
linux系统编程:进程控制(fork)
在linux中,用fork来创建一个子进程,该函数有如下特点:
1)执行一次,返回2次,它在父进程中的返回值是子进程的 PID,在子进程中的返回值是 0。子进程想要获得父进程的 PID 需要调用 getppid 函数。
2)生成的子进程会复制父进程一样的代码和数据
3)父子进程的全局变量和局部变量,有两份拷贝
4)子进程会继承父进程的环境状态
5)父进程会把当前执行程序的进度(即:程序运行到哪儿)也复制给子进程
/*================================================================ * Copyright (C) 2018 . All rights reserved. * * 文件名称:fork.c * 创 建 者:ghostwu(吴华) * 创建日期:2018年01月12日 * 描 述:fork基本使用 * ================================================================*/ #include <stdio.h> #include <stdlib.h> #include <unistd.h> int count = 10; int main(int argc, char *argv[]) { pid_t pid; int var = 5; printf( "----fork之前------,当前进程id=%d\n", getpid() ); pid = fork(); printf( "----fork之后------\n" ); if( pid < 0 ) { perror( "fork" ); exit( -1 ); }else if( pid == 0 ) { //子进程 var++; count++; }else { sleep( 3 ); } printf( "fork返回值pid=%d, 当前进程pid=%d, count=%d, var=%d\n", pid, getpid(), count, var ); return 0; }
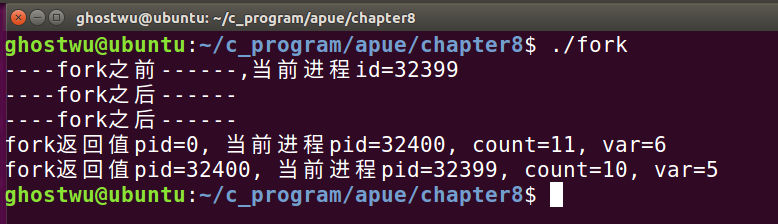
上例,我们可以看出:
1)子进程并不会输出"fork之前“这段代码,因为子进程拷贝的是fork之后的代码
2)子进程对变量操作之后,对父进程的变量没有任何影响,他们是2个不同的副本
3)标准输出是行缓冲模式:遇到换行符时进行刷新、缓冲区满了的时候刷新、强制刷新(fflush);而标准输出(stdout)是行缓冲,因为涉及到终端设备;
把这个例子的输出方式,再改一下:
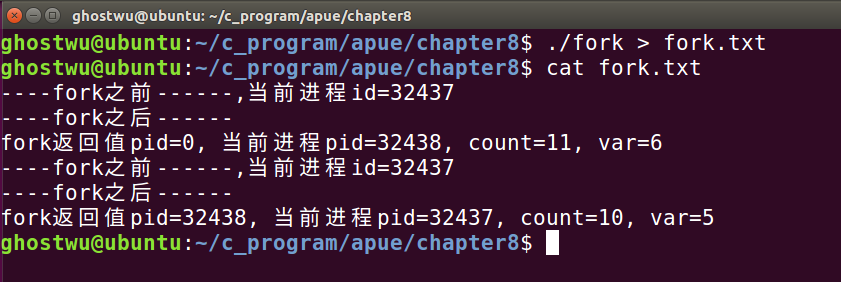
这里,你会发现,多了两个输出( "fork之前" ),因为,采用管道重定向输出之后,IO操作就变成了全缓冲模式,子进程产生的时候是会复制父进程的缓冲区的数据的,所以子进程刷新缓冲区的时候子进程也会将从父进程缓冲区中复制到的内容刷新出来。因此,在使用 fork产生子进程之前一定要使用 fflush(NULL) 刷新所有缓冲区!


/*================================================================ * Copyright (C) 2018 . All rights reserved. * * 文件名称:fork.c * 创 建 者:ghostwu(吴华) * 创建日期:2018年01月12日 * 描 述:fork基本使用 * ================================================================*/ #include <stdio.h> #include <stdlib.h> #include <unistd.h> int count = 10; int main(int argc, char *argv[]) { pid_t pid; int var = 5; printf( "----fork之前------,当前进程id=%d\n", getpid() ); fflush( NULL ); pid = fork(); printf( "----fork之后------\n" ); if( pid < 0 ) { perror( "fork" ); exit( -1 ); }else if( pid == 0 ) { //子进程 var++; count++; }else { sleep( 3 ); } printf( "fork返回值pid=%d, 当前进程pid=%d, count=%d, var=%d\n", pid, getpid(), count, var ); return 0; }

这个时候,就不会有两个("fork之前" ),因为fork生成子进程之前,已经把父进程缓冲区的数据刷新到内核缓冲区,不在标准IO的缓冲区
子进程如果比父进程先结束,那么子进程会变成僵尸进程。
因为:它们必须得等待父进程为其“收尸”才能彻底释放,如果父进程先结束了,那么这些子进程的父进程会变成 1 号 init 进程,当这些子进程运行结束时会变成僵尸进程,然后 1 号 init 进程就会及时为它们收尸
/*================================================================ * Copyright (C) 2018 . All rights reserved. * * 文件名称:fork3.c * 创 建 者:ghostwu(吴华) * 创建日期:2018年01月12日 * 描 述: * ================================================================*/ #include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc, char *argv[]) { pid_t pid; int i = 0; for( i = 0 ; i < 10; i++ ) { pid = fork(); if( pid < 0 ) { perror( "fork()" ); exit( -1 ); }else if( pid == 0 ) { printf( "[pid]=%d\n", getpid() ); exit( 0 ); } } sleep( 10 ); return 0; }
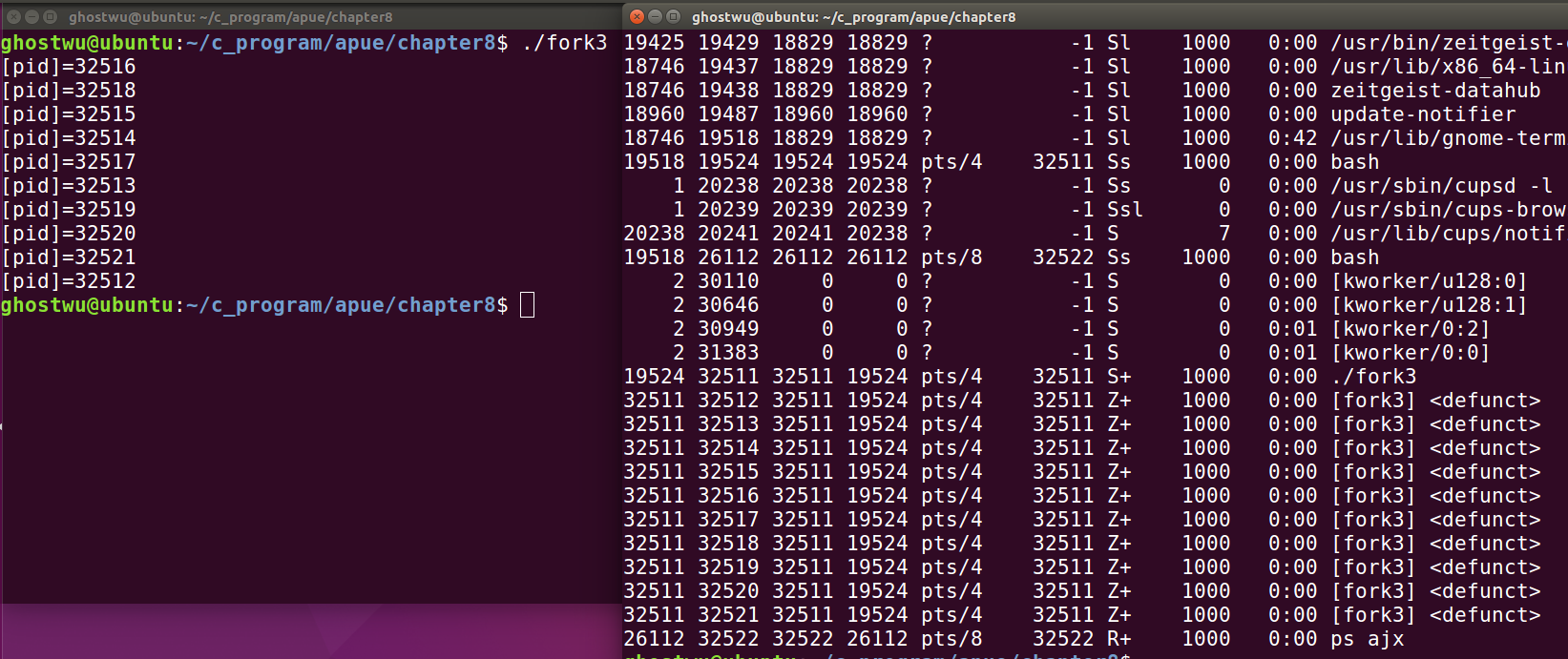
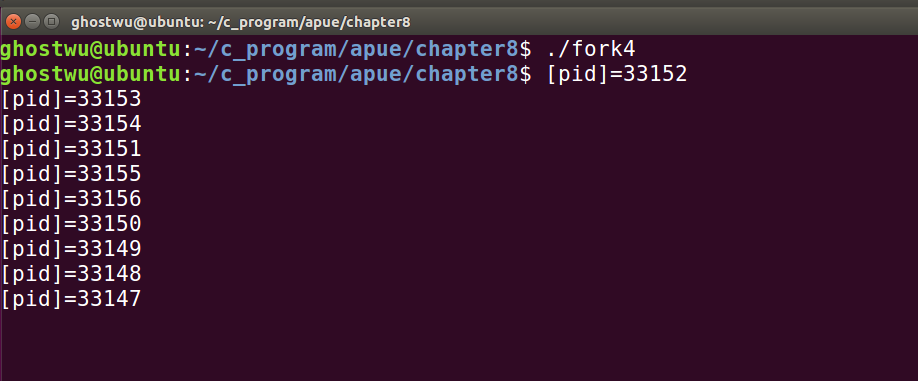
父进程如果比子进程先结束,那么子进程会变成孤儿进程
所有子进程的父进程都变成了 1 号 init 进程
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc, char *argv[]) { pid_t pid; int i = 0; for( i = 0 ; i < 10; i++ ) { pid = fork(); if( pid < 0 ) { perror( "fork()" ); exit( -1 ); }else if( pid == 0 ) { sleep( 10 ); printf( "[pid]=%d\n", getpid() ); exit( 0 ); } } return 0; }
作者:ghostwu, 出处:http://www.cnblogs.com/ghostwu
博客大多数文章均属原创,欢迎转载,且在文章页面明显位置给出原文连接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号