
基于机器学习进行遥感影像的地物分类与参数反演-以随机森林为例(提供代码与示例数据)
摘要
本教程适合想利用Python在本地利用机器学习进行遥感影像地物分类,或者参数反演(回归)的同学。在本教程中会介绍Python开发环境的配置(anconda,pycharm);Python第三方包的配置以及实际实用;遥感数据的获取以及处理;模型的训练与预测;预测结果的评价等。其中分类任务以基于随机森林的水体提取为例,回归任务以基于随机森林的NDWI反演为例。
关键词:
机器学习;遥感;分类;回归;Python
1 软件准备
需要安装的软件主要有:ArcGIS(或者QGIS)、ENVI、anconda、pycharm
需要配置的Python包有:GDAL、sklearn、numpy等
ArcGIS、ENVI的安装请参考网络
1.1 anconda安装
1、下载安装包
推荐使用通过清华镜像源下载,下载速度较快,链接如下,可根据date选择最新版本
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
2、安装anconda
推荐使用管理员权限运行安装,避免不必要的麻烦
点击Next
I agree 同意
两个选择,我在使用时影响不大,可选择默认选项all users,点击next
选择安装路径,如果C盘空间充足建议默认路径,next
默认选项即可,install,然后稍定几分钟。。。。
next,next然后完成了安装!!!
1.2 pycharm安装
1.下载安装包Download PyCharm: The Python IDE for data science and web development by JetBrains 下载社区版就基本够用
2.安装pycharm
找到你下载PyCharm的路径,双击.exe文件进行安装。
点击 Next 后,我们进行选择安装路径页面(尽量不要选择带中文和空格的目录)选择好路径后,点击 Next 进行下一步
进入 Installation Options(安装选项)页面,全部勾选上。点击 Next
进入 Choose Start Menu Folder 页面,直接点击 Install 进行安装
5.等待安装完成后出现下图界面,我们点击 Finish 完成。
3.汉化
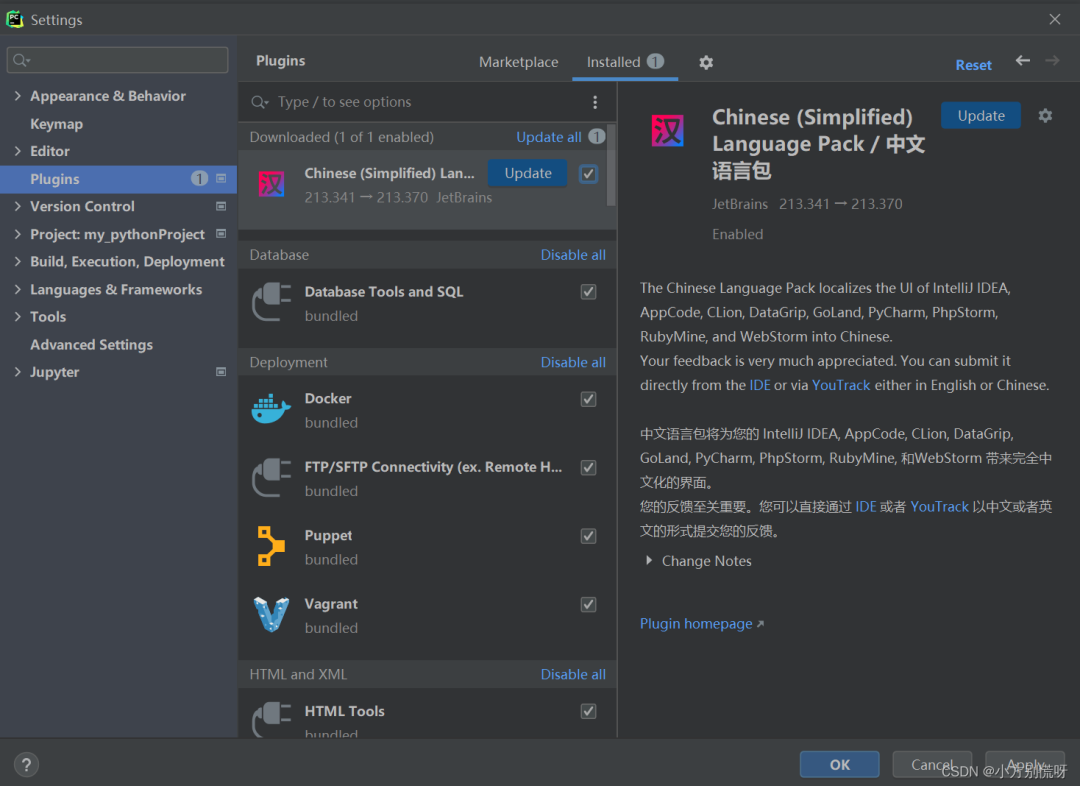
File->Settings->Plugins(插件)在搜索栏中输入Chinese(Simplified)下载中文插件并安装重启PyCharm即出现汉化
1.3 Python环境配置
1.anconda环境配置
打开anconda,点击environment
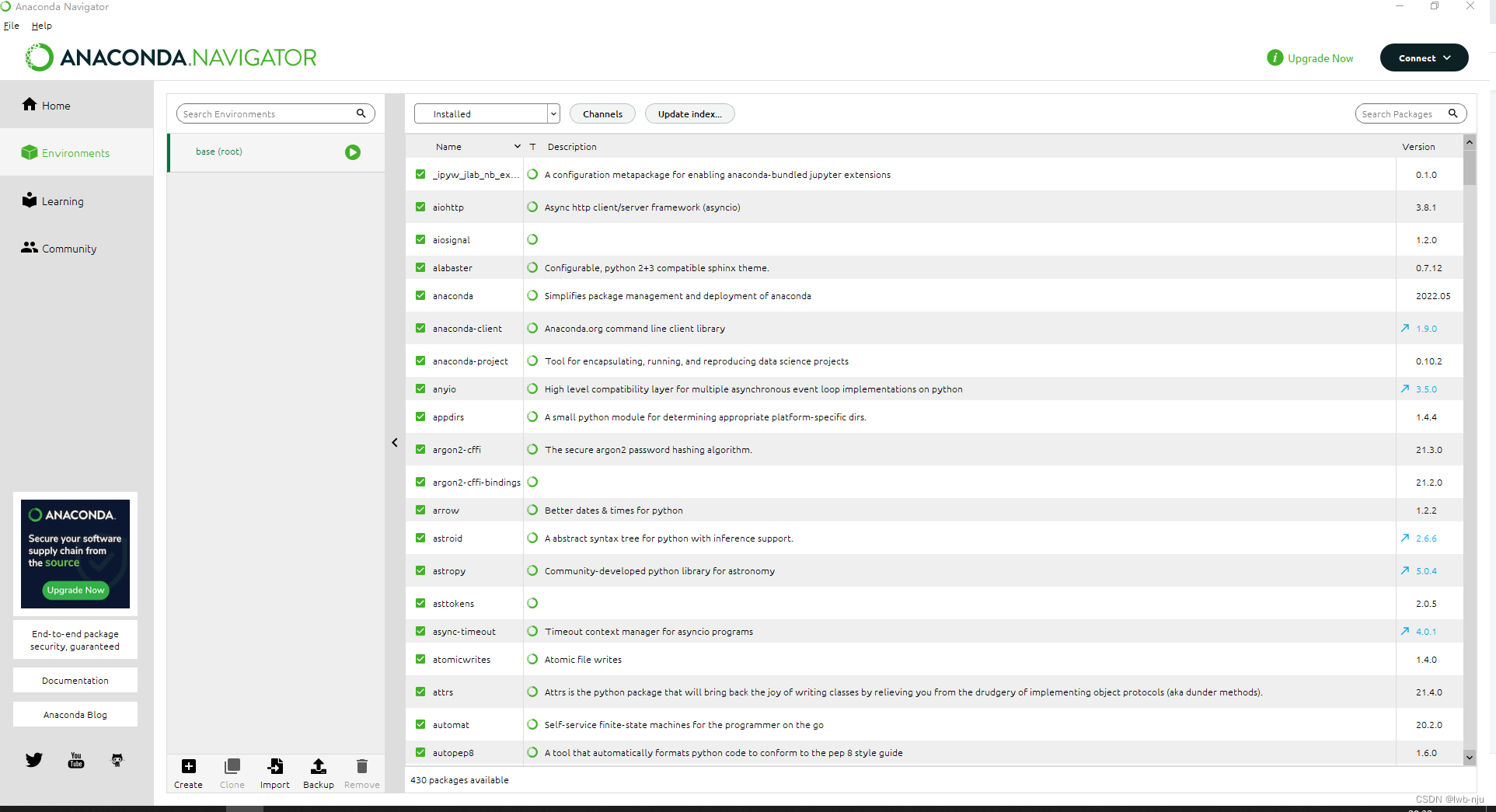
新安装后的anconda只有一个base环境,如果新建环境点击create
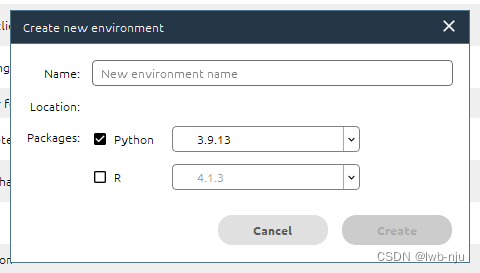
给环境起一个名称,选择python的版本 ,填写好后点击create 稍定几分钟就创建好了
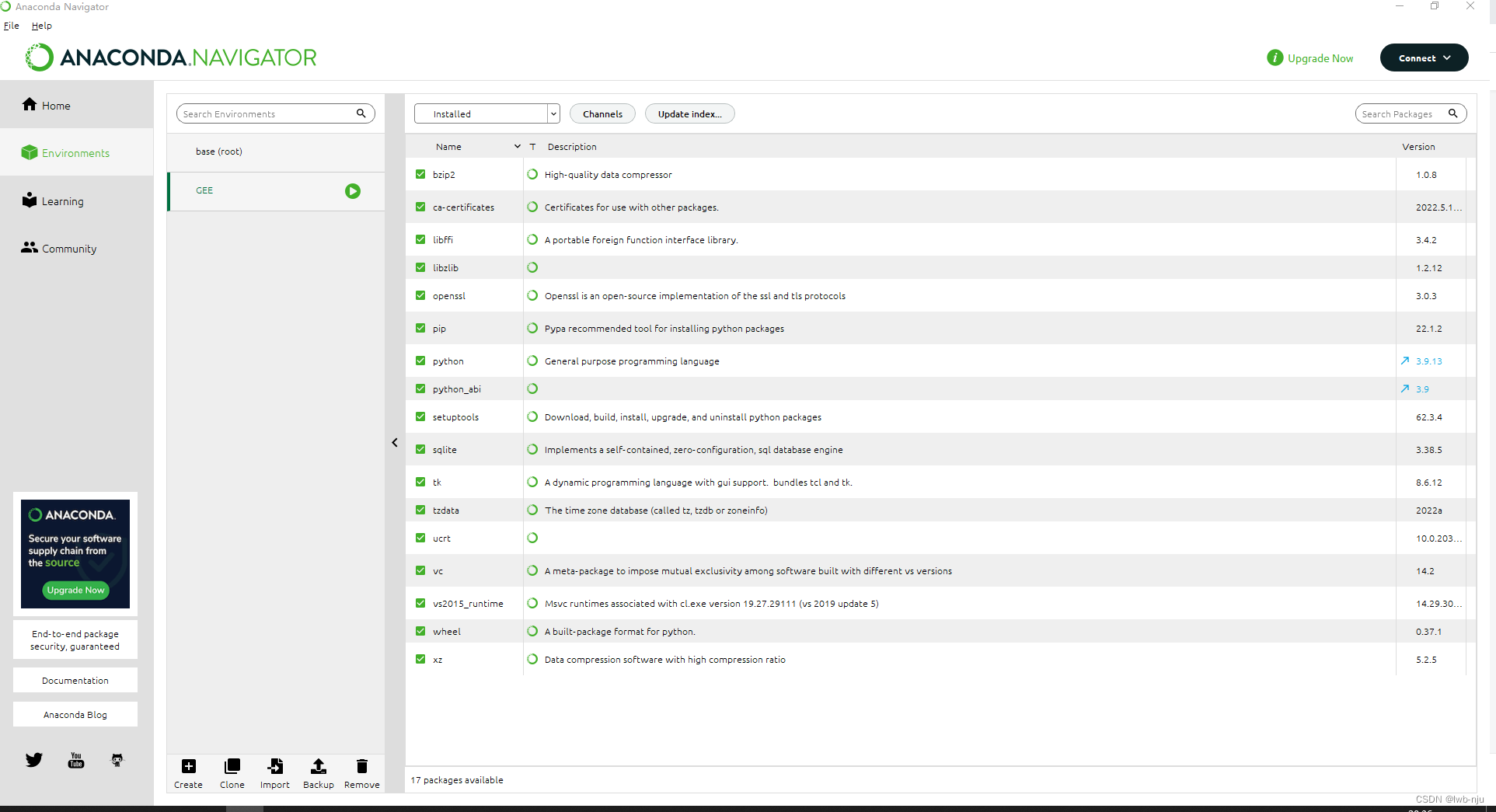
2、在虚拟环境中安装第三方库(界面化操作)
把左上方下拉框选为 not installed 在右上方搜索,这里需要安装gdal、Scikit learn、numpy等
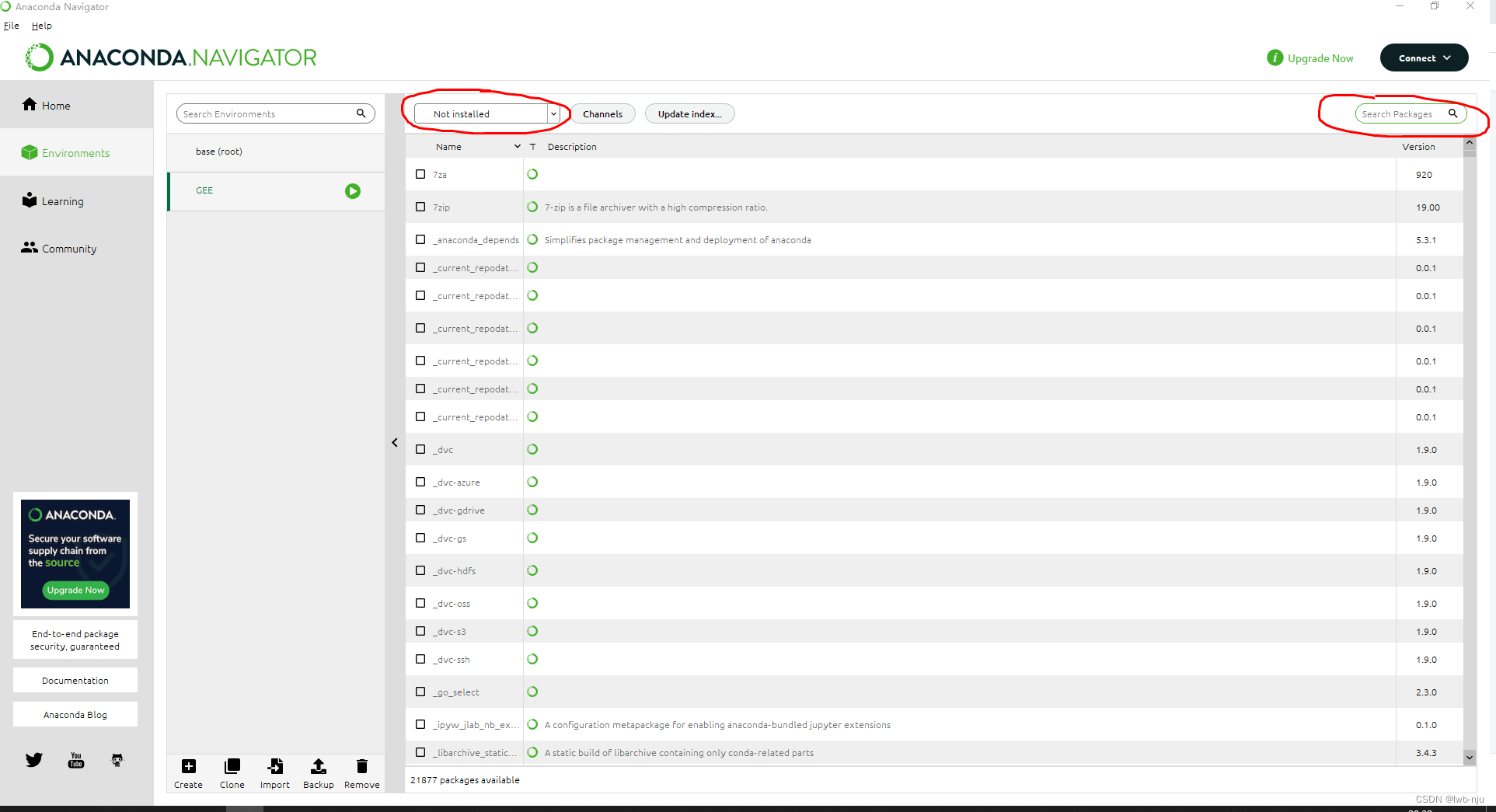
然后勾选需要的库
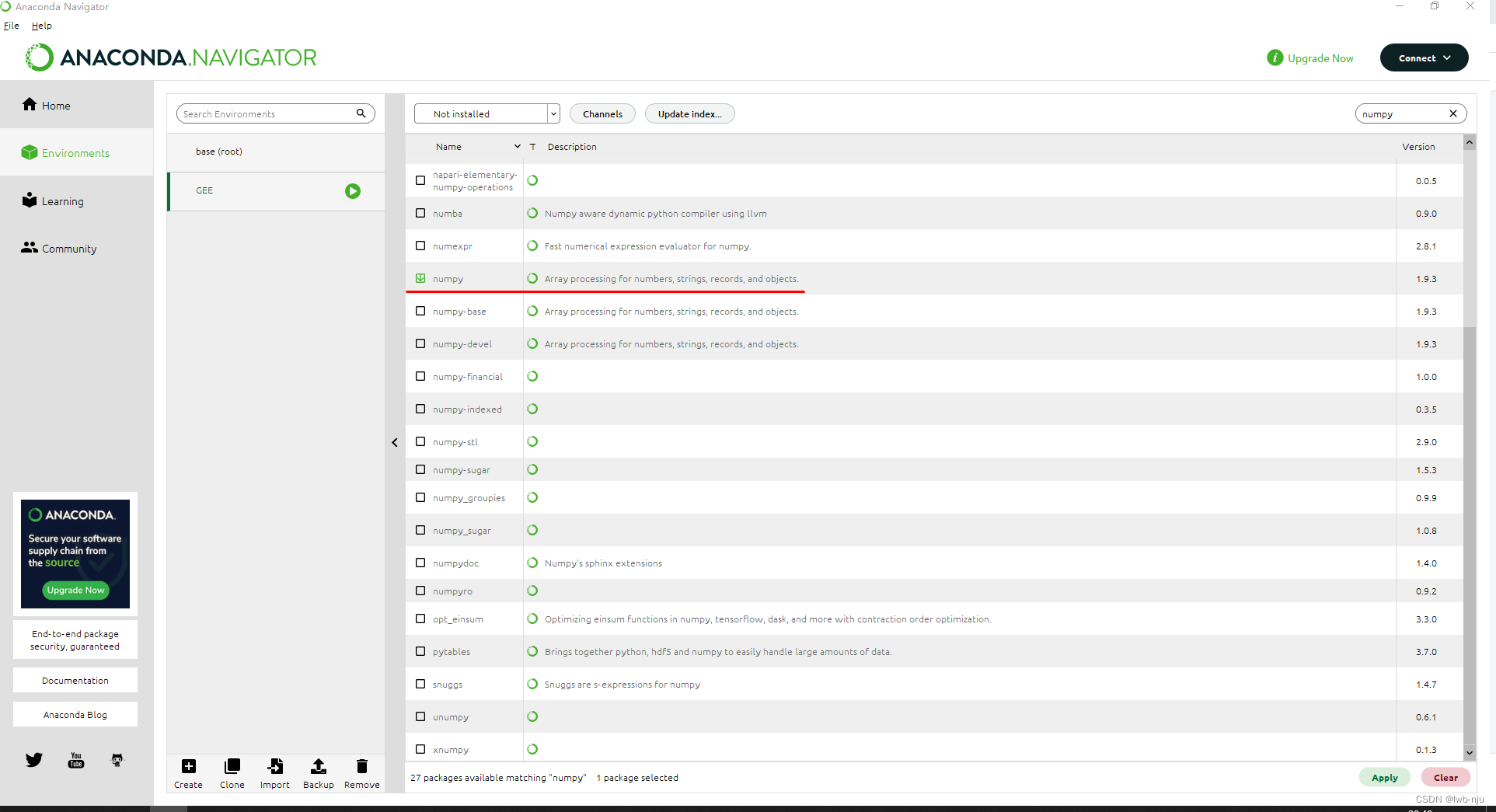
点击apply 进行安装
3、虚拟环境的使用(pycharm内使用)
打开pycharm
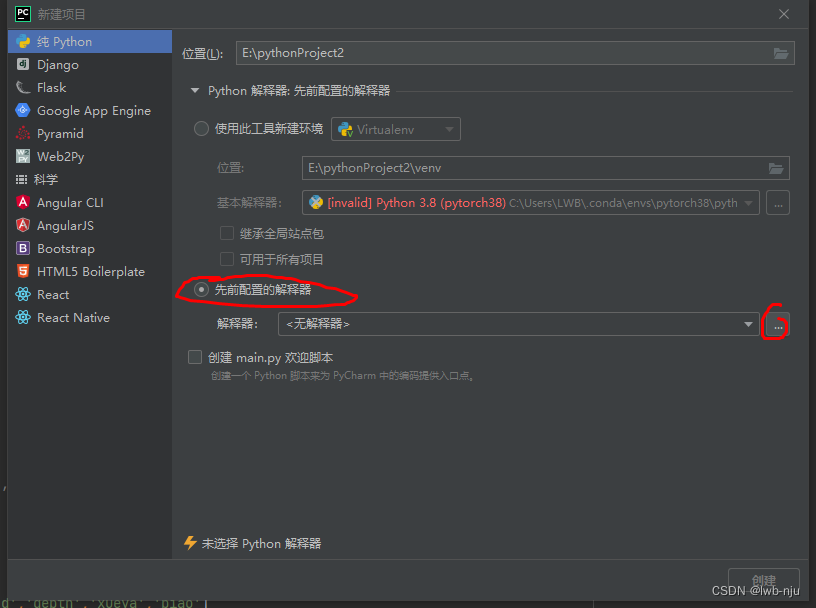
新建项目,使用先前配置的解释器
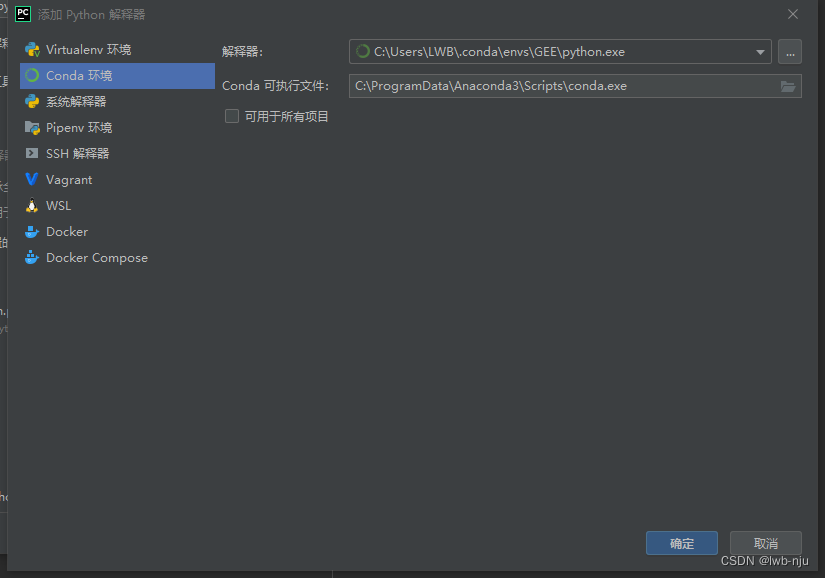
使用conda环境,确定,就可使用
2 数据准备
主要需要准备遥感数据和标签数据,其中遥感数据以landsat8数据为例,标签数据采用目视解译的方法获取。
2.1数据获取
常用遥感地学数据下载网站见下方链接,此处我们以地理空间数据云下载Landsat8数据为例
1.需要注册一个地理空间数据云(地理空间数据云)账号并登录
2.在数据资源中可以查看地理空间数据云提供的各种数据
3.在公开数据中我们可以看到对landsat8数据的解释
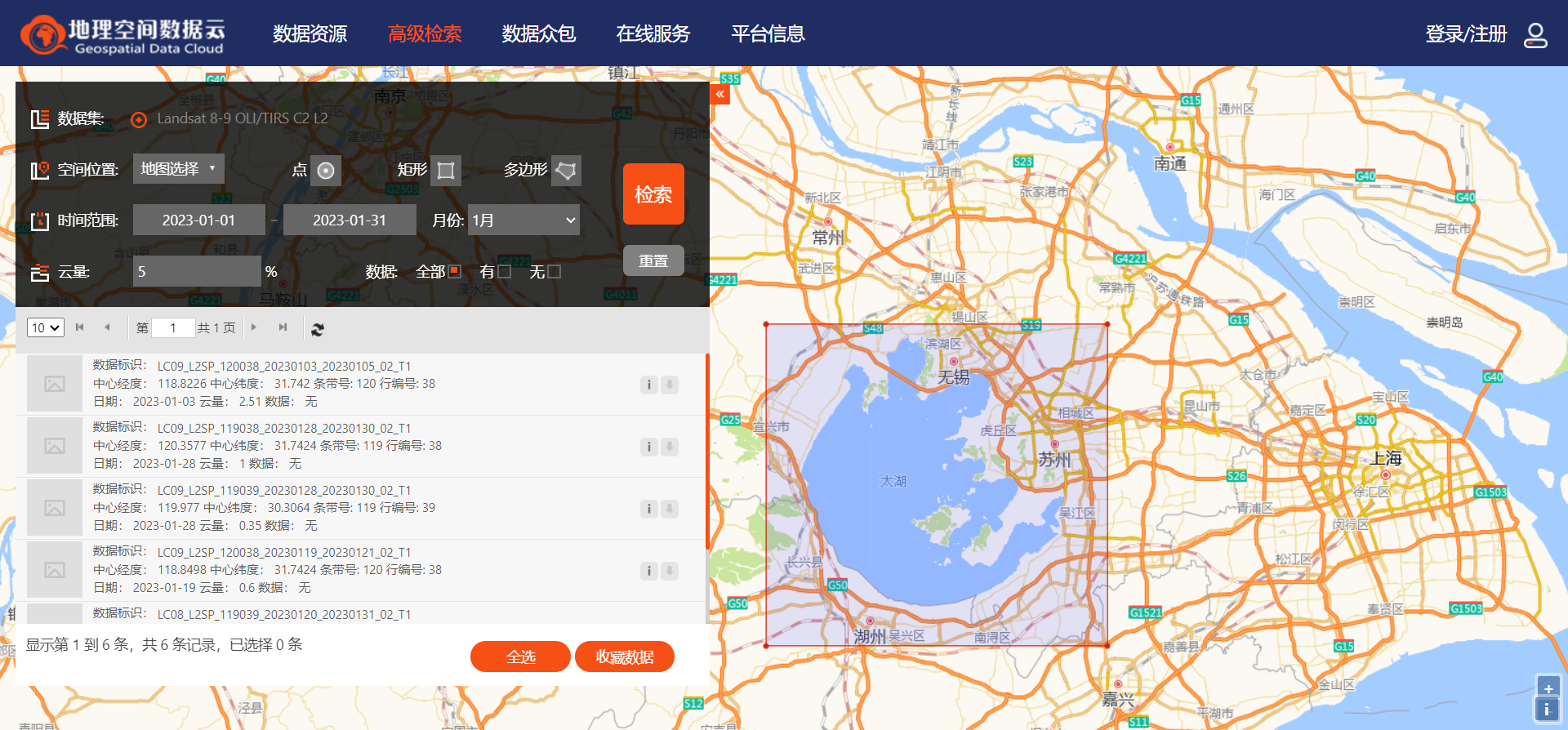
4.在高级检索中使用空间范围和时间信息检索以及云量等信息检索合适的影像
5.这里空间范围以太湖附近为例,选择2023年一月份云量小于5%的影像,可以看到有6景影像被筛选出,选择喜欢的一景下载,进行后续处理与实验
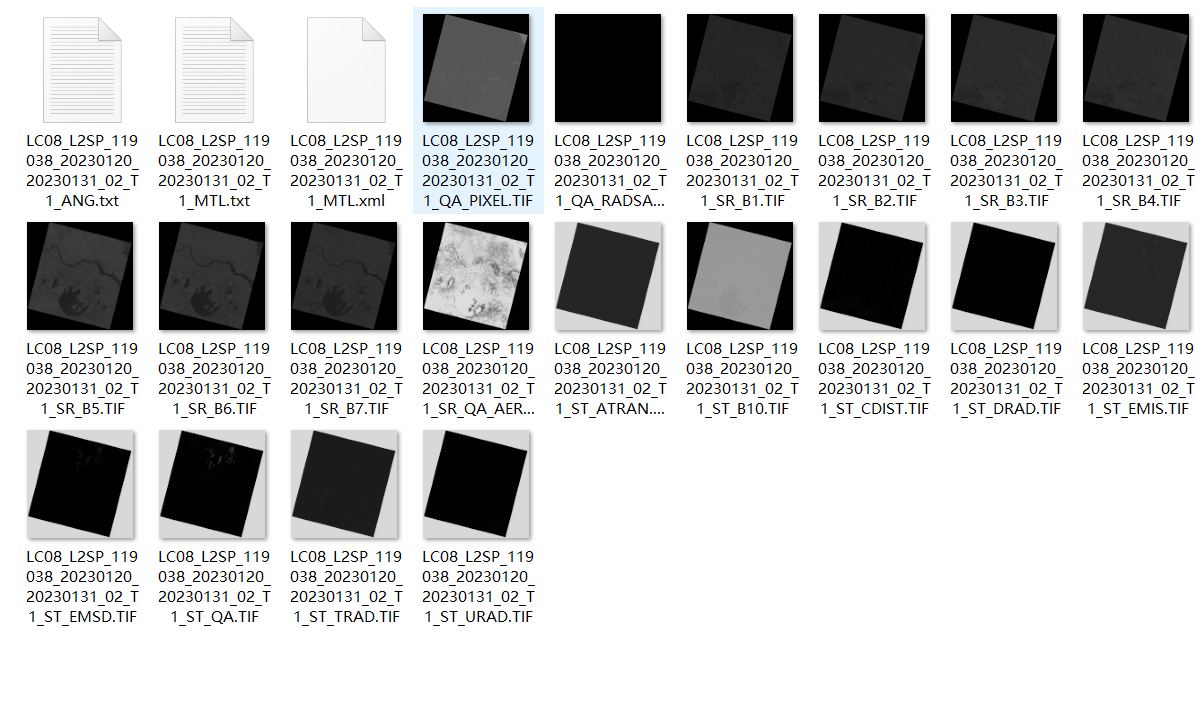
6.我们下载的数据为LC08_L2SP_119038_20230120_20230131_02_T1,数据为tar的压缩包

7.解压后的数据包括一些元数据、数据质量数据和光谱数据
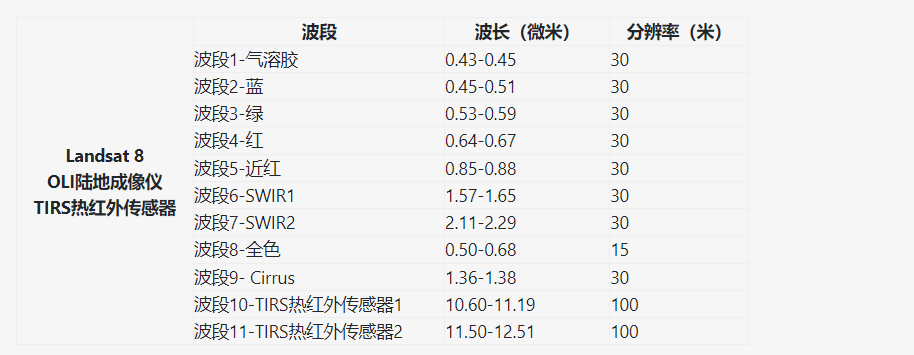
8.为方便后续将各个波段合成为一个tif(band1-7):将band1-7数据拖入envi中
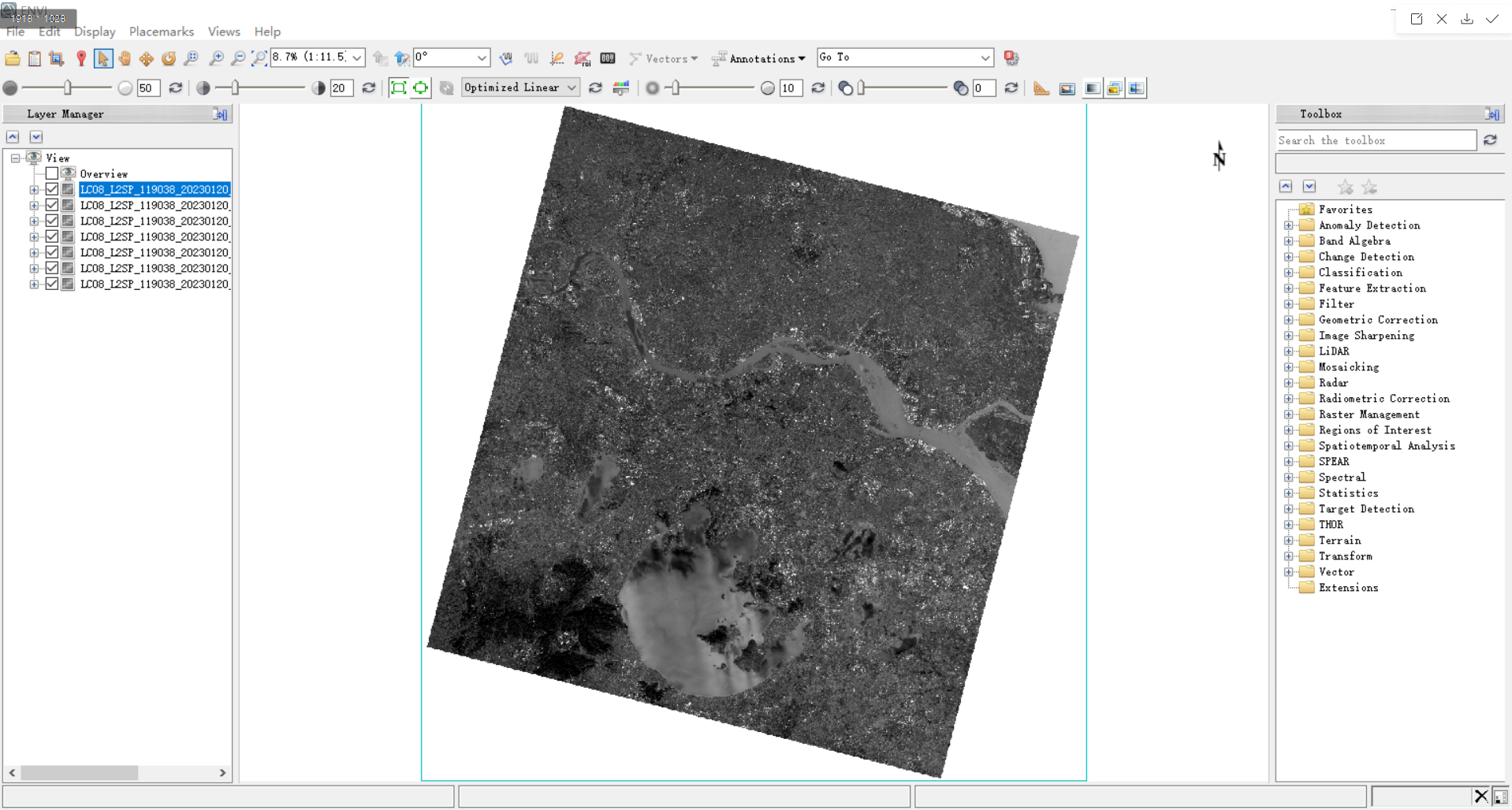
使用layer stacking将各波段数据合成到一个文件中
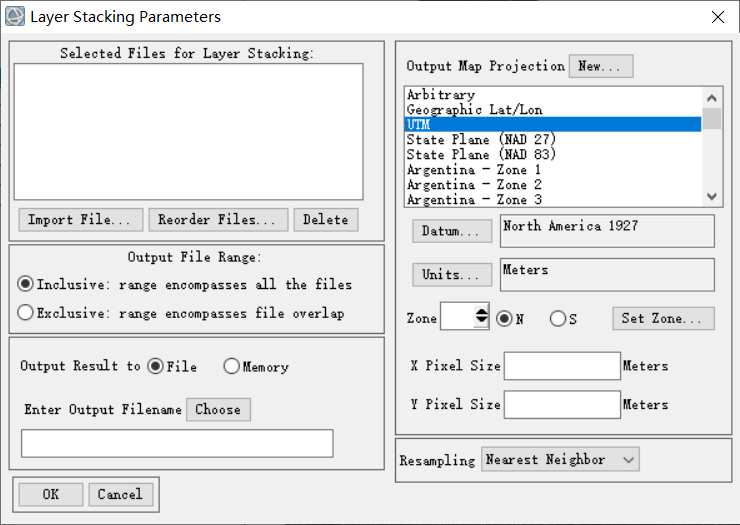
选择数据
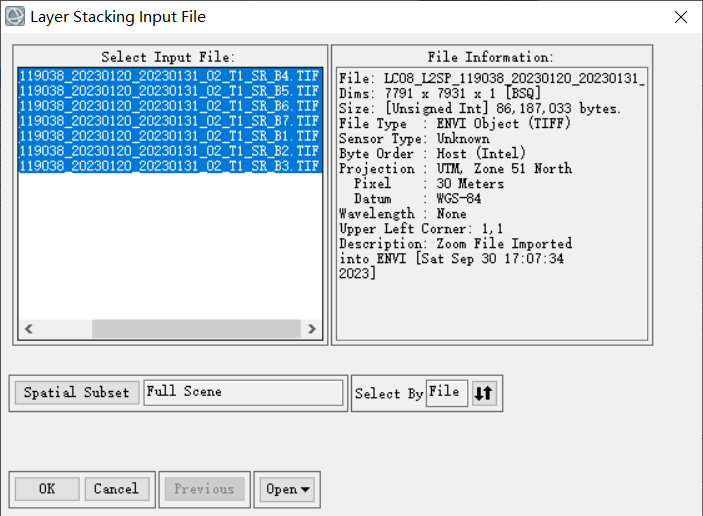
调整波段顺序
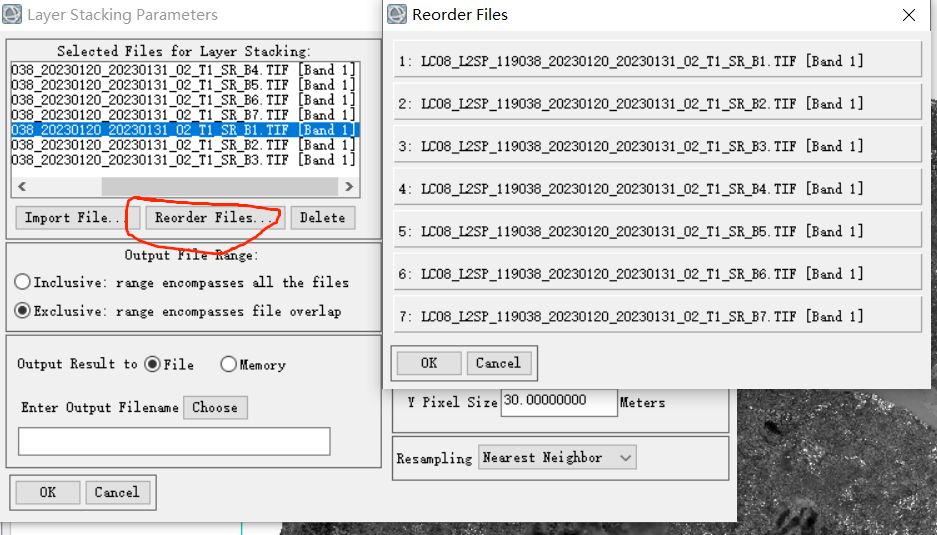
选择保存位置
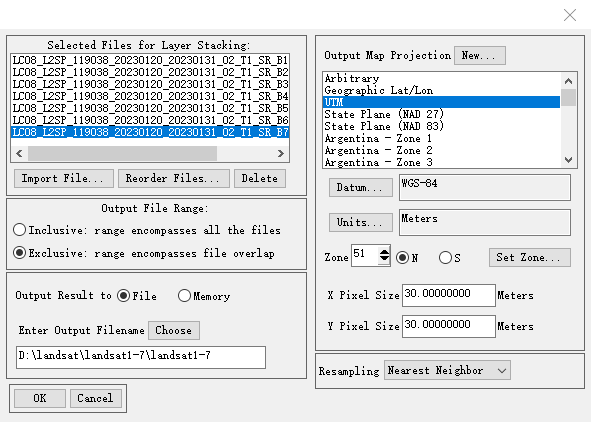
合成后的landsat1-7波段的band:432真彩色合成影像
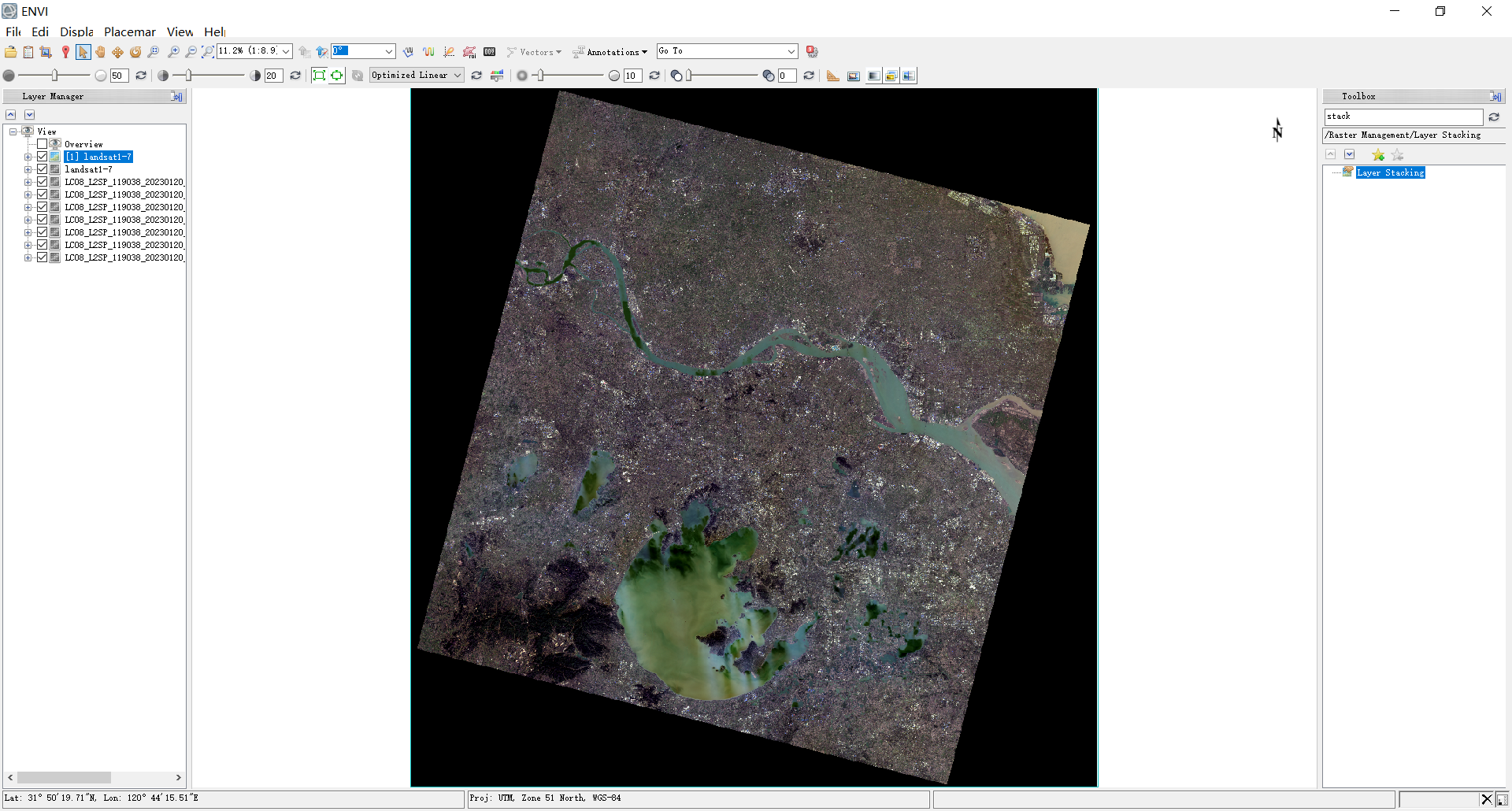
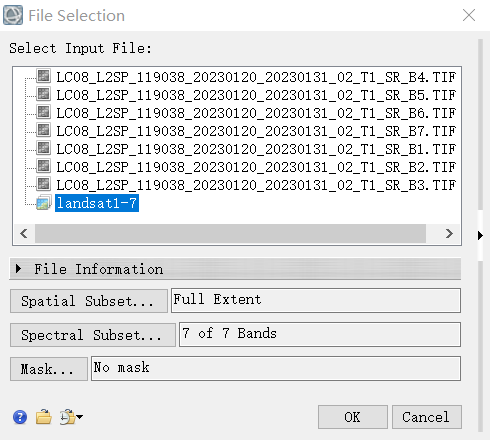
9.现在的数据还不是tif格式,是envi默认的格式,需要将其导出为tif
使用file的save as,将合成的影像导出为tif
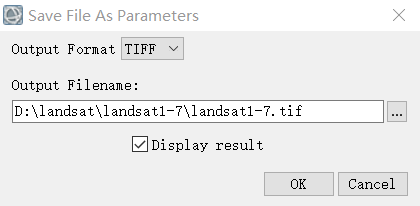
到现在遥感影像数据已经获取完成
2.2数据处理
2.2.1arcgis标签标注
2.2.2 将矢量标注转为栅格
3 地物分类(分类任务)
3.1 读取数据
1.右键数据所在文件夹,用pycharm打开为项目
2.在settings中设置python环境为先前配置的带GDAL和sklearn的环境
3.新建一个文件夹命名为code来存放代码,在code文件夹中新建一个rfc.py
![]()
3.2 数据预处理
5.将数据整合成表的格式,整理成一个8列的表格,前7列是波段数据,最后一列是标签
#数据预处理
#将数据整合成表的格式用于后续处理
data=np.concatenate((img_data,np.expand_dims(lable_data,axis=0)), axis=0)
data=data.reshape(8,-1).T![]()
6.将数据划分为训练集和测试集
x=datas[:,0:7]
# scaler = StandardScaler().fit(x)#标准化,对于随机森林可做可不做
# x=scaler.transform(x)
y=datas[:,7]
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size = 0.7, random_state = 1)3.3 模型训练
7.训练并保存模型
#创建随机森林模型,n_estimators棵树,n_jobs多线程数,max_depth树的最大深度
rfc_model = RandomForestClassifier(n_estimators=20, n_jobs=4,max_depth=8)
# 训练模型
rfc_model.fit(x_train, y_train.ravel())
# 保存模型
joblib.dump(rfc_model, r'D:\landsat\code\rfc_model.pkl')3.4 精度分析
8.计算模型在测试数据集上的精度
# 计算模型在测试数据集上的精度
rfc_model=joblib.load(r'D:\landsat\code\rfc_model.pkl')#加载模型
pre_y=rfc_model.predict(x_test)#对测试集进行预测
y_test = y_test.flatten()
pre_y = pre_y.flatten()
matrix=confusion_matrix(y_test,pre_y,labels=[0,1,2])#混淆矩阵
acc = sklearn.metrics.accuracy_score(y_test,pre_y)#准确率
print(matrix,acc)3.5 模型预测
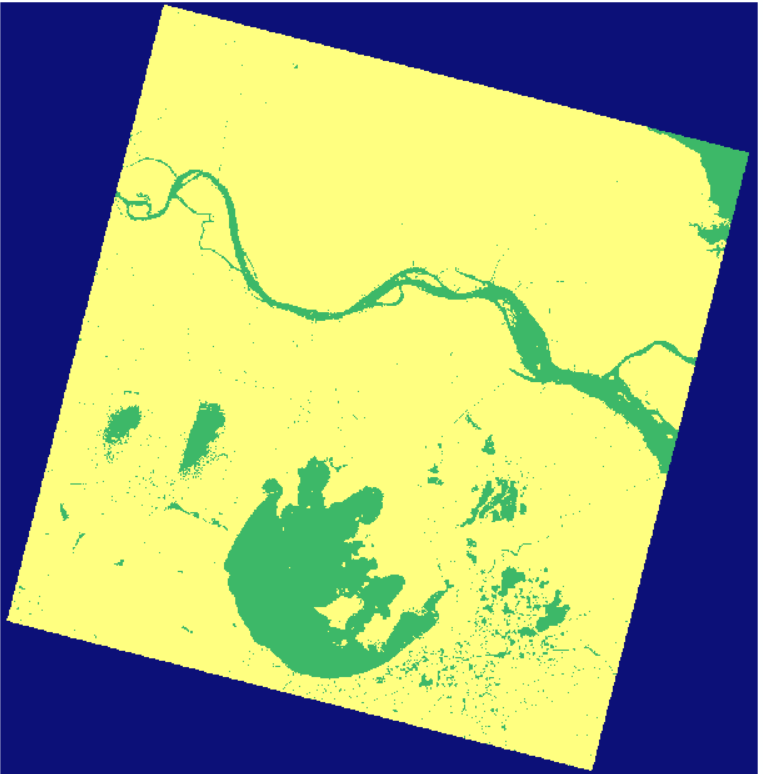
9.对整景影像进行预测并保存为tif
详见闲鱼 GEEDOWNLOAD用户 基于机器学习进行遥感影像的地物分类与参数反演-以随机森林为例
arcgis打开的预测结果
由于回归任务的标签数据获取比较困难,我们这次用水体指数NDWI来模拟作为回归任务的标签,通过随机森林来拟合回归NDWI,其计算公式如下:
NDWI = (band3 - band5) / (band3 + band5)实际情况下需要回归的数据应该比这更加困难,可能是站点数据或者实测数据,可以采用类似分类任务中的操作,使用矢量转栅格将站点数据shp转为与影像行列数一致的栅格数据。
4.1 读取数据
1.在code文件夹内新建rfr.py用来编写回归任务代码
2.导入库
from osgeo import gdal
import numpy as np
from sklearn.model_selection import train_test_split
import joblib
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score
import sklearn3.定义读写函数
3.读取landsat数据,并计算NDWI模拟标签
#读取landsat影像
im_proj, im_geotrans, im_width, im_height, img_data=read_img(r'D:\landsat\landsat1-7\landsat1-7.tif')
#计算NDWI模拟标签
lable_data=(img_data[2].astype(np.float)-img_data[4])/(img_data[2]+img_data[4])4.2 数据预处理
4.数据预处理
#数据预处理
#将数据整合成表的格式用于后续处理
data=np.concatenate((img_data,np.expand_dims(lable_data,axis=0)), axis=0)
data=data.reshape(8,-1).T
#根据标签数据将没有标记的数据筛除没有标记的数据
mask=np.any(np.isnan(data), axis=1)
datas = data[~mask]5.将数据集划分为训练集和测试集
#将数据划分为训练集和测试集
x=datas[:,0:7]
# scaler = StandardScaler().fit(x)#标准化,对于随机森林可做可不做
# x=scaler.transform(x)
y=datas[:,7]
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size = 0.5, random_state = 1)4.3模型训练
6.训练随机随机森林模型并保存
#创建随机森林模型,n_estimators棵树,n_jobs多线程数,max_depth树的最大深度
rfr_model = RandomForestRegressor(n_estimators=20, n_jobs=4,max_depth=8)
# 训练模型
rfr_model.fit(x_train, y_train.ravel())
# 保存模型
joblib.dump(rfr_model, r'D:\landsat\code\rfr_model.pkl')4.4模型预测
7.加载模型计算测试集精度
4.5精度分析
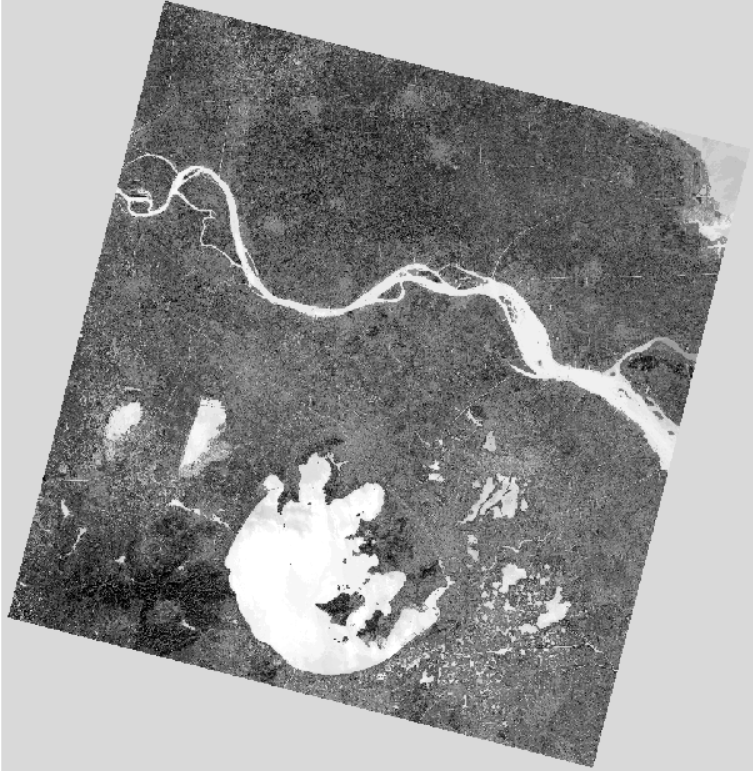
8.对整景影像进行预测并保存为tif
# 对整景影像进行预测并保存为tif
pre_y2 = rfr_model.predict(data[:,0:7])
pre_y2=pre_y2.reshape(im_height,im_width)
write_img(r'D:\landsat\landsat1-7\ndwipre.tif', im_proj, im_geotrans, pre_y2)9.预测结果,这里由于landsat数据没有做辐射校正,所以计算的ndwi绝对大小不准确,但相对大小是对的,水高陆地低。
请见xy geedownload用户
或者xy搜索 基于机器学习进行遥感影像的地物分类与参数反演-以随机森林为例(提供代码与示例数据)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号