五、RDD操作综合实例
一、词频统计
A.分步骤实现
1.准备文件
下载小说或长篇新闻稿(从网上随便找一篇新闻)
上传到hdfs上

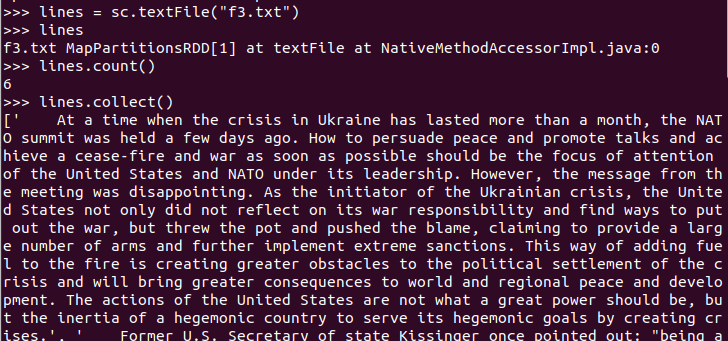
2.读文件创建RDD
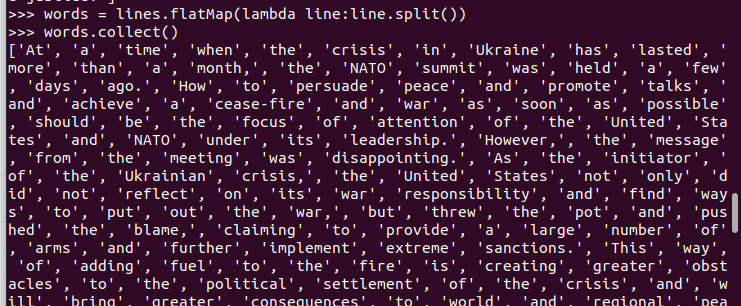
3.分词
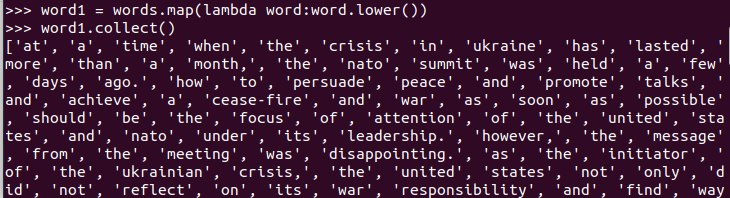
4.排除大小写lower(),map()
标点符号re.split(pattern,str),flatMap()
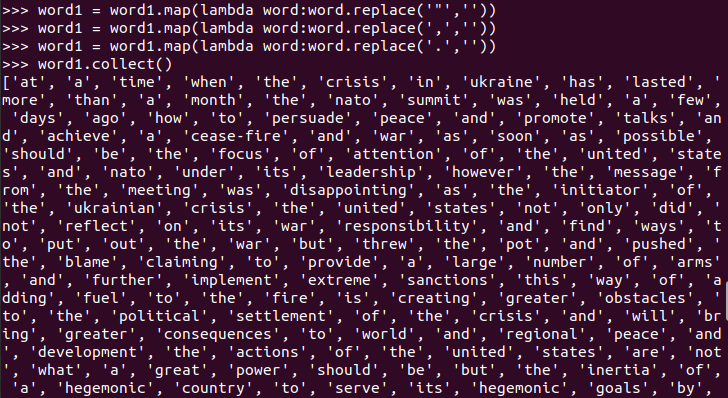
停用词
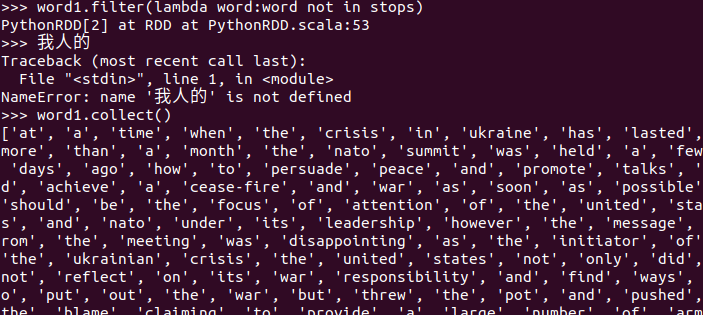
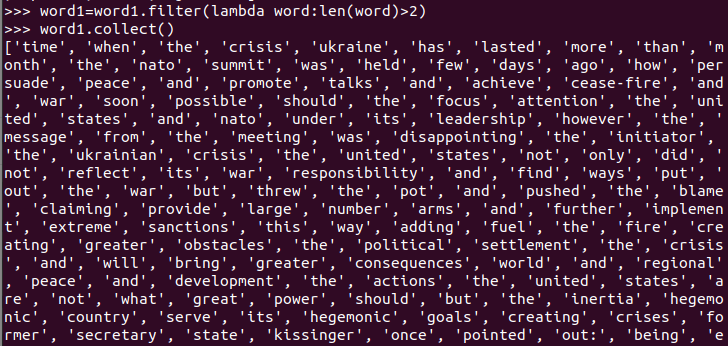
长度小于2的词filter()
5.统计词频
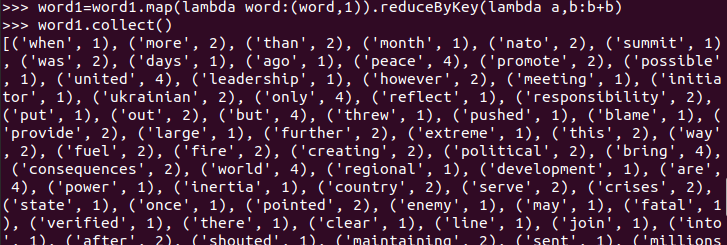
6.按词频排序
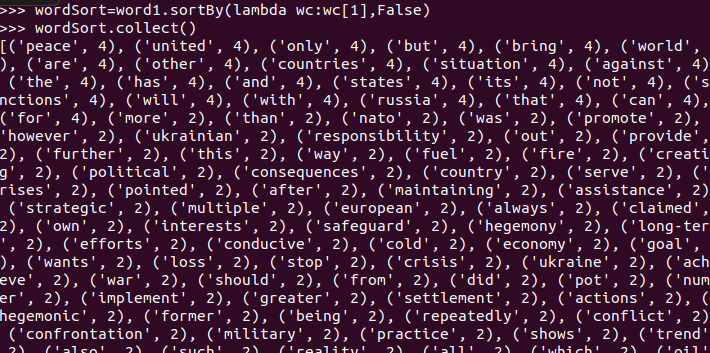
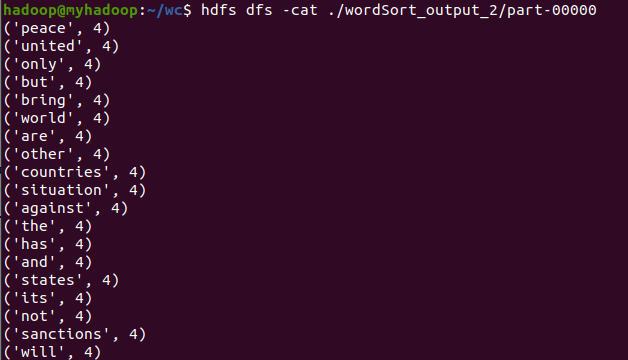
7.输出到文件

8.查看结果
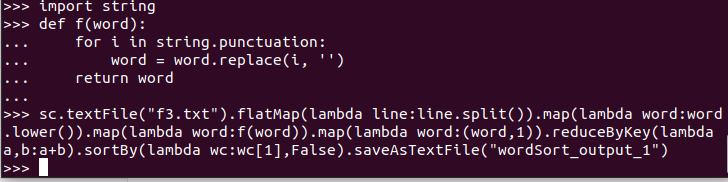
B.一句话实现
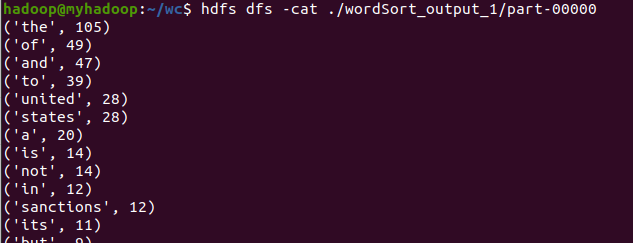
C.和作业2的“二、Python编程练习:英文文本的词频统计 ”进行比较,理解Spark编程的特点。
1.速度快:Spark 使用DAG 调度器、查询优化器和物理执行引擎,能够在批处理和流数据获得很高的性能。
2.易操作:Spark的易用性主要体现在两个方面。一方面,我们可以用较多的编程语言来写我们的应用程序,比如说Java,Scala,Python,R 和 SQL;另一方面,Spark 为我们提供了超过80个高阶操作,这使得我们十分容易地创建并行应用,除此之外,我们也可以使用Scala,Python,R和SQL shells,以实现对Spark的交互。
3.通用性高:与其说通用性高,还不如说它集成度高,以Spark为基础建立起来的模块(库)有Spark SQL,Spark Streaming,MLlib(machine learning)和GraphX(graph)。我们可以很容易地在同一个应用中将这些库结合起来使用,以满足我们的实际需求。
二、求取TOP值
导入数据

拆分字段并查看数据的字段数及数据的总行数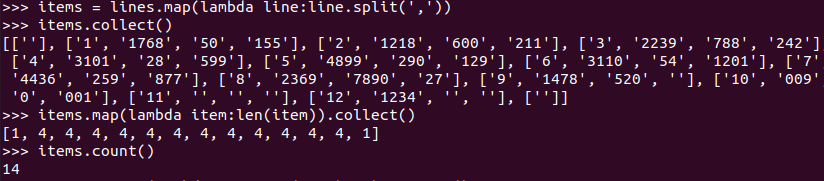
丢弃空行和字段不完整的行并查看数据的字段数及数据的总行数
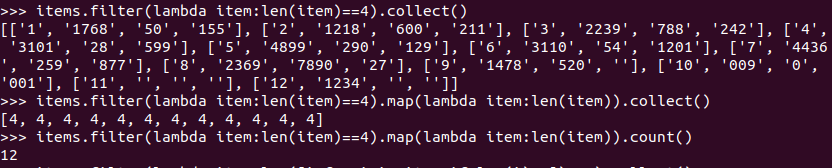
丢弃有空值的行并查看数据的行数
保存为有效记录并将记录按照支付金额排序

取有效记录前三条并查看


 浙公网安备 33010602011771号
浙公网安备 33010602011771号