3.Spark设计与运行原理,基本操作
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
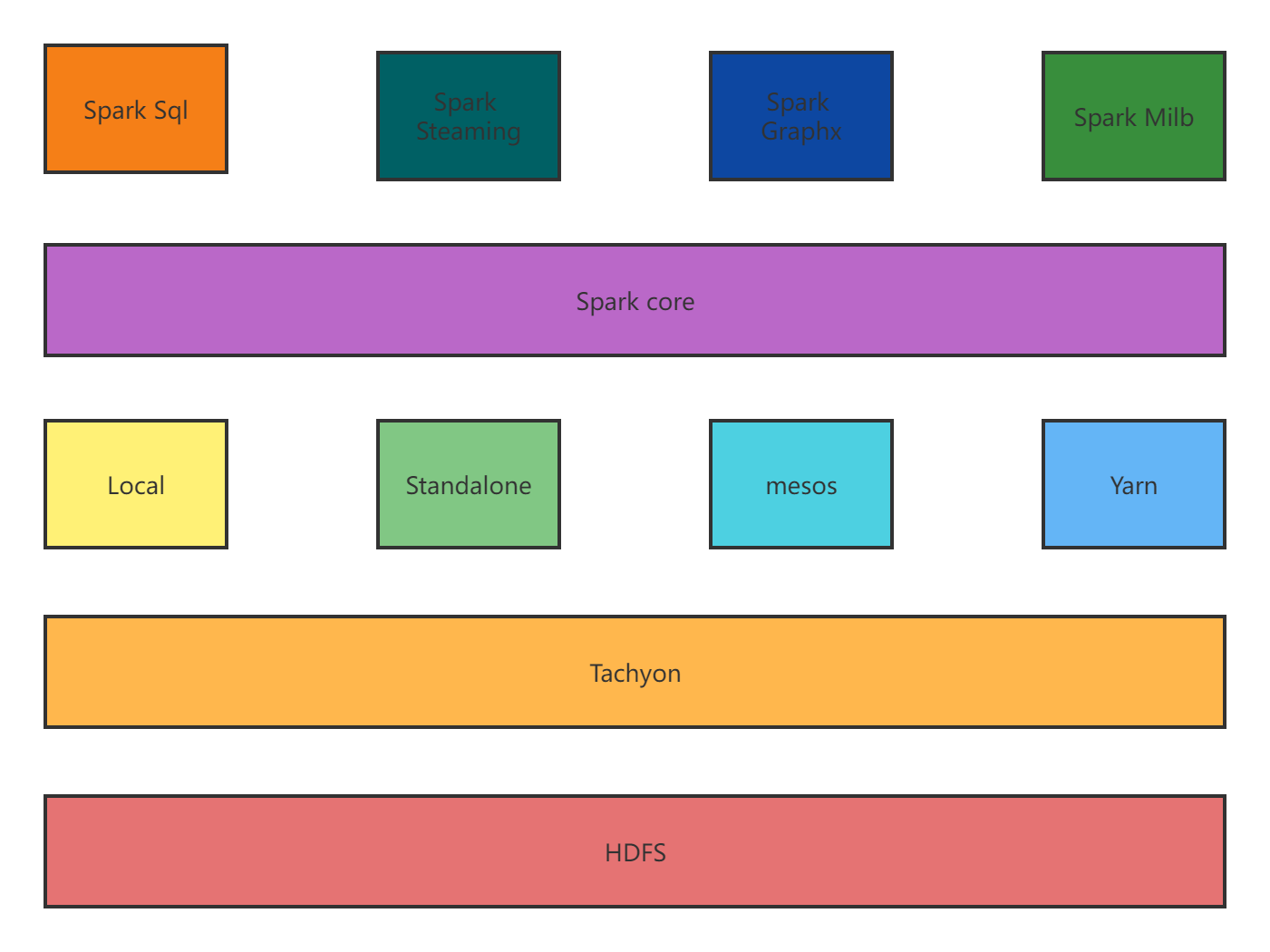
Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成一套完整生态系统,既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。因此,Spark所提供的生态系统同时支持批处理、交互式查询和流数据处理。
2.请详细阐述Spark的几个主要概念及相互关系:
Master, Worker; RDD,DAG; Application, job,stage,task; driver,executor,Claster Manager
DAGScheduler, TaskScheduler.
Master:主控节点,顾名思义,类似于领导者,在整个集群中,最多只有一个Master处于Active状态。
Worker:根据Cluster Manager的指令分配资源,执行应用程序,释放资源。
RDD:弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
DAG:有向无环图,反映RDD之间的依赖关系
Application应用:用户编写的Spark应用程序job
Job作业:一个作业包含多个RDD及作用于相应RDD上的各种操作
Stage阶段:是作业的基本调度单位,每个作业会因为RDD之间的依赖关系拆分成多组任务集合TaskSet,称为调度阶段。调度阶段的划分是由DAGScheduler来划分的,有Shuffle Map Stage和Resuit Stage两种
Task任务:分发到Executor上的工作任务,是spark实际执行应用的最小单元
Driver:提交了应用之后,便会启动一个对应的 driver 进程。driver 进程就是应用的 main()函数,并且构建 SparkContext 对象。向Manger申请应用所需的资源,启动Executor,向Executor发送代码和文件。
Executor:进程宿主在worker节点上,一个 worker 可以有多个executor ,负责运行任务Task
①每个 executor 持有一个线程池,每个线程可以执行一个 task,并将结果返回给 Driver 。
②块管理器Block Manager,为RDD 提供内存存储(内存+磁盘)
Claster Manager:集群资源管理器,自带的或Mesos或YARN,负责申请和管理在Worker Node上运行应用所需的资源。
DAGScheduler:面向调度阶段的任务调度器,负责接收spark应用提交的作业,根据RDD的依赖关系划分调度阶段,并提交调度阶段给TaskScheduler.
TaskScheduler:面向任务的调度器,它接受DAGScheduler提交过来的调度阶段,然后把任务分发到work节点运行,由Worker节点的Executor来运行该任务
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
>>> sc
>>> lines = sc.textFile("file:///home/hadoop/my.txt")
>>> lines
>>> words=lines.flatMap(lambda line:line.split())
>>> words
>>> wordKV=words.map(lambda word:(word,1))
>>> wordKV
>>> wc=wordKV.reduceByKey(lambda a,b:a+b)
>>> wc
>>> cs=lines.flatMap(lambda line:list(line))
>>> cs
>>> cKV=cs.map(lambda c:(c,1))
>>> cKV
>>> cc=cKV.reduceByKey(lambda a,b:a+b)
>>> cc
>>> lines.foreach(print)
>>> words.foreach(print)
>>> wordKV.foreach(print)
>>> cs.foreach(print)
>>> cKV.foreach(print)
>>> wc.foreach(print)
>>> cc.foreach(print)
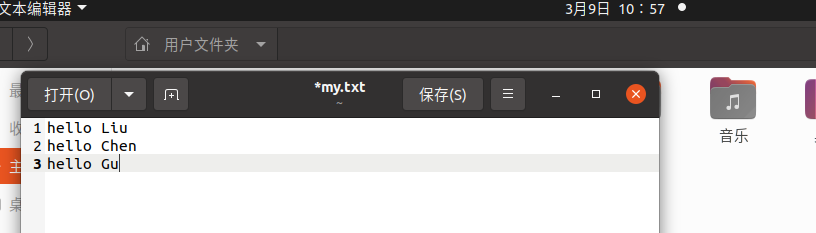
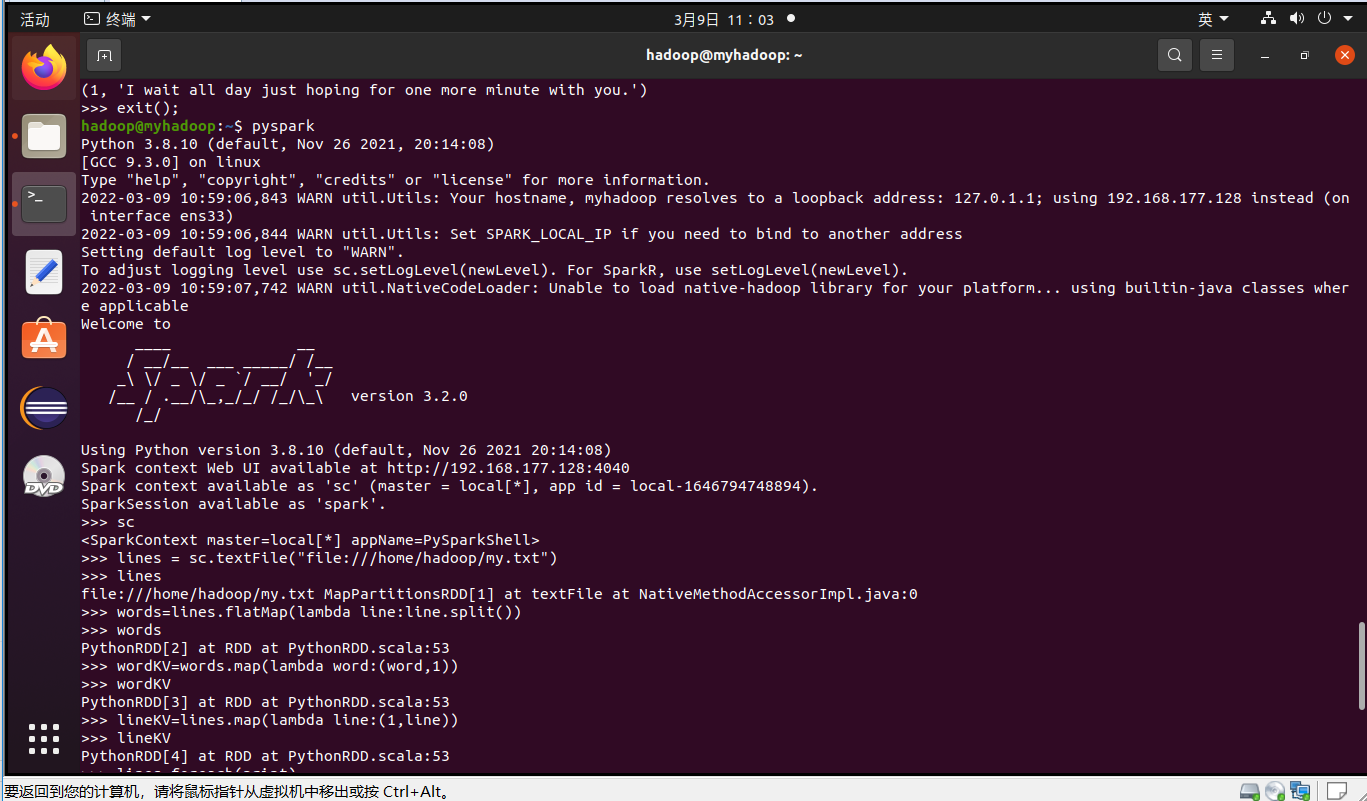
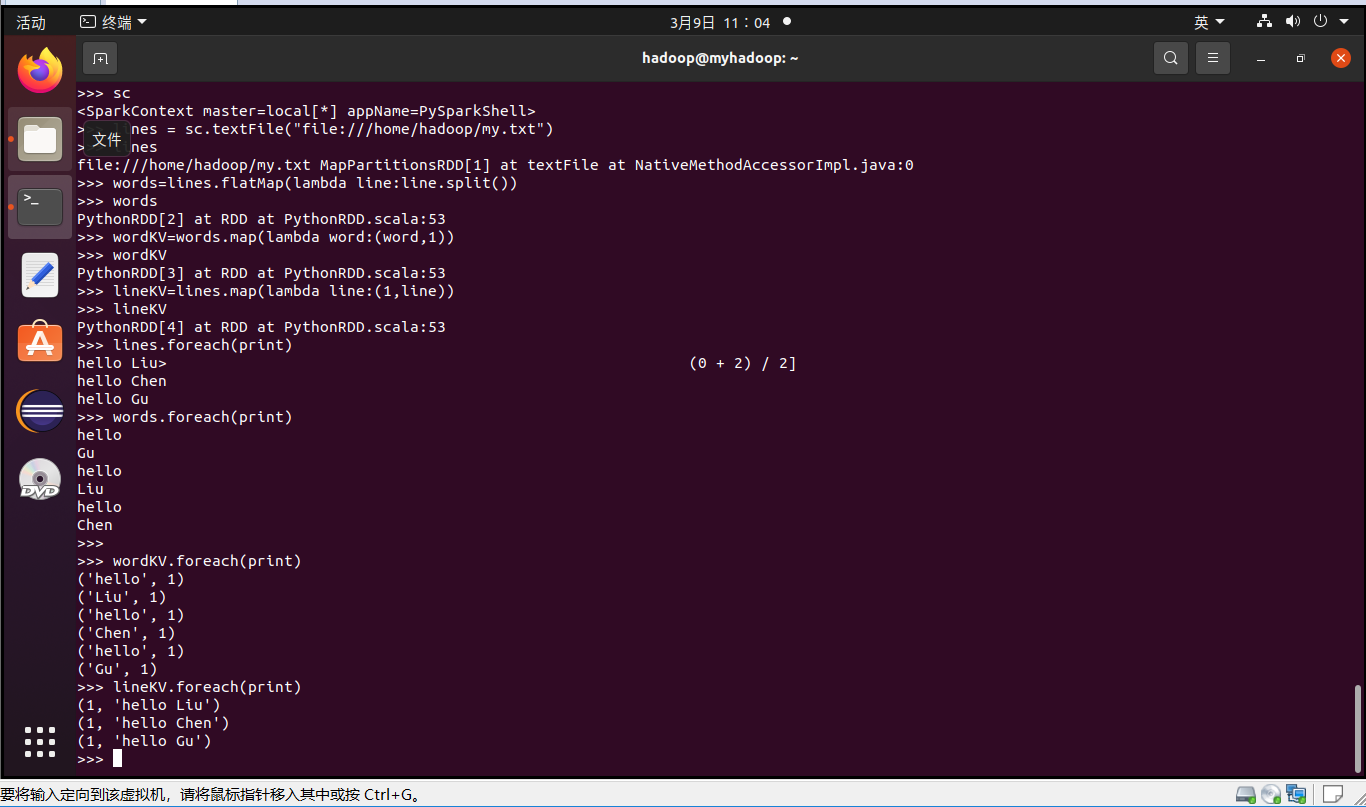
RDD转换关系图: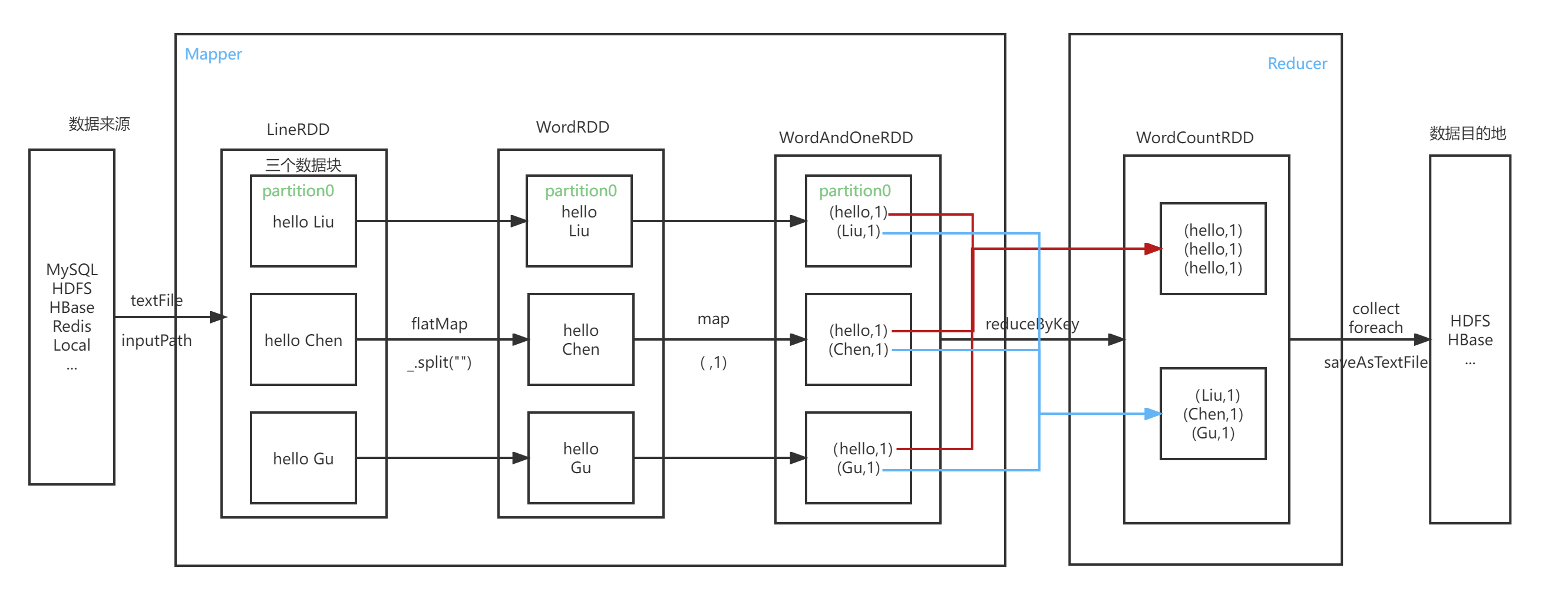

 浙公网安备 33010602011771号
浙公网安备 33010602011771号