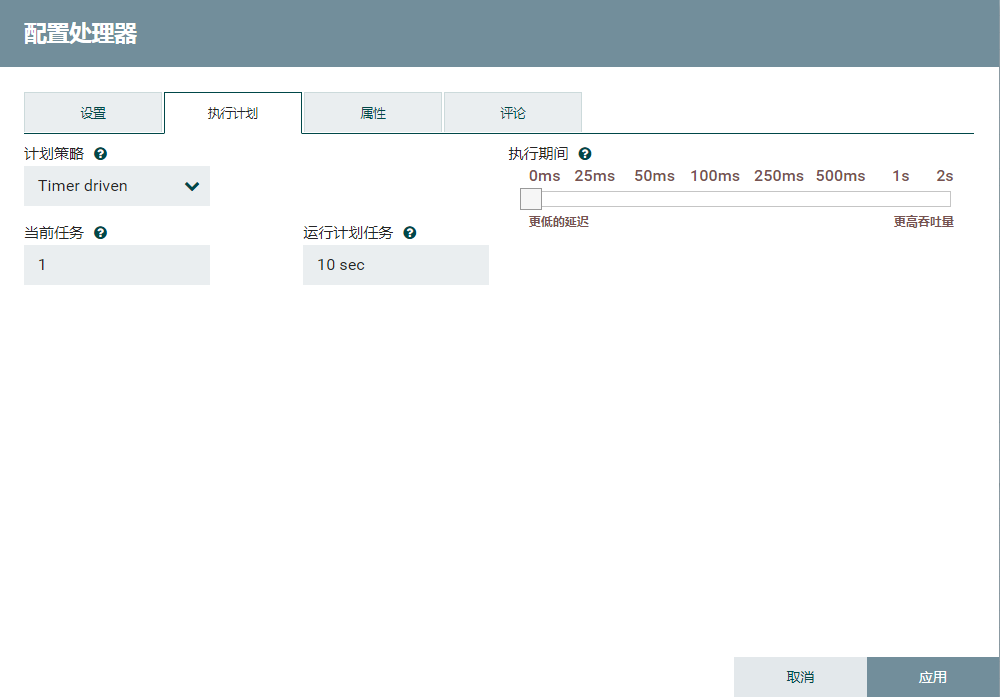
schedule的tab页改为10s,即10s后同步一次数据。
2.1、转换json
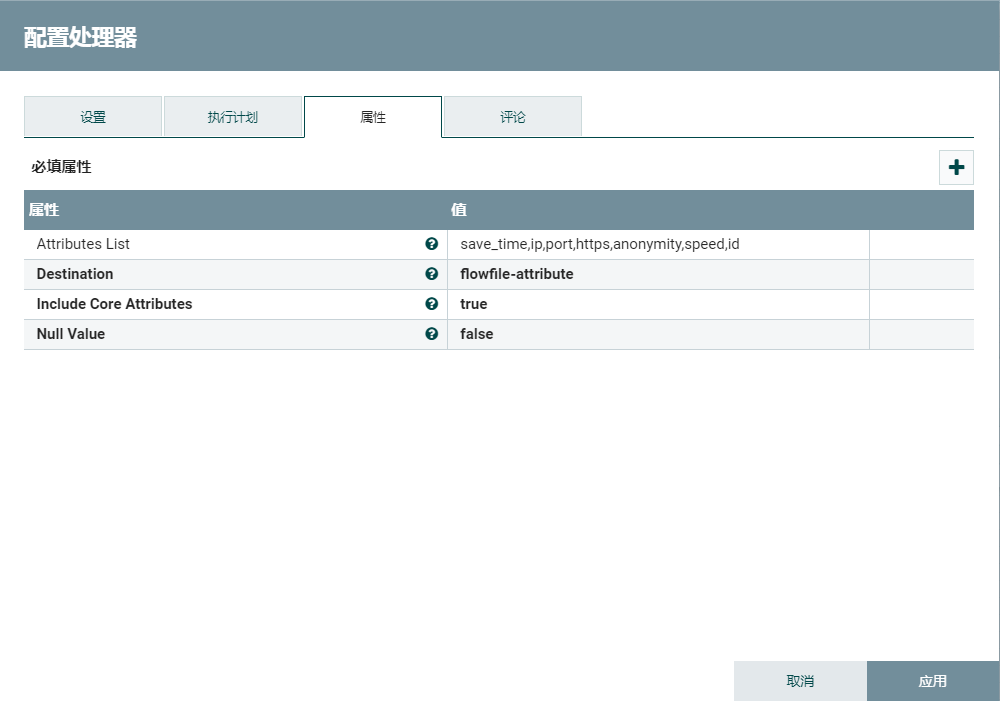
使用AttributesToJSON提取相关的json字段。
2.2、提取json
EvaluateJsonPath只提取json数组中第一个json对象。Druid不接受json数组,相关Druid数据格式支持http://druid.io/docs/0.12.1/ingestion/data-formats.html

2.3、扁平化json
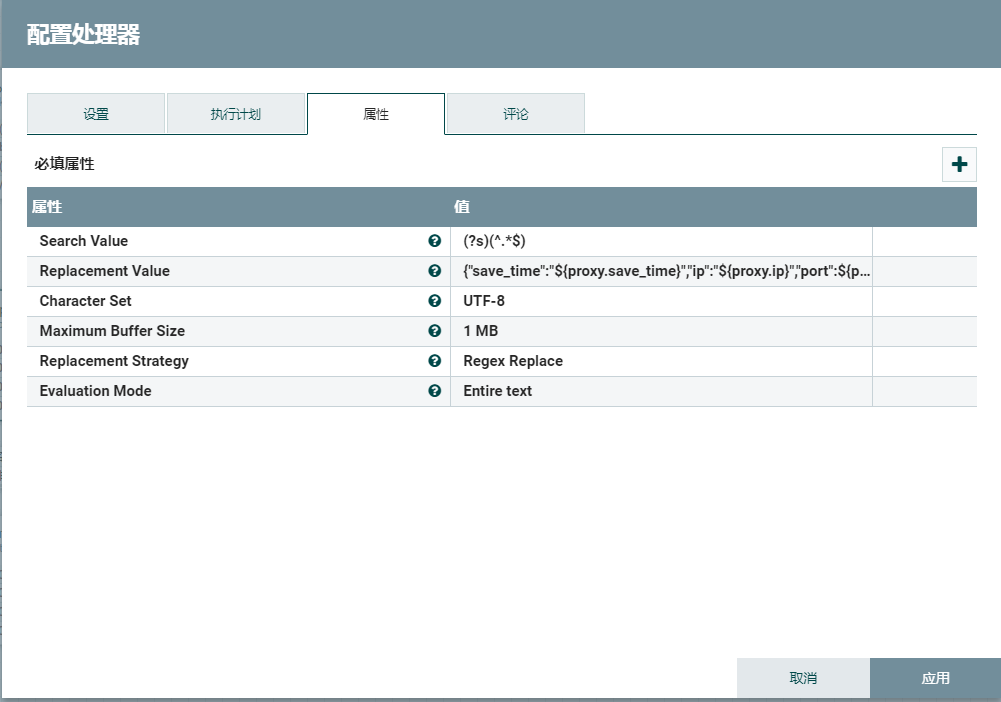
ReplaceText将格式化的json转为单行的json。Druid不能识别格式化的json,相关Druid数据格式支持http://druid.io/docs/0.12.1/ingestion/data-formats.html
2.4、输出数据到kafka
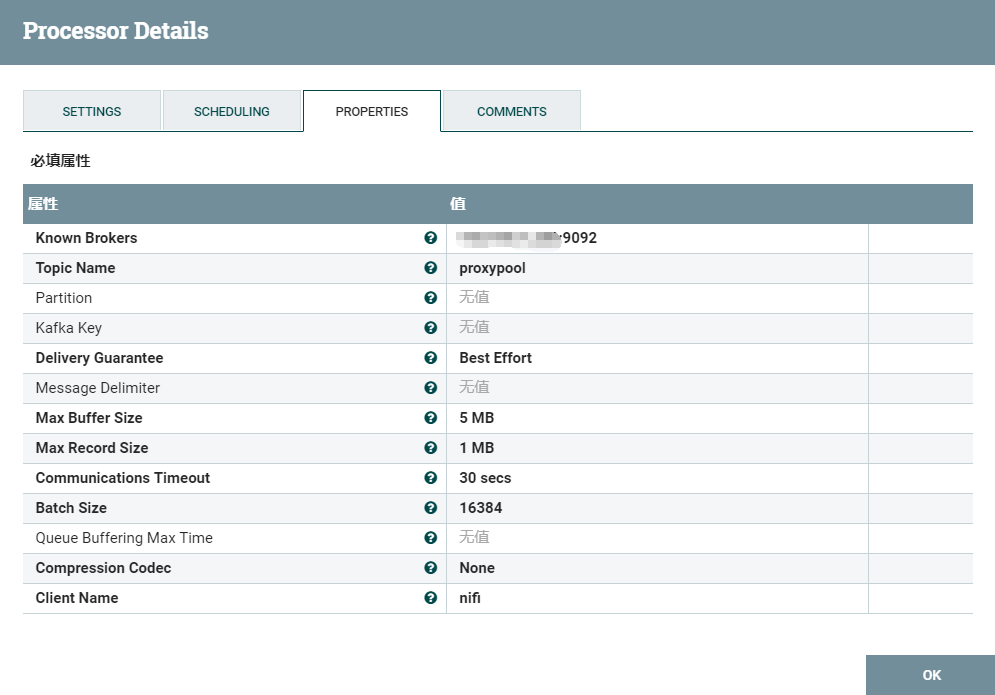
2.5、kafka创建新的主题
cd /opt/kafka
# 启动kafka
./bin/kafka-server-start.sh config/server.properties
./kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic proxypool
2.6、创建Druid流任务json
{
"dataSources" : {
"proxypool" : {
"spec" : {
"dataSchema" : {
"dataSource" : "proxypool",
"parser" : {
"type" : "string",
"parseSpec" : {
"timestampSpec" : {
"column" : "save_time",
"format" : "yyyy-MM-dd HH:mm:ss"
},
"dimensionsSpec" : {
"dimensions" : [
"ip",
"port",
"https",
"anonymity",
"id"
]
},
"format" : "json"
}
},
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none"
},
"metricsSpec" : [
{
"name" : "count",
"type" : "count"
},
{
"name" : "speed",
"type" : "doubleSum",
"fieldName" : "speed"
}
]
},
"ioConfig" : {
"type" : "realtime"
},
"tuningConfig" : {
"type" : "realtime",
"maxRowsInMemory" : "100000",
"intermediatePersistPeriod" : "PT10M",
"windowPeriod" : "PT720000M"
}
},
"properties" : {
"task.partitions" : "1",
"task.replicants" : "1",
"topicPattern" : "proxypool"
}
}
},
"properties" : {
"zookeeper.connect" : "localhost:2181",
"druid.discovery.curator.path" : "/druid/discovery",
"druid.selectors.indexing.serviceName" : "druid/overlord",
"commit.periodMillis" : "15000",
"consumer.numThreads" : "2",
"kafka.zookeeper.connect" : "localhost:2181",
"kafka.group.id" : "tranquility-kafka"
}
}
复制这个json到:
cp proxypool-kafka.json /opt/druid/conf-quickstart/tranquility/
2.7、安装tranquility
cd /opt/druid/conf-quickstart/tranquility
curl -O http://static.druid.io/tranquility/releases/tranquility-distribution-0.8.0.tgz
tar xzvf tranquility-distribution-0.8.0.tgz
tranquility-distribution-0.8.0
cd tranquility-distribution-0.8.0/
bin/tranquility kafka -configFile ../proxypool-kafka.json
在NiFi右键运行,Druid就能间隔10s摄取Http的数据了:)
转换json的步骤可以视情况去掉(例如非json数组或者非格式化的json)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号