爬取链家二手房与汽车之家新闻数据
目录
- 爬取链家二手房数据
- 爬取汽车之家新闻数据
爬取链家二手房数据
1、进入链接二手房某个区的界面,判断分析该数据的加载方式,结果的知识直接加载的
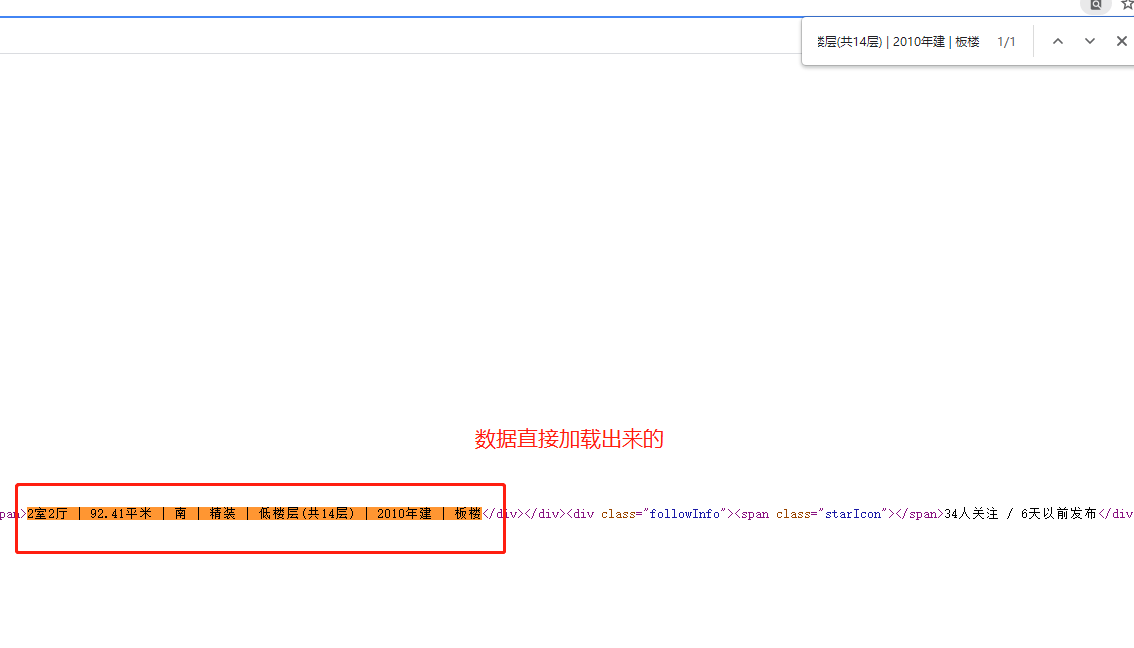
2、在pycharm中打印下看看是否有防爬和乱码现象,结果是没有,那对页面进行数据解析筛选
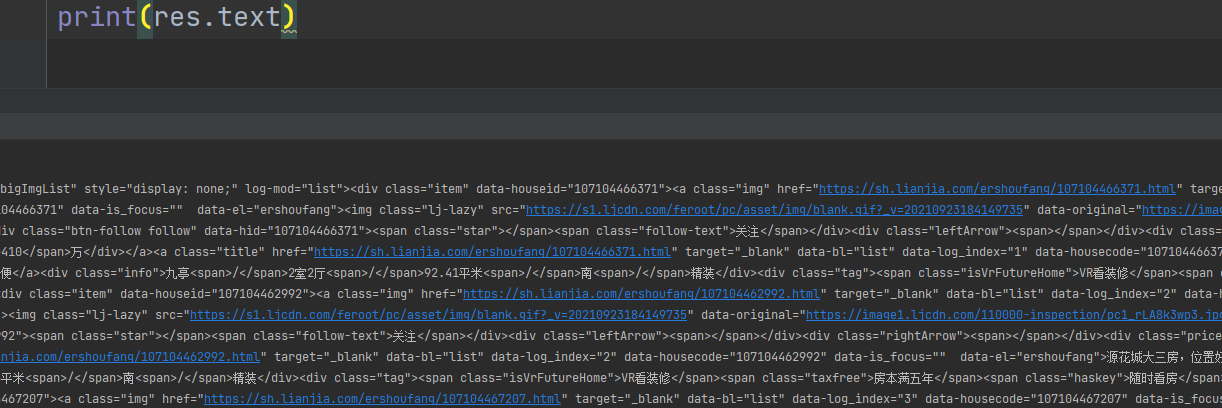
3、在页面空白处右键点击检查,利用鼠标选中标题查询该数据在哪个标签里,并研究如何获取
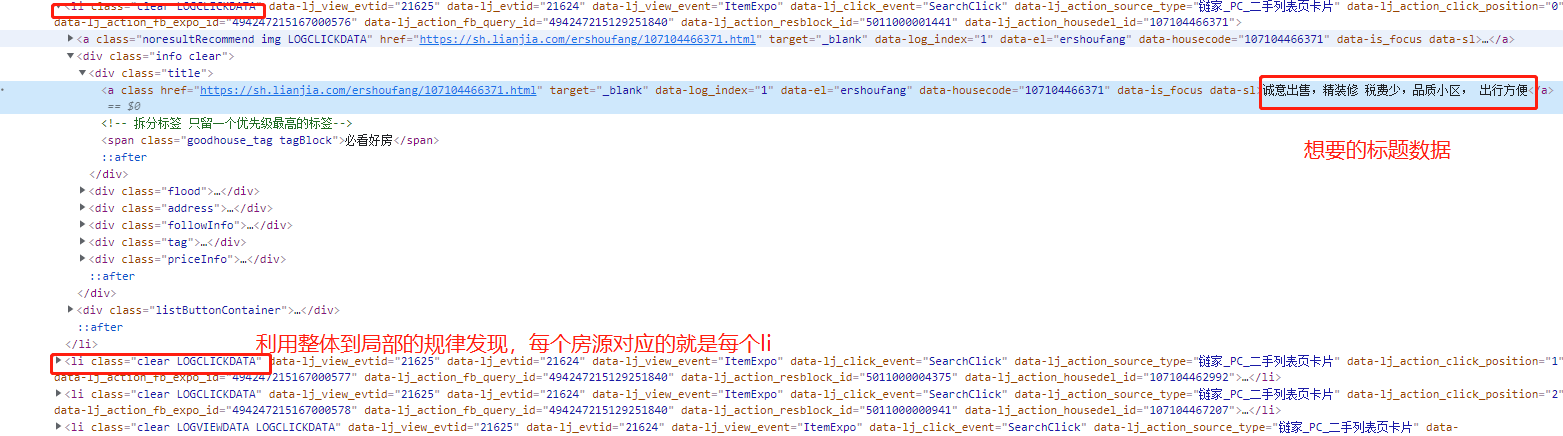
4、然后循环每一个li标签,再去筛选一个个数据
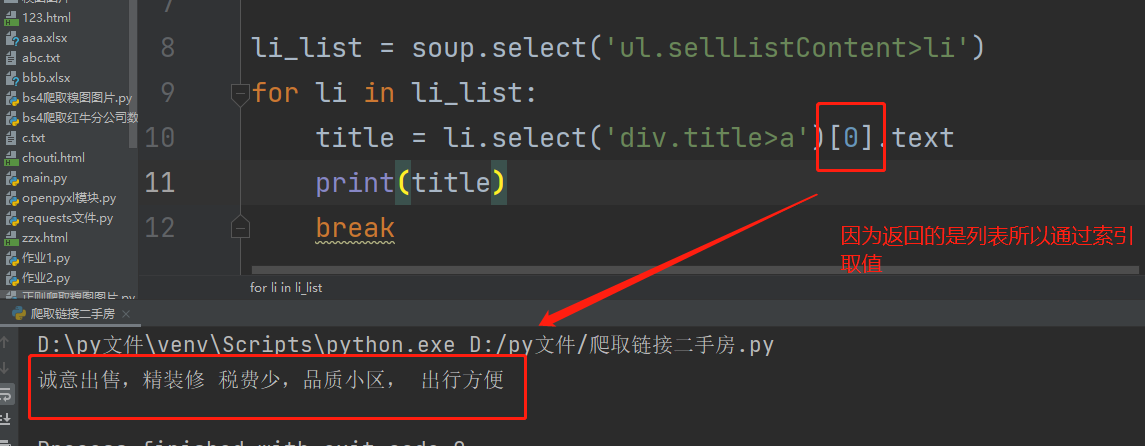
5、拿到房屋标题和链接详情之后,去分析住处数据,如图我们可以通过select筛选出来

6、以此类推,筛选出房屋详细信息
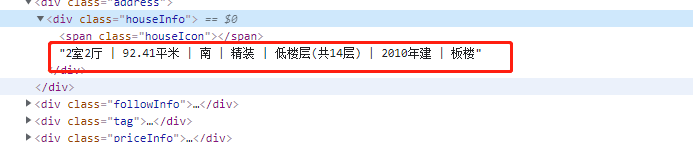
7、筛选出关注度及发布时间
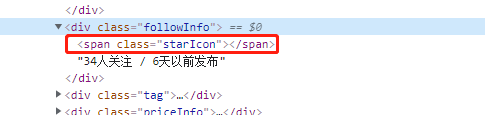
8、筛选出房屋总价与单价

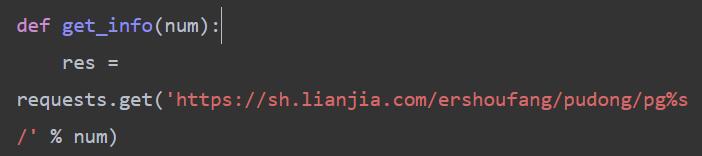
9、多页操作可去浏览器点击下一页查看数据,分析得知根据后缀page来定义参数

10、封装成函数,调用即可完成多页获取数据操作
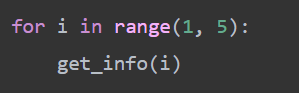
11、利用openpyxl模块将数据写入excel表格中

12、再利用代码写入数据到表格中

13、但是打开表格发现有些表头可拆分,数据可以再细分

14、在原本基础上添加代码后,别忘了在表头加入新表头及写入数据的代码里加入赋值的变量名并去除空格

15、但是执行完发现会报错,如图:
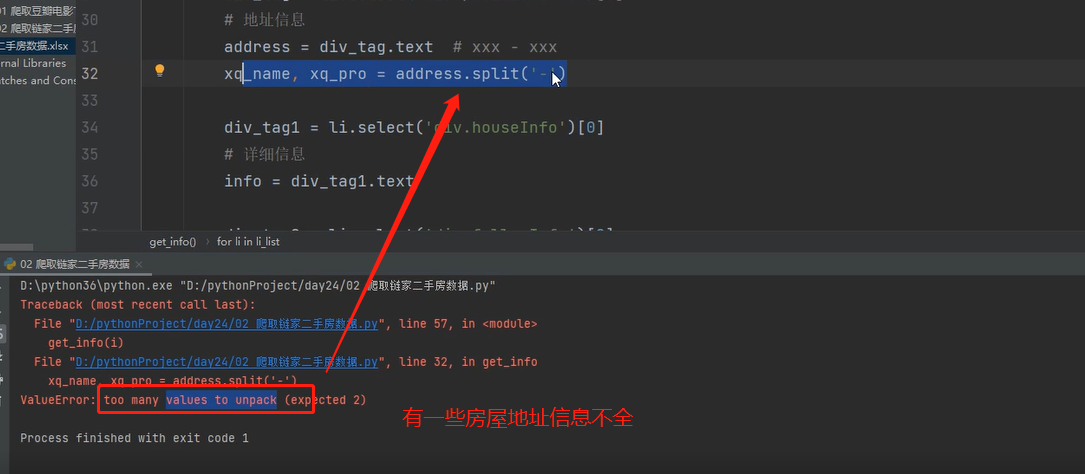
16、可采用if判断来解决

完整代码


import requests from bs4 import BeautifulSoup from openpyxl import Workbook wb = Workbook() wb1 = wb.create_sheet('二手房数据') # 先定义表头 wb1.append(['房屋名称', '详情链接', '小区名称', '区域名称', '详细信息', '关注人数', '发布时间', '总价', '单价']) def get_info(num): res = requests.get('https://sh.lianjia.com/ershoufang/pudong/pg%s/' % num) soup = BeautifulSoup(res.text, 'lxml') li_list = soup.select('ul.sellListContent>li') for li in li_list: a_tag = li.select('div.title>a')[0] # 房屋名称 title = a_tag.text # 详情链接 link = a_tag.get('href') div_tag = li.select('div.positionInfo')[0] # 地址信息 address = div_tag.text # xxx - xxx res = address.split('-') if len(res) == 2: xq_name, xq_pro = res else: xq_name = xq_pro = res[0] div_tag1 = li.select('div.houseInfo')[0] # 详细信息 info = div_tag1.text div_tag2 = li.select('div.followInfo')[0] # 关注度及发布时间 focus_time = div_tag2.text # xxx / xxx people_num, publish_time = focus_time.split('/') div_tag3 = li.select('div.totalPrice')[0] # 总价 total_price = div_tag3.text div_tag4 = li.select('div.unitPrice')[0] # 单价 unit_price = div_tag4.text #写入数据 wb1.append( [title, link, xq_name.strip(), xq_pro.strip(), info, people_num.strip(), publish_time.strip(), total_price, unit_price]) for i in range(1, 5): get_info(i) wb.save(r'链家浦东二手房数据.xlsx')
爬取汽车之家新闻数据
1、查看页面数据的加载方式,发现是直接加载的

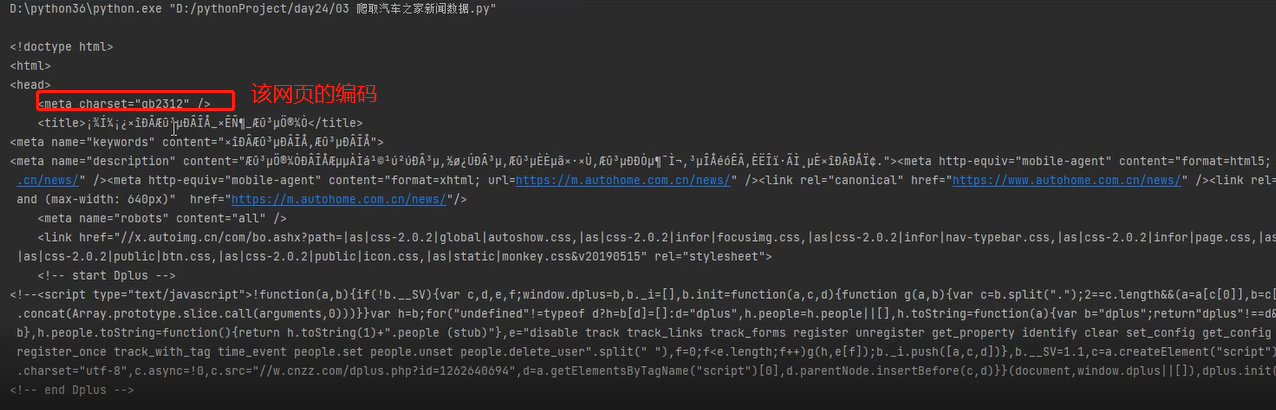
2、在pycharm中请求该网页看看有没有防爬,结果发现有加入请求头后发现乱码,需要定义下字符编码
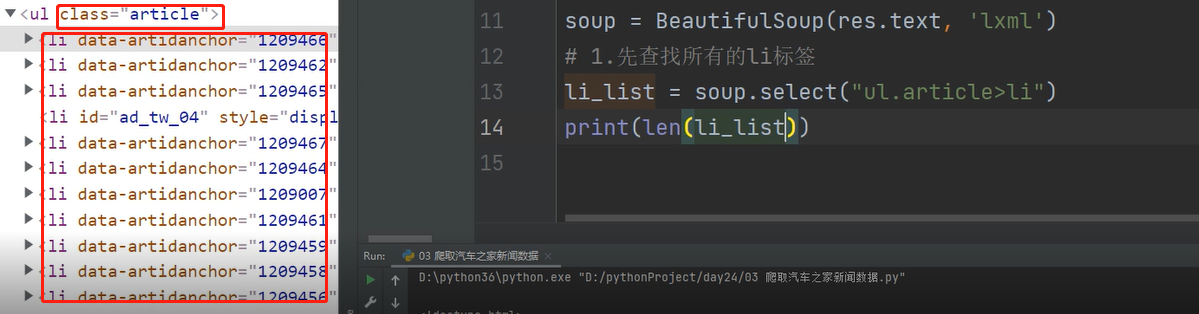
3、对页面数据进行解析,发现新闻数据是一个个li标签
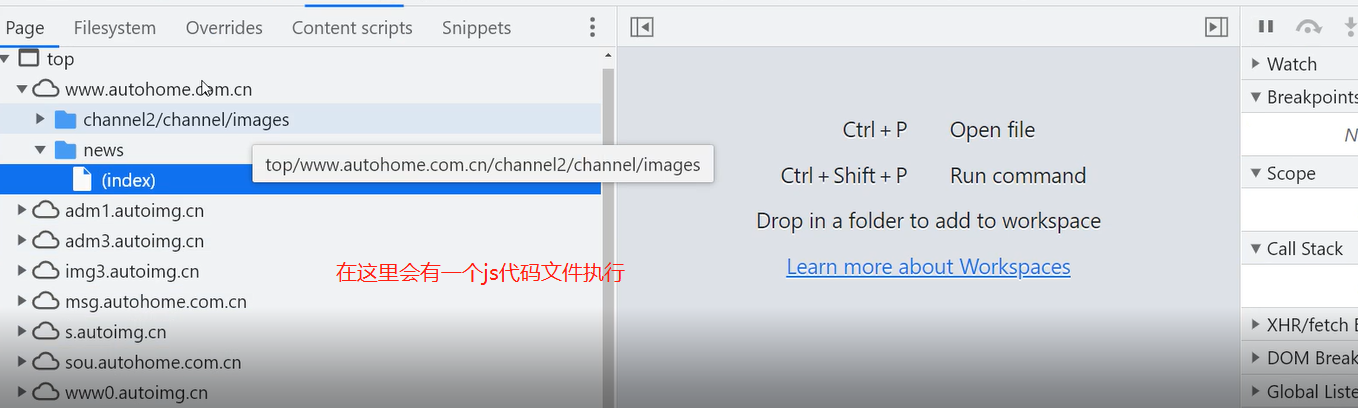
4、结果获取到数量较多的li标签,研究发现是第三种加载方式,是根据本地的js代码通过检测滚轮条的下滑来显示其余页面的数据
5、然后获取a标签内的href链接时报错了,原因是有页面干扰项
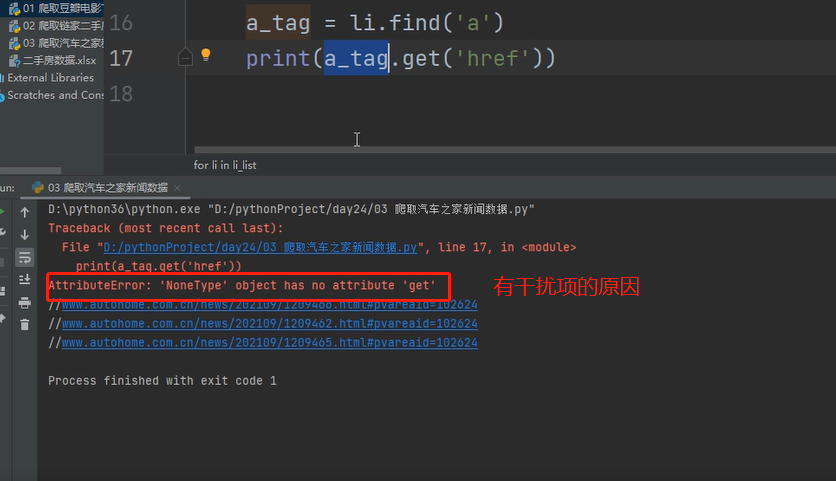
6、我们可以做判断,拿到新闻页的详情完整链接

7、然后开始筛选我们需要的数据,首先是新闻标题

8、接着按照之前的步骤逐步筛选新闻图标、发布时间、新闻简介
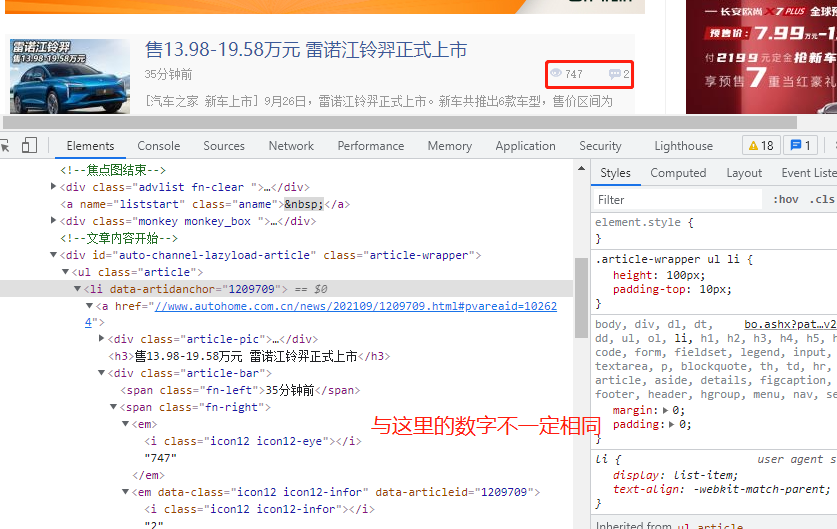
9、而观看人数和评论数的数据是多少有点虚构的,如图:
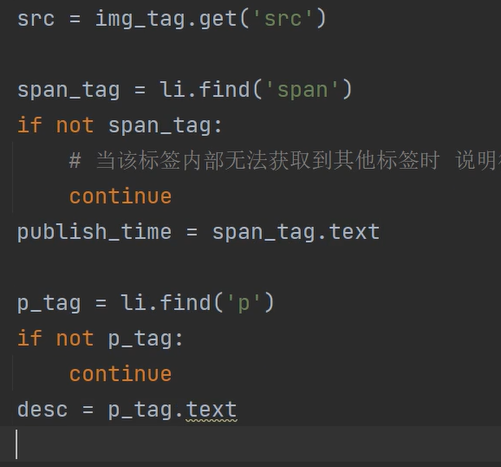
10、但是上述两组数据也可获取,之后我们可以简化代码,如代码所示:
# 获取新闻标题 title = h3_tag.text # 简写 # title = li.find('h3').text # img_tag = li.find('img') # 获取新闻图标 # src = img_tag.get('src') # 简写 src = li.find('img').get('src') # span_tag = li.find('span') # 获取发布时间 # publish_time = span_tag.text # 简写 publish_time = li.find('span').text # p_tag = li.find('p') # 获取文字简介 # desc = p_tag.text # 简写 desc = li.find('p').text # em_tag = li.find('em') # 获取观看次数 # watch_num = em_tag.text # 简写 watch_num = li.find('em').text # em1_tag = li.select('em.icon12') # 获取评论次数 # comment_num = em1_tag[0].text # 简写 comment_num = li.find('em', attrs={'data-class': 'icon12 icon12-infor'}).text
11、最后结合openpyxl模块,写入数据到表格中,也可实现分页,参考链家二手房案例即可
import requests from bs4 import BeautifulSoup from openpyxl import Workbook wb = Workbook() wb1 = wb.create_sheet('汽车之家数据', 0) wb1.append(['新闻链接', '新闻标题', '新闻图标', '出版时间', '新闻简介', '观看人数', '评论数']) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'} def get_carnews(num): res = requests.get('https://www.autohome.com.cn/news/%s/#liststart' % num) res.encoding = 'gbk' soup = BeautifulSoup(res.text, 'lxml') li_list = soup.select('ul.article>li') for li in li_list: a_tag = li.find('a') if not a_tag: continue link = 'https:' + a_tag.get('href') h3_tag = li.find('h3') if not h3_tag: continue title = h3_tag.text img_tag = li.find('img') # if not img_tag: # continue src = img_tag.get('src') span_tag = li.find('span') # if not span_tag: # continue publish_time = span_tag.text p_tag = li.find('p') # if not p_tag: # continue desc = p_tag.text em_tag = li.find('em') # if not em_tag: # continue watch_num = em_tag.text em1_tag = li.find('em', attrs={'data-class': 'icon12 icon12-infor'}) # if not em1_tag: # continue comment_num = em1_tag.text wb1.append([link, title, src, publish_time, desc, watch_num, comment_num]) for i in range(1, 3): get_carnews(i) wb.save(r'汽车之家.xlsx')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号