

Unity性能优化
Unity性能优化
首先祝大家国庆、中秋双节快乐!时隔挺久没写东西了,一方面加班太多,其实另一方面也是自己懒惰了,不过还好一直都在坚持锻炼,身体和心灵总要有一个在路上。大好假期,外面人太多了,还是在家里学习学习,看看电影来的舒服~这一篇主要是总结了《Unity性能优化》的一些笔记,加之一些其他地方看的内容,仅供学习参考!
一、Profile的使用
1.1 Unity Profile
Profile可以收集Unity中不同子系统中的数据,大致如下:
- CPU消耗量
- 渲染信息和GPU信息
- 运行时的内存分配和总消耗量
- 音频源/数据的使用情况
- 物理引擎(2D/3D)的使用情况
- 网络消息传递和活动的情况
- 视频回放的使用情况
- UI性能
- 全局光照统计数据
通过Profile我们可以通过观察目标函数调用的行为,分配了多少内存来观察程序的工作情况,这种方法为指令注入(instrumentation);另一种方式为基准分析(benchmarking),这种方法的重要指标为渲染帧率(Frames Per Second,FPS)、总体内存消耗和CPU活动(寻找活动中较大的峰值)。相比第一种方式,第二种方式更为常用,从长远看,它会节省大量时间,因为它确保了我们只用关注性能有问题的地方。一般在大体基准分析后,才深入地使用指令注入去改善性能问题。
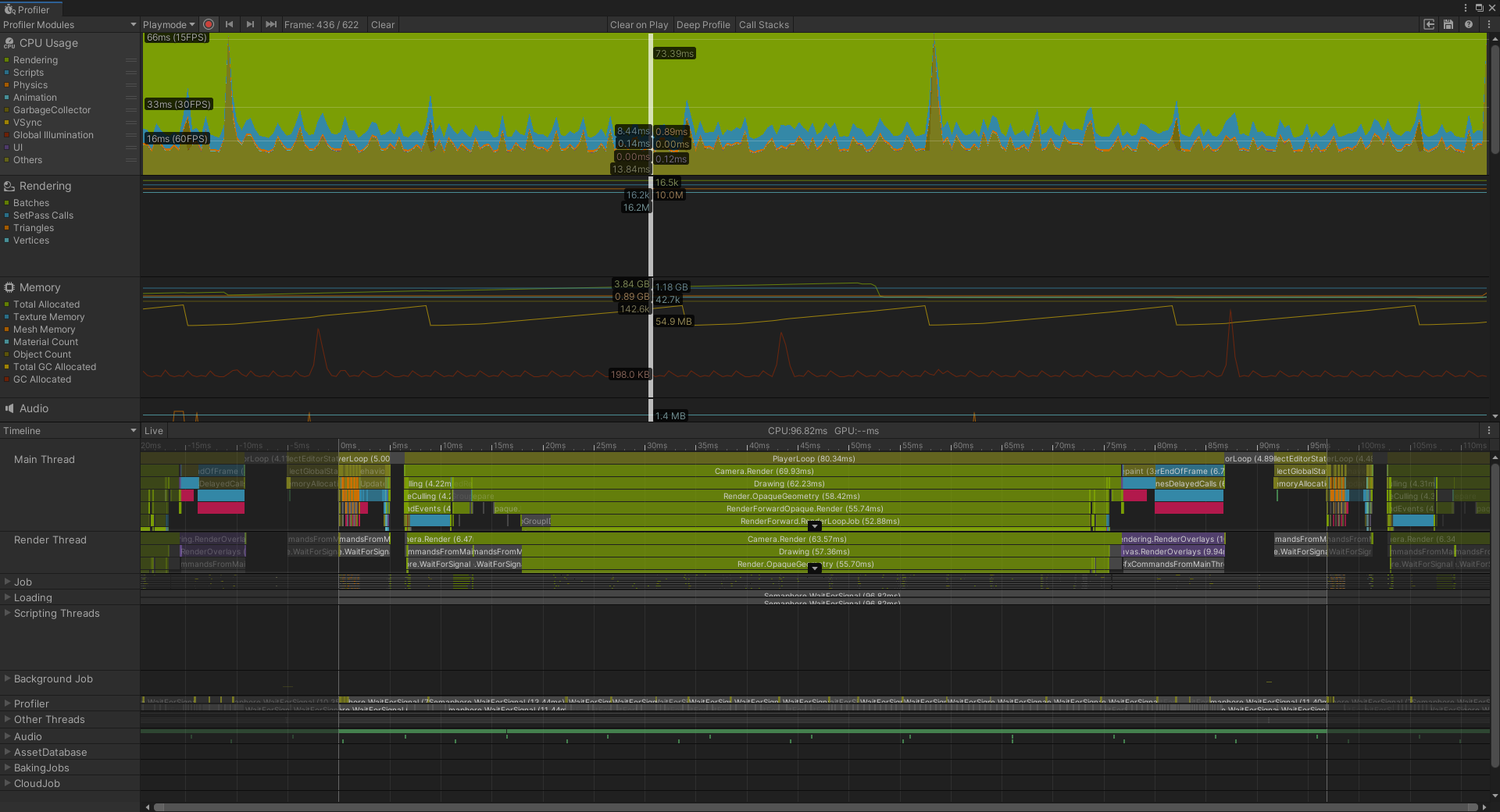
此外,因为在IDE下会带来一些额外的开销或隐藏真实程序中的一些潜在的条件,因此在应用程序以独立格式在目标硬件上运行时,应将分析工具挂接到应用程序中。
1.2 挂接Profile
以下步骤为发布PC程序时所需的步骤,在发布程序时(以Windows为例)需要将Development Build和Autoconnect Profile勾选,如下图:
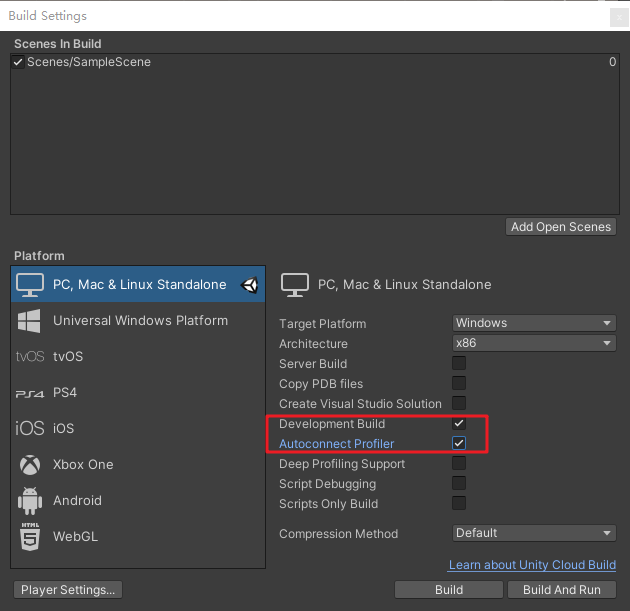
发布程序后,在IDE中启动 Profile(Ctrl+7),并启动应用程序,则Profile会自动连接应用程序并开始收集数据。
此外,还可以连接WebGL实例、远程连接iOS设备、远程连接Android设备,在此不再赘述。
1.3 性能分析方法
一般我们的目标是使用基准分析来观察应用程序,寻找问题行为实例,然后使用指令注入工具在代码中寻找问题的原因。但我们常常被无效的数据分散注意力或忽略了一些细微的细节而得出结论。以下为通用的解决步骤:
- 验证目标脚本是否出现在场景中
- 验证脚本的在场景中出现的次数是否正确
- 验证事件的正确顺序
- 最小化正在进行的代码更改
- 减少内部干扰
- 减少外部干扰
需要注意一下几点:
- 可以采用IDE调试或Debug.Log,但是注意Unity中日志记录在CPU和内存中都非常昂贵,因此不要Debug很频繁,应该只针对代码中最相关的部分进行有针对性的记录,并且对调试的Debug及时注释。
- Unity的Update()次数即使在相同的硬件上,也可能次数不同,例如在这一秒调用60个更新,而在下一秒有可能则调用59个更新,在下一秒可能调用62个更新,因此,程序最好不要依赖于某个对象Update()的特定调用次数。
- 如果一帧需要很长时间处理,比如程序出现明显的卡顿,那么Profiler可能无法获取结果记录在Profiler窗口中。
- 程序如果启动了垂直同步(Vsync,用于将应用程序的帧率匹配到它将显示到的设备帧率,例如显示器的帧率为60Hz,而程序的渲染循环比60Hz快,则程序会等到,指导输出渲染为止),在Profiler中可能会在WaitForTargetFPS下的“CPU使用情况”区域中产生过多嘈杂峰值,因此在查看监视CPU使用情况时,可以先禁用VSync,具体在
Edit|Project Settings|Quality中禁用VSync。
1.4 代码片段针对性分析
根据Profiler窗口可以快速确定哪个MonoBehaviour或方法导致了问题,然后我们需要确定问题是否可以重现,在什么情况下出现性能瓶颈,以及问题代码块中问题的确切来源,为此,我们需要对代码片段进行一些分析,一般分为两类:
- 脚本代码控制Profiler
- 自定义定时和日志记录
1.4.1 Profiler脚本控制
利用UnityEngine.Profiling.Profiler类中的BeginSample()和EndSample(),可以使方法运行时激活和禁用分析功能的分隔符方法。
如以下代码:
private void DoSomething()
{
Profiler.BeginSample("Test Profiler Sample");
var lt = new List<string>();
for (int i = 0; i < 10000000; i++)
{
lt.Add(i.ToString());
}
Profiler.EndSample();
}
1.4.2 自定义CPU分析
除了Unity Profiler之外,还可以利用System.Diagnostics中的Stopwatch类,但是该类最多精确到1/10毫秒,因此为了提高精度,可以利用多次相同测试的平均值来计算平均调用时间,即在一个合理的时间内运行相同测试代码成千上万次,然后总消耗时间除以测试运行次数,以此得到较为精确的单次运行次数。可以自定义定时器,如下:
using System;
using System.Diagnostics;
/// <summary>
/// 自定义方法测试定时器
/// </summary>
public class CustomTestTimer : IDisposable
{
private string _timerName;//计时器名称
private int _numTests;//测试次数
private Stopwatch _wathc;//计时器
public CustomTestTimer(string timerName, int numTests)
{
_timerName = timerName;
_numTests = numTests;
if (numTests <= 0)
_numTests = 1;
_wathc = Stopwatch.StartNew();
}
public void Dispose()
{//当引用using()块结束时调用
_wathc.Stop();
float ms = _wathc.ElapsedMilliseconds;
UnityEngine.Debug.LogFormat("{0} 测试完成,总计用时:{1:0.00}ms,每次测试平均用时:{2: 0.000000}ms,一共测试{3}次",
_timerName, ms, ms / _numTests, _numTests);
}
}
如果要测试某方法,可采用以下方式:
int numTests = 100000;
using (new CustomTestTimer("Controlled Test", numTests))
{
for (int i = 0; i < numTests; i++)
{
TestFunction();
}
};
private void TestFunction()
{
Debug.Log("123");
}
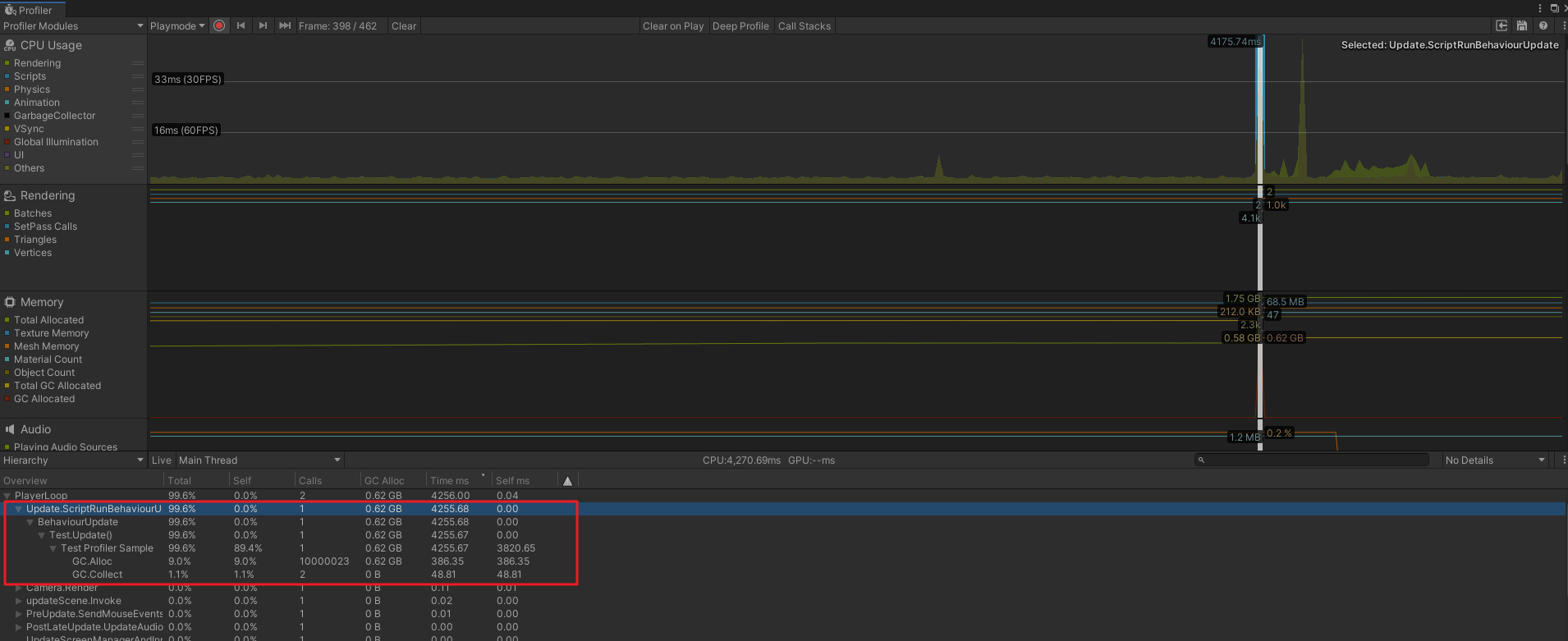
运行后,在程序中如下图:

由此可分析出某方法较为精确的耗时。
二、脚本策略
2.1 获取组件优化
Unity中获取组件GetComponent()有3个可用的重载,分别是GetComponent(string),GetComponent< T >()和GetComponent(typeof(T))。在这三个方法中,最好使用GetCompnent< T >()重载。
此外,GetComponent()方法也不应该运用在类似Update()逐帧计算中,最好的方法是初始化过程中(Awake或Start等)就获取引用并缓存它们,直到需要使用它们为止。同样的技巧也适用于在运行时决定计算的任何数据,不需要要求CPU在每次执行Update()时都重新计算相同的值,因此可以提前将其缓存到内存中。
2.2 移除空的回调定义
在MonoBehaviour脚本中常用其周期函数,常用的有Awake()、Start()、Update()、FixedUpdate()等,这些回调函数会在场景第一次实例化时添加到一个函数指针列表中,又因为在所有的Update()回调(包括场景中所有的MonoBehaviour)完成之前,渲染管线不允许呈现新帧,因此当场景中有大量MonoBehaviour脚本时(包含空的Start()或Update()),场景的初始化以及每帧都会严重消耗资源从而影响帧率。因此我们需要在编写脚本时注意删除空的周期函数,例如Start(),Update()等。
2.3 Update、Conroutines和InvokeRepeating
当我们尝试在Update()中执行某方法时,例如:
void Update()
{
DoSomething();
}
如果该方法占用太多帧率预算,那么提高性能的一个方法是简单地减少DoSomething()的调用频率:
private float _delayTime=0.2f;
private float _timer=0;
void Update()
{
_timer+=Time.deltaTime;
if(_timer>_delayTime)
{
DoSomething();
_time-=_delayTime;
}
}
修改后,该方法由每秒调用60次变为每秒调用5次。以上方法乍一看改进了之前的情形,但代价是需要一些额外的内存来存储浮点数据,且Unity仍要调用一个空的回调函数。我们还可以继续对其进行更改,将其改为协程:
void Start()
{
StartCoroutine(DoSomethingCoroutine());
}
IEnumerator DoSomethingCoroutine()
{
while(true)
{
DoSomething();
yield return new WaitForSeconds(_delayTime);
}
}
以上提到的协程,应于线程进行区别:线程以并发方式在完全不同的CPU内核上运行,而且多个线程可以同时运行,而协程是以顺序的方式在主线程上运行,这样在任何给定时刻都只有一个协程在处理。以上用协程改进后好处是该函数只调用_delayTime值指示的次数,在此之前它一直处于空闲,从而减少对大多数帧的性能影响。然而协程也有以下缺点:
- 与标准函数调用相比,启动携程会带来额外开销成本(大约是标准函数调用的三倍),同时还会分配一些内存,将当前状态存储在内存中,直到下一次调用它。而且这种开销也不是一次性的,因为协程会不断调用yield,这会一次又一次的造成相同的开销成本,所以需要确保降低频率的好处大于此成本;
- 协程运行独立于MonoBehaviour组件中Update()回调的触发,不管组件是否禁用,都将继续调用携程;
- 协程会在包含它的GameObject变成不活动的那一刻自动停止(无论该GameObject被设置为不活动还是它的一个父对象被设置为不活动),且如果GameObject再次被设置为活动,协程也不会自动重新启动;
- 将方法转换为协程,可减少大部分帧中的性能损失,但如果方法体的单次调用突破了帧率预算,则无论该方法的调用次数再怎么少,都将超过预算,因此这种方法只适用于由于在给定帧中调用方法次数过多而导致帧率超出预算的情况,而不适合由于原方法本身太昂贵的情况;
- 协程较难调试,它不遵循正常的执行流程,且在调用栈上没有调用者。如果使用协程,最好使它们尽可能简单,且独立于其他复杂的子系统。
实际上,针对总是在WaitForSeconds或WaitForSecondsRealtime上调用yield协程,可以通常替换成InvokeRepeating()调用,它的建立更简单,且开销较协程小一些,如下:
void Start()
{
InvokeRepeating("DoSomething",0f,_delayTime);
}
InvokeRepeating()与协程的重要区别是,InvokeRepeating()完全独立与MonoBehaviour和GameObject的状态外。此外,停止InvokeRepeating()调用有两个方法:第一种方法是调用CancelInvoke(),它会停止给定MonoBehaviour发起所的所有InvokeRepeating()回调(不能单独取消某个);第二种方法是销毁关联的MonoBehaviour或它的父GameObject。注意,禁用MonoBehaviour或GameObject都不会停止InvokeRepeating()。
2.4 GameObject本机-托管桥接
与C#对象相比,GameObject和MonoBehaviour是特殊对象,因为它们在内存中有两个表示:一个表示存在于管理C#代码相同系统管理的内存中,C#代码是用户编写的(托管代码),另一个表示存在于另一个单独处理的内存空间中(本机代码)。数据可以再这两个内存之间移动,因此每次移动都会导致额外的CPU开销和 可能的额外内存分配,这种效果一般称为跨越本机-托管的桥接。
由以上理论,触发这种额外开销的有以下两种常见情况:
-
对GameObject空引用检查
一般我们使用以下方式对GameObject空引用检查:
if(gameObject!=null){ //DoSomething }另一种更好地方式是利用System.Object.ReferenceEquals(),其运行速度大约是上边的两倍:
if(!System.Object.ReferenceEquals(gameObject,null)) { //DoSomething }以上方式也适用于MonoBehaviour。
-
GameObject的字符串属性
从GameObject中检索字符串属性是另一种意外跨越本机-托管桥接的方式。通常使用的两个属性是tag和name,因此使用这两个属性是不好的,然而GameObject提供了
CompareTag()方法,它则完全避免了本机-托管的桥接。即使用gameObject.CompareTag("tag")而不是使用gameObject.tag=="tag"。除此之外,name属性没有对应方法,因此尽可能使用Tag属性。
2.5 运行时修改Transform的父节点
Transform组件的父-子关系比较像动态数组,因此Unity尝试将所有共享相同父元素的Transform按顺序存储在预先分配的内存缓冲区中,并在Hierarchy窗口中根据父元素下面的深度进行排序。这种数据结构允许整个组中进行更快的迭代,对于物理和动画等多个子系统有利,但是如果将一个GameObject的父对象重新指定为另一个对象,父对象必须将子对象放入预先分配的缓冲区中,并根据新的深度对所有Transform进行排序。另外如果父对象没有预先分配足够的空间,就必须扩展缓冲区。对于较深、复杂的GameObject结构,这需要一些时间来完成。
通过GameObject.Instantiate()实例化新的GameObject时,想为其设置一个父物体,在我们使用时很多情况会写成类似以下代码:
GameObject listItem = (GameObject)Instantiate(Resources.Load("Prefabs/UI/Items/PersonListItem"));
listItem.transform.SetParent(m_PersonSelectContnt, false);
以上情况在listItem实例化之后立即将Transform的父元素重新修改为另一个元素,它将丢弃一开始分配的缓冲区,为了避免这种情况,应该将父Transform参数提供给GameObject.Instantiate()调用,这调用可跳过这个缓冲区分配步骤,从而提升一部分性能:
GameObject listItem = (GameObject)Instantiate(Resources.Load("Prefabs/UI/AMMT/Items/PersonListItem", m_PersonSelectContnt, false));
2.6 减少对Transform的改变
不断更改Transform组件属性,也同时会向其他组件(如Collider、Rigidbody、Light、Camera等)发送内部通知,这些组件也必须进行处理,因为物理和渲染系统都需要知道Transform的新值,并相应进行更新。
在复杂的过程中,在同一帧中多次替换Transform组件的属性很常见,每次Transform发生改变时,都会触发内部消息。因此,应该尽量减少修改Transform属性的次数,方法是将其变化缓存在一个成员变量中,只在帧的末尾修改Transform值,如下所示:
private bool _positionChanged;
private Vector3 _newPosition;
public void SetPosition(Vector3 pos)
{
_newPosition = pos;
_positionChanged = true;
}
private void FixedUpdate()
{
if (_positionChanged)
{
transform.position = _newPosition;
_positionChanged = false;
}
}
用以上逻辑仅在下一个FixedUpdate()中提交对position的更改,从而减少对Transform的改变。
2.7 避免在运行时使用Find()和SendMessage()
SendMessage()和GameObject.Find()方法非常昂贵,应不惜一切代价尽量避免使用。Find()会迭代场景中的每个GameObject对象。不过,在场景初始化期间调用Find()有时是可以的,例如在Awake()或Start()中。
2.8 Vector计算
如果需要比较距离而非计算距离,用SqrMagnitude代替Magnitude可以避免一次耗时的开放运算。
在进行向量乘法计算时,有一点需要注意乘法顺序,因为向量乘比较耗时,所以我们应该尽可能减少向量乘法运算。可以基于之前CustomTestTimer来做一个实验:
private void Start()
{
int numTests = 1000000;
using (new CustomTestTimer("向量在中间", numTests))
{
for (int i = 0; i < numTests; i++)
{
Func1();
}
}
using (new CustomTestTimer("向量在最后", numTests))
{
for (int i = 0; i < numTests; i++)
{
Func2();
}
}
}
private void Func1()
{
Vector3 a = 3 * Vector3.one * 2;
}
private void Func2()
{
Vector3 a = 3 * 2 * Vector3.one;
}
最终结果如下:

由结果可以看出,以上两个方法结算结果相同,但是Func2却比Func1耗时少,因为后者比前者少了一次向量乘法。所以,应该尽可能合并数字乘法,最后再进行向量乘。
2.9 循环
在迫不得已需要写多重循环时,应该尽量把遍历次数较多的循环放在内层。做测试如下:
private void Start()
{
int numTests = 10000000;
using (new CustomTestTimer("大循环在外", numTests))
{
for (int i = 0; i < numTests; i++)
{
for (int j = 0; j < 2; j++)
{
int k = i * j;
}
}
}
using (new CustomTestTimer("大循环在内", numTests))
{
for (int i = 0; i < 2; i++)
{
for (int j = 0; j < numTests; j++)
{
int k = i * j;
}
}
}
}
测试结果如下:

三、批处理
首先介绍一下批处理,批处理主要是指将大量任意数据块组合在一起,并将它们作为单个大数据块进行处理的过程。在Unity中的批处理主要分为动态批处理和静态批处理,这两种方法本质是几何体合并的两种不同形式,用于将多个对象的网格数据合并到一起,并在单一指令中渲染它们,而不是单独准备和绘制每个几何体。
3.1 Draw Call
批处理的主要目的即是减少Draw Call,Draw Call是指一个从CPU发送到GPU用于绘制对象的请求。这里注意的是,若Draw Call过高导致画面帧率变低,是由于CPU的提交速度瓶颈导致,而不是GPU。
减少Draw Call的开销:
- 避免使用大量很小的网格。当不能避免需要使用很小的网格时,可以考虑是否可以合并网格。
- 避免使用过多的材质。尽量在不同的网格之间共用同一材质。
3.2 动态批处理
动态批处理有以下优点:
- 在运行时生成(批处理是动态生成的)
- 批处理中包含的对象在不同帧之间可能有所不同,这取决于哪些网格在主相机视图中当前是可见的(批处理的内容是动态的)
- 在场景中运动的对象也可以批处理(对动态对象有效)
动态批处理是Unity自动生成的,功能开关在Edit|Project Settings|Player|Other Settings|Dynamic Batching。
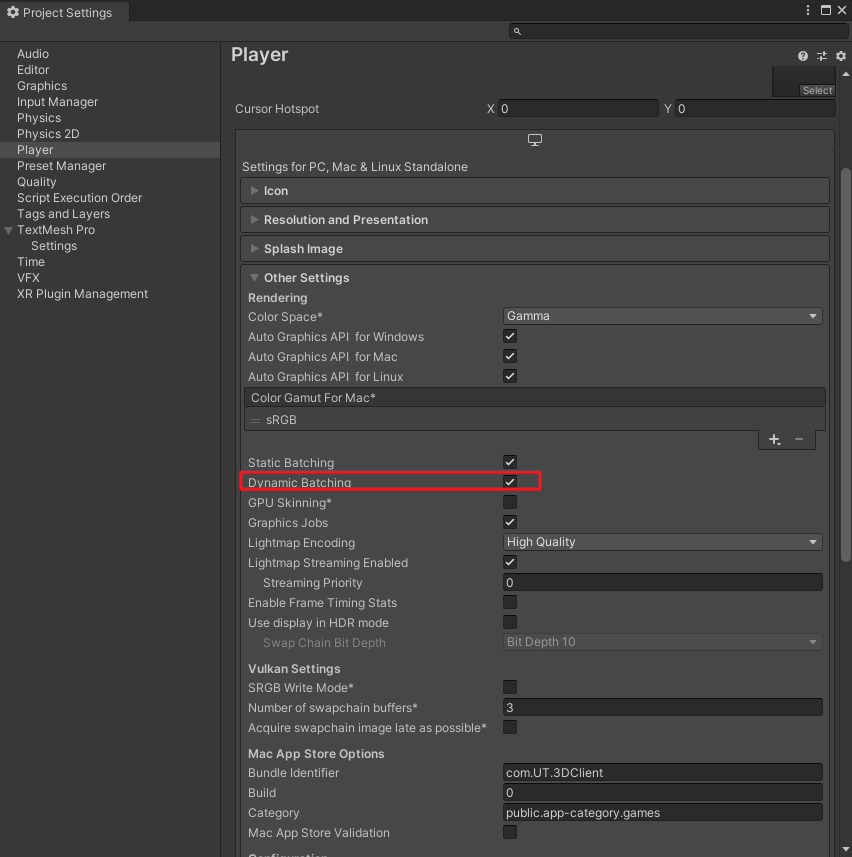
使用动态批处理的要求如下:
- 所有网格实例必须使用相同的材质引用(此处为“材质引用”,如果两个不同的材质但它们设置相同,渲染管线还是不能执行动态批处理);
- 只有ParticleSystem和MeshRenderer组件进行动态批处理。SkinnedMeshRenderer组件(用于角色动画)和其他可渲染的组件类型不能进行批处理;
- 每个网格至多有300个顶点;
- 着色器使用的顶点属性(例如顶点位置、发现向量、UV坐标、颜色信息等等)不能大于900;
- 所有网格示例要么使用等比缩放,要么使用非等比缩放,但不能两者混用;
- 网格实体应该引用相同的光照纹理文件;
- 材质的着色器不能依赖多个过程;
- 网格实体不能接受实施投影;
- 整个批处理中网格索引的总数有上限,这与所用的Graphics API和平台有关,一般索引值在32~64K之间。
动态批处理在渲染大量简单网格时是非常有用的工具,在工程中,动态批处理的自动进行的,而我们需要注意一点:可以阻止两个简单对象动态批处理的唯一条件是,它们使用了不同的纹理,因此,我们应该将它们的纹理合并(通常称为图集),并重新生成网格UV,以便进行动态批处理。当然这样可能会牺牲纹理的质量,或者纹理文件会变大。
3.3 静态批处理
对动态批处理相对,静态批处理功能类似于动态批处理,但是它只处理标记为Static的对象。静态批处理的要求:
- 网格实体必须标记为Static,其副作用即是任何想要使用静态批处理的对象都不能通过任何方式移动、旋转和缩放;
- 每个被静态批处理的对象都需要额外的内存;
- 合并到静态批处理中的顶点数量是有上限的,与Graphics API和平台的不同而不同,一般为32~64K个顶点;
- 网格实例可以来自任何模型,但是它们必须使用相同的材质引用。
四、艺术资源优化
在上一章已经提到过一些关于艺术资源的优化,例如合并贴图、减少网格等,下面我们详细看一下Unity中艺术资源的优化。
4.1 纹理贴图
一般纹理是一张图片,它会告诉插值程序,图像的每个像素应该是什么颜色。下面直接来讲纹理优化的要点。
-
减小纹理文件的大小
给定的纹理文件越大,推送纹理所消耗的GPU内存带宽就越多。如果每秒推送的总内存超过显卡的总内存带宽,就会产生瓶颈,因为在下一个渲染过程开始之前,GPU必须等待所有纹理都上传完毕。减小纹理大小的方式很多,可以有以下两点:
- 降低纹理的分辨率
- 降低纹理的位数(最低为8)
-
使用图集
图集可以将许多较小的、独立的纹理合并到一个较大的文理文件中,从而最小化材质的数量,因此最小化所需使用的Draw Call数量。这样做的额外工作是需要修改网格或精灵对象的UV,只采样大纹理文件中所需的部分。但好处也是明显的,这样会减少Draw Call降低CPU工作负载,提升帧率。注意,由于推送到GPU的数据是一样的,因此图集不会减少内存带宽消耗,它只是将多张图片打包到一张更大的文理文件中。
当然图集只是当所有给定的纹理需要相同的着色器时采用的一种方法,如果一些纹理需要通过着色器应用独立的图形效果,它们就必须分离到自己的材质中,并在单独的组中打图集。
-
调整非正方形纹理的压缩率
纹理文件通常以正方形、2的n次方幂的格式保存,要避免非2的n次幂的纹理。
4.2 模型网格
模型网格也是影响性能的另一个资源。下面来讲一下网格优化的一些注意点。
-
减少网格多边形数量
这是提升性能最明显的方法之一,通常模型采用的是精细的纹理和复杂的阴影来提供大部分细节,这样我们就可以从网格上去掉许多顶点从而优化模型和性能。
-
恰当使用Read-Write Enabled
Read-Write Enabled标志允许在运行时通过脚本读取/修改网格,禁用改选项会使Unity在确定要使用的最终网格后,从内存中丢弃原始网格数据,因此如果在整个过程中只是用网格的等比缩放版本,则禁用该选项会节省运行时的内存。但如果模型网格需要在运行时以不同的比例重新出现,那么Unity会在该选项禁用时每次重新导入网格重新加载网格数据,还需要同时生成重新缩放的副本,因此启用Read-Write Enable是明智的。
-
合并网格
将多个模型网格合并成单个的大型网格,便于减少Draw Call,特别是当网格对于动态批处理来说过大,不能与其他静态批处理组很好地配合时。
4.3 项目实践
这里是我通过项目实践的内容,属于内部资料,因此不详细写了,主要目的其实就是在建模时,应对模型的材质和贴图要求复用,相同的材质、贴图不能重复,除此之外,需要对导入Unity的模型、贴图、材质进行管理,主要是要建立材质库,使得新导入的模型尽可能地引用已有的材质球。这样做也可以将材质与模型分离,达到在Unity中可以编辑模型材质的优点。
五、内存管理
5.1 Unity中的内存域
Unity中的内存空间本质上可以划分为3个不同的内存域,每个域存储不同的数据类型,关注不同的任务集。
- 托管域,该域是Mono平台工作的地方,我们编写的任何MonoBehaviour脚本和自定义的C#类在运行时都会在此域实例化对象 ,托管域的内存空间会被自动被垃圾回收管理。
- 本地域,该域我们会间接与之交互。Unity一些底层代码由C++编写,并根据目标平台编译到不同的应用程序中。该域关系Unity内部内存空间的分配,如为各种子系统(如渲染管线、物理系统、UI等)分配资源数据(如纹理、网格、音频等)合内存空间。此外,它还包括GameObject和Component等重要游戏对象的部分本地描述,也是大多数内建Unity类(如Transform、RigidBody等)保存数据的地方。
- 外部库,例如DirectX和OpenGL库,也包括项目中很多自定义的库和插件。
以上托管域也包含存储在本地域中的对象描述的包装器,因此当和Transform等组件交互时,大多数指令会请求Unity进入它的本地代码,在那里生成结果,然后再将结果复制回托管域,这正是本地-托管桥的由来。当两个域对相同实体有自己的描述时,跨越它们需要内存进行上下文切换,从而会带来一些严重的潜在性能问题。
5.2 内存管理性能增强
-
垃圾回收策略
最小垃圾回收问题的一种策略实在合适的时间手动触发垃圾回收,当确定用户不会注意到这种行为时就可以偷偷触发垃圾回收,垃圾回收可以通过
System.GC.Collect()手动调用。甚至可以在运行时使用Profiler.GetMonoUsedSize()和Profiler.GetMonoHeapSize()方法决定是否需要调用垃圾回收。当然,最好的垃圾回收策略是避免垃圾回收。 -
字符串
字符串本质是字符数组,因此字符串在内存中是连续的,当字符串再分配内存后就不可变了,即字符串是不可变的引用类型。对字符串的修改、合并、连接等操作都需要创建新的字符串。因此字符串的使用需要注意以下几点:
- 如果提前大致知道字符串的最终大小,那么可以使用StringBuilder类提前分配一个适当的缓冲区来存储或修改字符串。
- 如果不知道结果字符串的最终大小,使用StringBuilder可能不会生成大小合适的缓冲区,因此可以采用string.Format()、string.Join()和string.Concat()。
-
Unity API中的数组
Unity API中有很多指令会导致堆内存分配,本质上包括了所有返回数组数据的指令,例如以下方法:
GetComponents< T >(); //(T[])
Mesh.vertices; //(Vector3[])
Camear.allCameras; //(Camear[])
每次调用这类API方法时,都会导致分配该数据的新内存,这些方法应该尽可能避免,或者仅调用很少次数并缓存结果,避免比实际所需要更频繁的内存分配。
-
循环子物体
有时我们迭代子物体时,可能会使用foreach写成以下类似形式:
foreach(Transform child in transform){ //Dosomething with 'child' }以上写法会导致堆分配问题,因此应避免以上代码风格,而是用以下形式:
for(int i=0;i<transform.childCount;i++){ var child = transform.GetChild(i); //Dosomething with 'child' }
六、程序设置
6.1 纹理
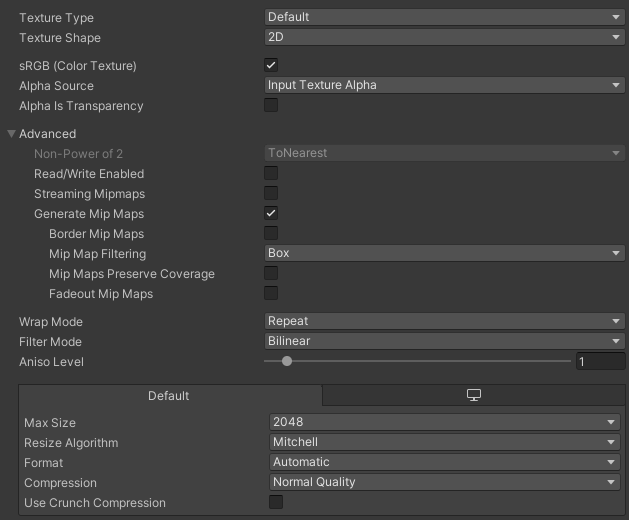
Read/Write Enabled:如果不需要运行时读取图片的像素信息的话,禁用,否则启用后纹理的内存消耗会增加一倍。Generate Mip Maps:Mipmaps和模型的LOD类似,会根据相机距离远近降低或提升贴图像素,但是会多出三分之一的内存开销,如果不是模型贴图,则可以禁用,此外,UI的贴图基本用不到,可以禁用。Max Size:视情况而定,在2019.4版本Unity中最大可以达到8192*8192,但一般不要过大,否则贴图单个文件大小过大。
6.2 模型
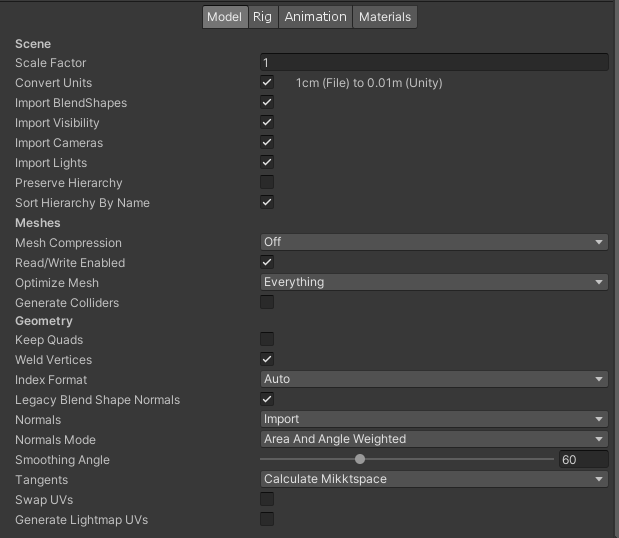
Model
Mesh Compression:压缩比越高模型文件越小,需要根据项目实际效果决定,我们项目目前都将其设为Off。Read/Write Enable:如果不需要修改模型时,可以禁用,否则启用后模型内存消耗会增加一倍。但是注意,之前也说过,由于项目中使用了Runtime Editor插件,与该插件需要配合的模型要将此项启用。Optimize Mesh:默认Everything,可以提升GPU性能。Normals:如果模型没有法线信息,可以将其设置为None,减小模型大小。
Rig
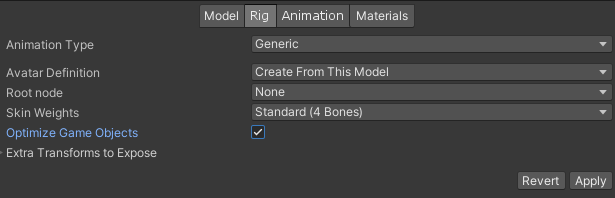
Animation Type:如果模型没有动画,将其设置为None。Optimize Game Objects:在使用Animator制作动画时,将该项启用,可以将暴露在Hierarchy的子节点移除,极大减少了模型的层级和Children的数量,从而提升运行时的性能。如有挂节点需求,在Extra Transform to Expose中添加需要暴露的子节点即可。
6.3 其他
Quality
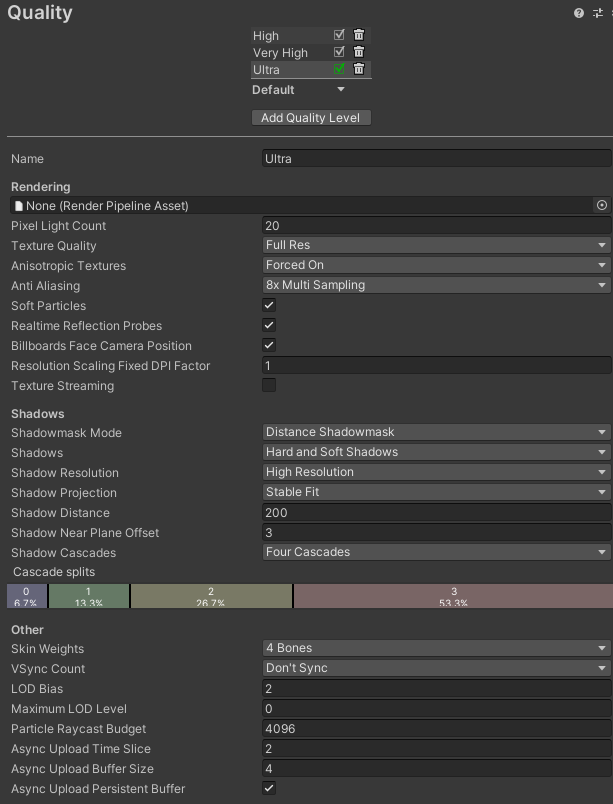
-
Pixel Light Count:场景使用正向渲染时的最大像素光源数。该值过小的话,假如在某个范围内有多个光源,则这个范围只会有最多设置值个光源产生光照作用,随机某些光源不会发光。但是由于实时光照性能消耗过大,叠加光照对于性能消耗呈指数级增长,因此该值也不宜设置太大,根据项目需求设置。 -
Texture Quality:贴图质量,如果选择Half Res,这样速度会更快,但是贴图质量会下降。 -
Anisotropic Textures:是否启用各向异性纹理,如果选择Forced On,则为始终启用。该项针对以下问题时可能产生效果:
可以看到在开启前画面有模糊,开启后被修正为正常的,即该选项可以修正曲面倾斜后的贴图。
-
Anti Aliasing:抗锯齿级别设置,有Disable,2x,4x和8x,倍数越高画面锯齿感越低,但是性能相对越低。 -
Shadow Resolution:阴影分辨率,分辨率越高,开销越大。采用Medium Resolution即可。 -
Shadow Distance:相机与阴影可见距离的最大距离,超出此距离则阴影不会渲染。 -
VSync Count:垂直同步选项,该选项可以与显示设备的刷新速率同步,防止出现“画面撕裂”。根据我们项目的需求,建议设置为Don't Sync。 -
上传管线AUP相关设置
Async Upload Time Slice:该参数设定渲染线程中每帧上传纹理和网格数据所用的时间总量,以毫秒为单位。当异步加载操作时,该系统会执行两个该参数大小的时间切片,默认值为2毫秒。如果该值太小,可能会在纹理/网格的GPU上传遇到瓶颈。如果该值太大,可能会造成帧率陡降。Async Upload Buffer Size:该参数设定环形缓冲区的大小,以MB为单位。当上传时间切片在每帧发生时,要确保在环形缓冲区有足够的数据利用整个时间切片。如果环形缓冲区过小,上传时间切片会被缩短。该值默认为4MB,可适当提高至16MB。Async Upload Persistent Buffer:该选项决定在完成所有待定读取工作时,是否释放上传时使用的环形缓冲区。分配和释放该缓冲区经常会产生内存碎片,因此通常将其设置为True。如果需要在未加载时回收内存,可以将该值设为False。- 关于AUP的其他内容可参考以下网站内容:优化加载性能:了解异步上传管线AUP。
Player Settings
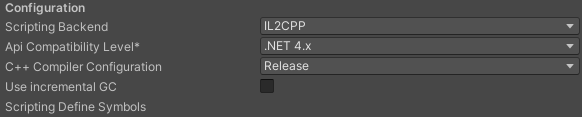
Scripting Backend:可以选IL2CPP,转成C++代码后性能得到提升,同时也变相提供了C#代码的混淆。C++ Compiler Configuration:默认选择Release,如果发布的话,可以改成Master,这样打包速度虽然会慢一些,但是编译的C++代码会更加优化一些。
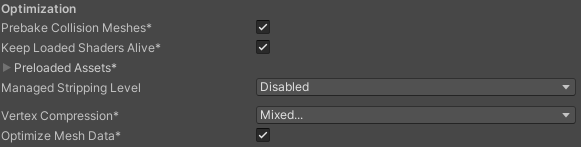
Prebake Collision Meshes:启用,用构建的时间换运行时的性能。Keep Loaded Shaders Alive:启用,因为Shader的加载和解析很耗时,所以不希望Shader被卸载。Optimize Mesh Data:启用,减少不必要的Mesh数据,降低包的大小。
写文不易~因此做以下申明:
1.博客中标注原创的文章,版权归原作者 煦阳(本博博主) 所有;
2.未经原作者允许不得转载本文内容,否则将视为侵权;
3.转载或者引用本文内容请注明来源及原作者;
4.对于不遵守此声明或者其他违法使用本文内容者,本人依法保留追究权等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号