

ML-Agents(二)创建一个学习环境
ML-Agents(二)创建一个学习环境
一、前言
上一节我们讲了如何配置ML-Agents环境,这一节我们创建一个示例,主要利用Reinforcement Learning(强化学习)。
如上图,本示例将训练一个球滚动找到随机放置的立方体,而且要避免从平台上掉下去。
本示例是基于ML-Agents官方的示例,官方有中文版和英文版两个文档,英文版的是最新的,中文版中大部分内容和英文版的一致,但也有不同,本文是基于最新版所做(v0.15.0,master分支),需要参考官方文档的也可参照如下地址食用。
英文:https://github.com/Unity-Technologies/ml-agents/tree/master/docs
二、概述
在Unity项目中使用ML-Agents涉及以下基本步骤:
- 创建一个容纳agent的环境。该环境可以从包含少量对象的简单物理模拟环境到整个游戏或生态系统,环境的样式可以多种多样;
- 实现Agent子类。Agent子类定义了必要的代码以供agent用于观测自身环境、执行指定动作以及计算用于强化训练的奖励。你同样可以实现可选方法,从而在agent完成任务或任务失败时重置agent;
- 将实现Agent子类的脚本加到适当的GameObject上,当该对象在场景中,即代表对应agent在模拟环境中了。
(PS.在官方中文文档中,第2,3步需要实现Academy子类和Brain,但在新版中,这两个东西已经不需要在场景里定义了,所以比较重要的就是这个Agent子类,基本学习逻辑都在这里)
三、设置Unity项目
第一步,我们先新建一个Unity项目,并且将ML-Agents包导入到里面:
-
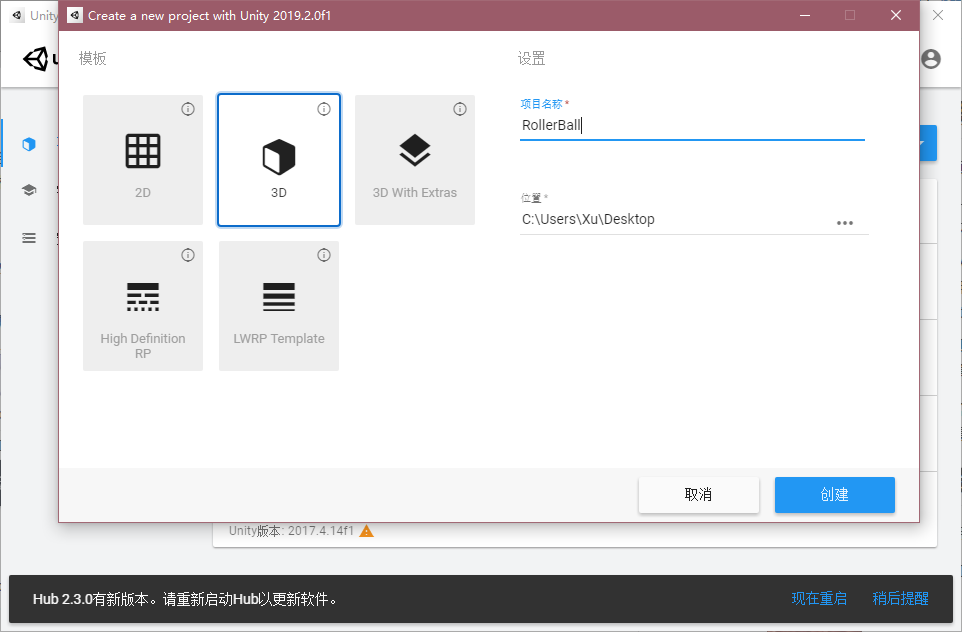
打开Unity,新建一个项目随意叫个名字,例如“RollerBall”;
-
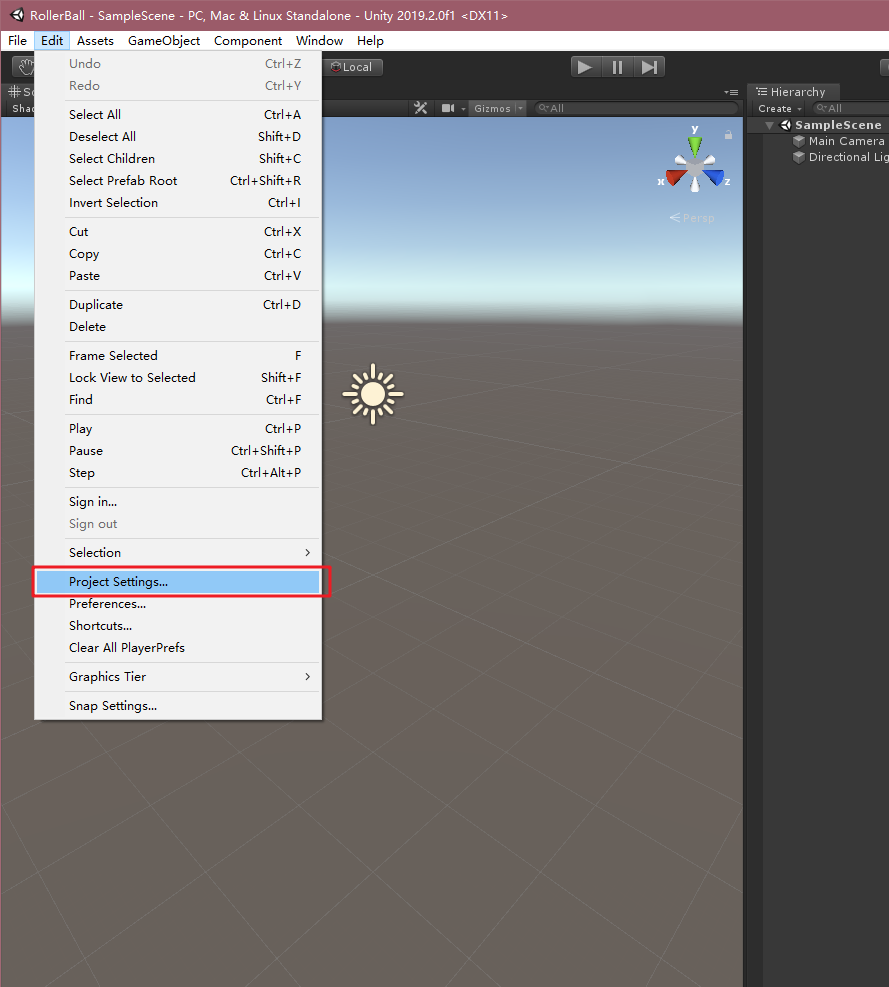
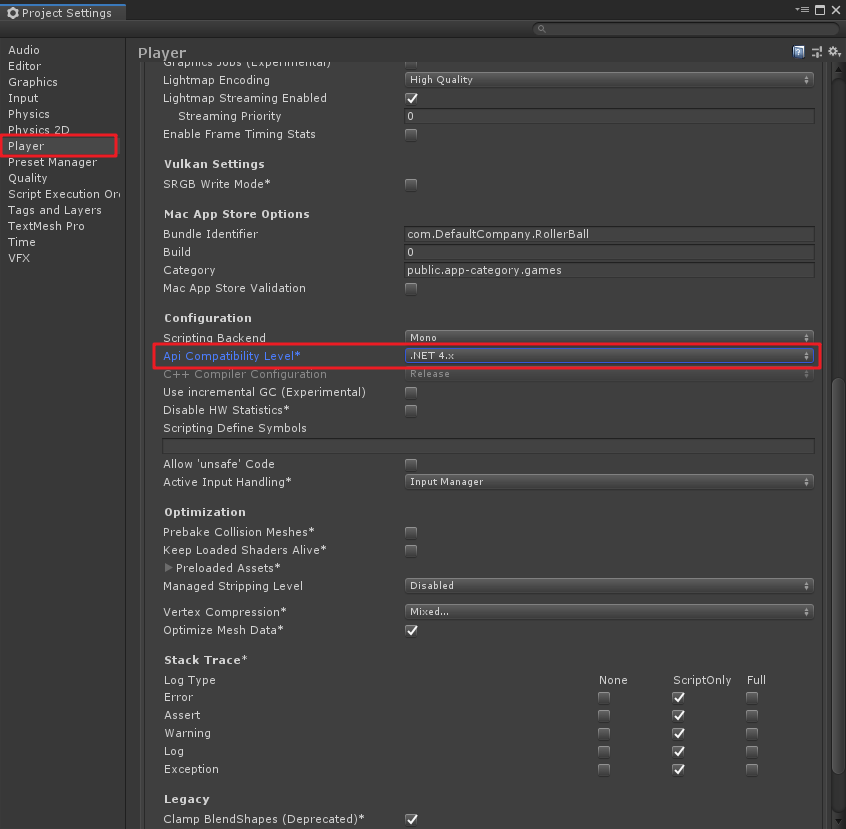
在Unity菜单“Edit”->“Project Settings”,在弹出的窗口中,找到“Player”,将“Api Compathbility Level”改为“.NET 4.x”,如下图;
-
在上一节中,我们已经将ml-agents代码库克隆到了本地,如果没有克隆,请参考上一篇“Unity ML-Agents v0.15.0(一)环境部署与试运行”中的五、1,这里我们默认大家都是已经克隆了库,则在Unity中需要将ML-Agents插件导入Unity中。我这里的版本是Unity2019.2,方法如下:
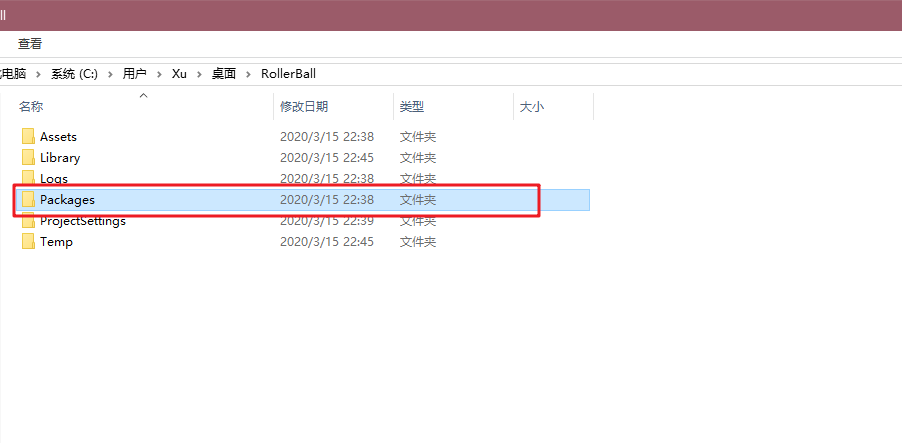
- 在项目根目录中找到Packages文件夹;
-
文件夹中有一个“manifest.json”的文件,编辑它,这个就是工程中的Packages包集合,在最后加入"com.unity.ml-agents" : "file:D:/Unity Projects/ml-agents/com.unity.ml-agents",这里file:后是你自己克隆的ml-agents源码路径,别照抄我的哦,除非你也是这个路径- -,如下图;
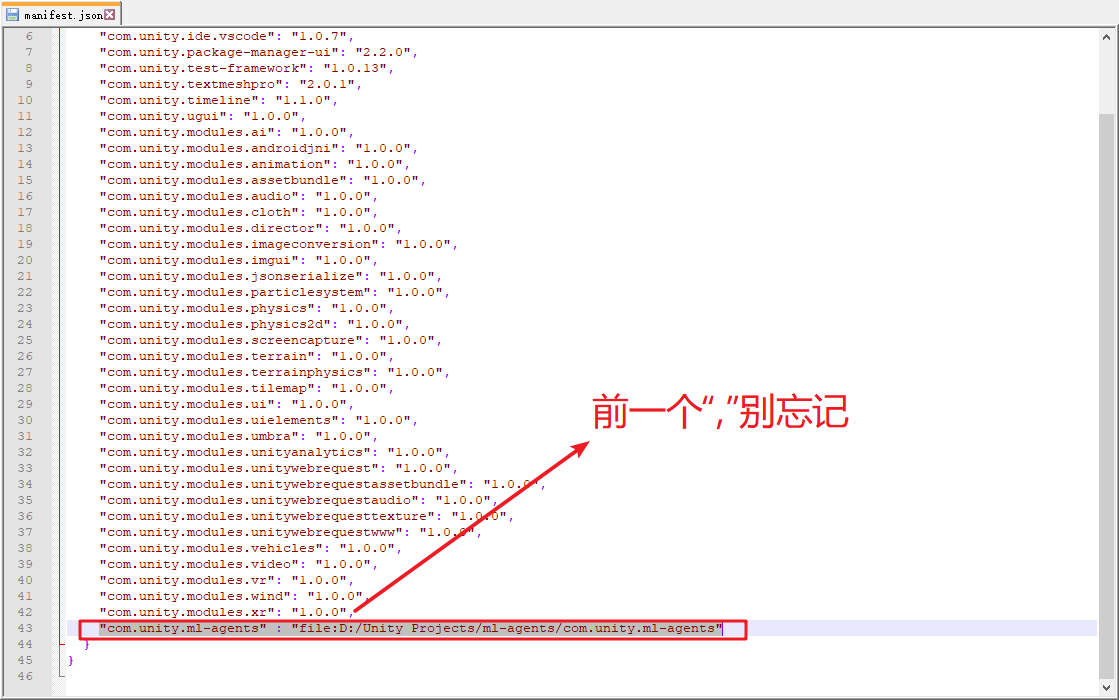
修改后保存,在切到Unity中,如果路径正确,则会出现导入package包的画面,在工程的Packages文件夹下也会成功出现“ML Agents”文件夹,如下图:
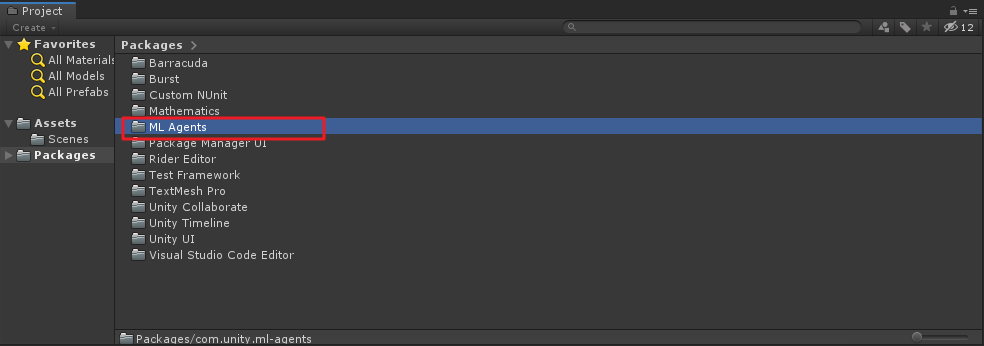
-
创建环境
下面,我们创建一个简单的ML-Agent环境。该环境的“physical”组件包括一个Plane(充当agent移动的地板)、一个Cube(充当agent寻找的目标)和一个Sphere(表示agent本身)。
-
创建地板
-
在 Hierarchy 窗口中右键单击,选择 3D Object > Plane。
-
将游戏对象命名为“Floor”。
-
选择 Plane 以便在 Inspector 窗口中查看其属性。
-
将 Transform 设置为 Position = (0,0,0)、Rotation = (0,0,0)、Scale = (1,1,1)。
-
修改Plane材质,变的好看点。
-
以上过程我都是复制的,其实就是创建一个Plane,然后换个好看的材质就行,随意定义一个都OK。
-
创建目标立方体
-
在 Hierarchy 窗口中右键单击,选择 3D Object > Cube。
-
将游戏对象命名为“Target”
-
选择 Target 以便在 Inspector 窗口中查看其属性。
-
将 Transform 设置为 Position = (3,0.5,3)、Rotation = (0,0,0)、Scale = (1,1,1)。
-
修改Cube材质。
-
-
添加Agent球体
- 在 Hierarchy 窗口中右键单击,选择 3D Object > Sphere。
- 将游戏对象命名为“RollerAgent”
- 选择 Target 以便在 Inspector 窗口中查看其属性。
- 将 Transform 设置为 Position = (0,0.5,0)、Rotation = (0,0,0)、Scale = (1,1,1)。
- 在 Sphere 的 Mesh Renderer 上,展开 Materials 属性并将默认材质更改为 checker 1。
- 单击 Add Component。
- 向 Sphere 添加 Physics/Rigidbody 组件。(添加 Rigidbody)
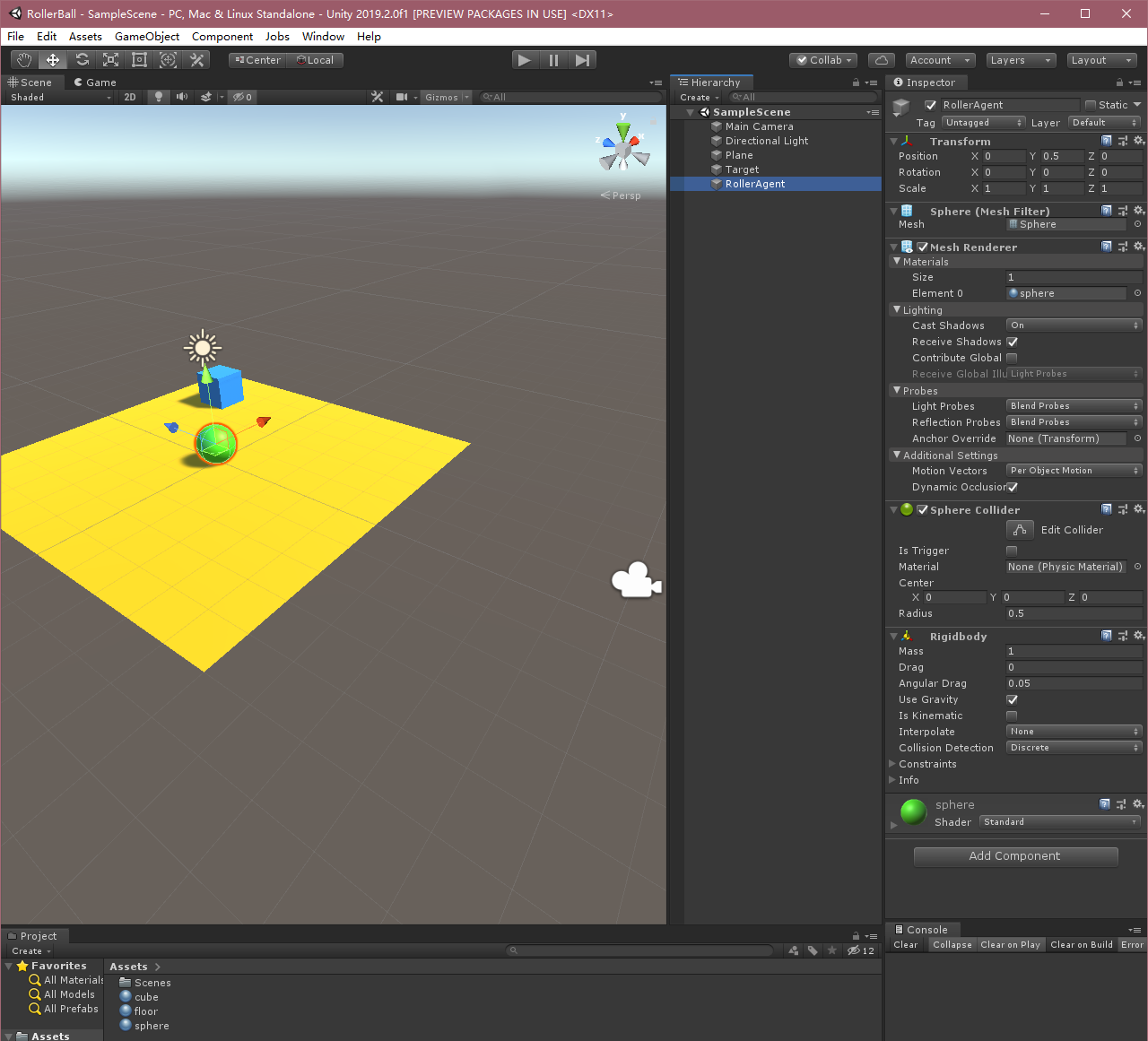
-
OK,以上过程就将Unity中的三维环境创建好了,下面我们来实现Agent。
四、实现Agent
在官方中文文档中还有“实现Academy”及“添加Brain”,最新版里已经不需要了!直接设置Agent就行。
要创建Agent:
- 选择 RollerAgent 游戏对象以便在 Inspector 窗口中查看该对象。
- 单击 Add Component。
- 在组件列表中单击 New Script(位于底部)。
- 将该脚本命名为“RollerAgent”。
- 单击 Create and Add。
然后,编辑新的RollerAgent脚本:
- 打开
RollerAgent脚本; - 令
RollerAgent继承Agent类,同时引用using MLAgents和using MLAgents.Sensors命名空间; - 删除
Update()方法,先保留Start()方法之后要用。
到目前为止,以上的步骤都是为了将ML-Agents添加到任何Unity项目中而需要的基本步骤。接下来,我们将添加逻辑,使我们的agent能够利用reinforcement learning(强化学习)技术学习找到立方体。
初始化和重置Agent
当agent(球体)到达目标位置(方块)后,会将自己标记为完成状态,而agent的重置函数(Reset)会将方块再重新移动到新的位置。另外,如果agent从平台上掉落,也会触发重置函数,使得agent初始化,目标位置也将随机刷新。
为了重置agent的速度(以及之后给它施加力移动),我们需要引用到球体的Rigidbody组件。这个组件的引用就可以写到Start()方法中,以以上的逻辑,我们的RollerAgent脚本如下:
using MLAgents;
using MLAgents.Sensors;
using UnityEngine;
public class RollerAgent : Agent
{
public Transform Target;//方块
public float speed = 10;//小球移动速度
private Rigidbody rBody;//球刚体
private void Start()
{
rBody = GetComponent<Rigidbody>();
}
/// <summary>
/// Agent重置
/// </summary>
public override void AgentReset()
{
if (this.transform.position.y < 0)
{//如果小球掉落,小球初始化
rBody.velocity = Vector3.zero;
rBody.angularVelocity = Vector3.zero;
transform.position = new Vector3(0, 0.5f, 0);
}
//方块位置随机
Target.position = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
}
接下来,我们来实现Agent.CollectObservations(VectorSensor sensor)方法。
注意,这里和老版本方法不同,之前的函数中并没有VectorSensor sensor参数,不过用法差不多。
观测环境(Observing the Environment)
Agent将我们收集的信息发送给Brain,由Brain使用这些信息来做决策。当你训练Agent(或使用已经训练好的模型)时,数据将作为特征向量输入到神经网络中。为了让Agent成功学习某个任务,我们需要提供正确的信息。一个好的经验法则则是考虑你在计算问题的分析解决方案时需要用到什么。
这里比较重要,就是说你在训练的时候,需要考虑到的变量是哪些,我们来看看这个例子中我们需要agent收集的信息有哪些:
-
目标的位置
sensor.AddObservation(Target.position); -
agent的位置
sensor.AddObservation(transform.position); -
agent的速度,这有助于agent去学习控制自己的速度,而不会使其越过目标和从平台上滚下来
sensor.AddObservation(rBody.velocity.x);sensor.AddObservation(rBody.velocity.z);
这里一共有8个观测值(一个position算x,y,z三个值),之后需要在Behavior Parameters组件的属性里进行设置,如下图:
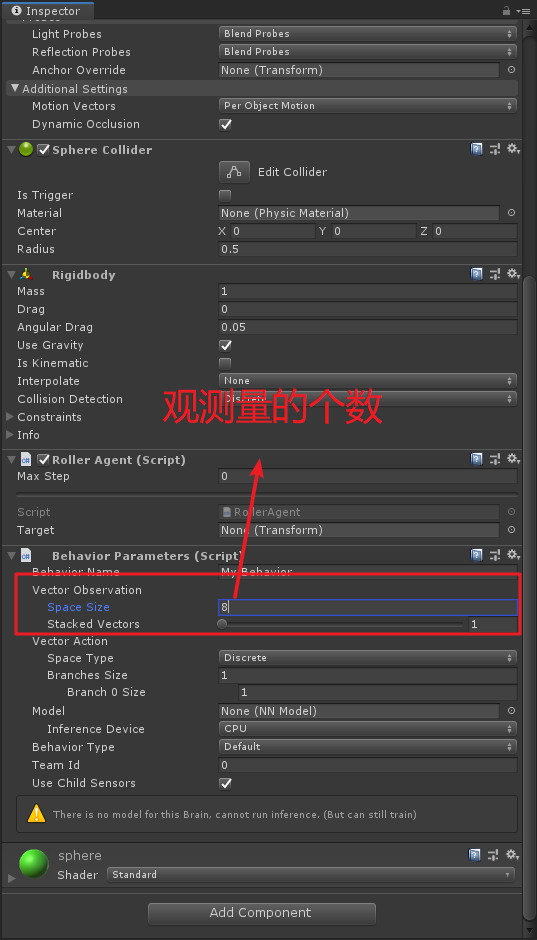
在中文文档里,对这些值进行了归一化处理,最新英文文档中并没有进行归一化处理,直接加上就行。然后这里的重载函数如下:
/// <summary>
/// Agent收集的观察值
/// </summary>
/// <param name="sensor"></param>
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(Target.position);//目标的位置
sensor.AddObservation(transform.position);//小球的位置
sensor.AddObservation(rBody.velocity.x);//小球x方向的速度
sensor.AddObservation(rBody.velocity.z);//小球z方向的速度
}
Agent的最后一部分是Aegnt.AgentAction()函数,这个方法主要是用来接收Brain的决策命令以及根据不同情况来进行Reward(奖励)。
动作(Actions)
Brain的决策以动作数组的形式传递给AgentAction()函数。此数组中的元素主要由agent的Brain的Vector Action、Space Type和Space Size来决定的。这里分别代表 了向量运动空间、向量运动空间类型以及向量运动空间数,ML-Agents将动作分为两种:Continusous向量运动空间是一个可以连续变化的数字向量,例如一个元素可能表示施加到agent某个Rigidbody上的里或扭矩;Discrete向量运动空间则将动作定义为一个表,提供给agent的具体动作是这个表的索引。
我们在这里利用的是Continusous向量运动空间,即将Space Type设置为Continuous,并将Space Size设置为2。这就表示了Brain生成的决策利用第一个元素action[0]来确定施加沿x轴的力,通过action[1]来确定施加沿z轴的力(如果agent是三维移动,则将Space Size设置为3)。注意,这个里Brain并不知道action[]数组中每个值的具体含义,在训练的过程中只是根据观测输入来调整动作,然后看看会得到什么样的奖励。具体设置如下图,同样是在Behavior Parameters组价中进行设置:
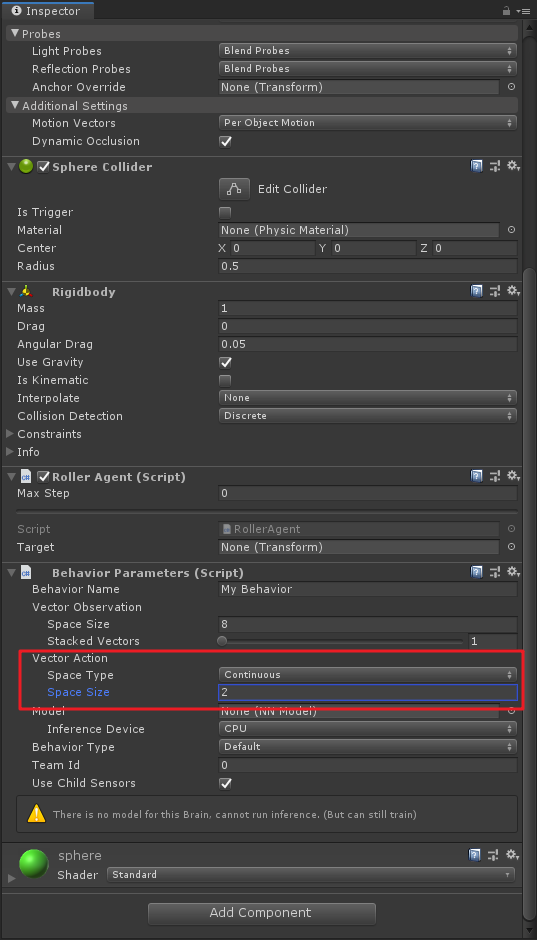
引申一下,这里也可以使用Discrete类型来训练,不过相应的Space Size就要变成4了,因为有4个方向需要控制。
OK,上述的动作代码如下:
//Space Type=Continuous Space Size=2
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];//x轴方向力
controlSignal.z = vectorAction[1];//z轴方向力
//当然上面这两句可以互换,因为Brain并不知道action[]数组中数值具体含义
rBody.AddForce(controlSignal * speed);
奖励(Rewards)
Reinforcement Learning(强化学习)需要奖励。同样奖励(惩罚)也在AgentAction()函数中实现,与上面动作实现的重写函数在一起。学习算法使用在模拟和学习过程的每个步骤中分配给agent的奖励来确定是否为agent提供了最佳的动作。当agent完成任务时,对它进行奖励。在这个示例中,如果Agent(小球)到达了目标位置(方块),则给它奖励1分。
RollerAgent会计算到达目标所需的距离,当到达目标时,我们可以通过Agent.SetReward()方法来讲agent标记为完成,并给它奖励1分,同时使用Done()方法来重置环境。
//计算自身与目标的距离
float distanceToTarget = Vector3.Distance(transform.position,Target.position);
//不同情况进行奖励
if (distanceToTarget < 1.42f)
{//到达目标附近
SetReward(1);
Done();
}
最后,如果小球掉落平台,则让agent重置。这里没有设置惩罚,有兴趣的童靴可以自己试试设置惩罚。
if (transform.position.y < 0)
{//小球掉落
//SetReward(-1); 惩罚先不设置
Done();
}
AgentAction()方法
OK,由以上的动作和奖励构成了AgentAction()方法,主要理解里面每一步的意义是为何,最后AgentAction()方法如下:
public override void AgentAction(float[] vectorAction)
{
//Space Type=Continuous Space Size=2
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];//x轴方向力
controlSignal.z = vectorAction[1];//z轴方向力
//当然上面这两句可以互换,因为Brain并不知道action[]数组中数值具体含义
rBody.AddForce(controlSignal * speed);
//计算自身与目标的距离
float distanceToTarget = Vector3.Distance(transform.position, Target.position);
//不同情况进行奖励
if (distanceToTarget < 1.42f)
{//到达目标附近
SetReward(1);
Done();
}
if (transform.position.y < 0)
{//小球掉落
Done();
}
}
最终Editor设置
到这一步,所有的游戏对象和ML-Agent组件都已准备就绪,然后我们需要在场景的小球上加一些脚本,修改一些属性。
-
在场景中选择RollerAgent小球,先添加
Behavior Parameters脚本,并设置其中的Space Size为8,Space Type为Continuous,Space Size为2。这步要是之前几步里已经搞定了,就不用管了。不过这里面有个Behavior Name,这个属性应该就是区分Brain的名称,新版中多个Agent拥有相同Brain的话,应该是在这里进行区分,我个人是这么觉得的,要是有错的话,请指正;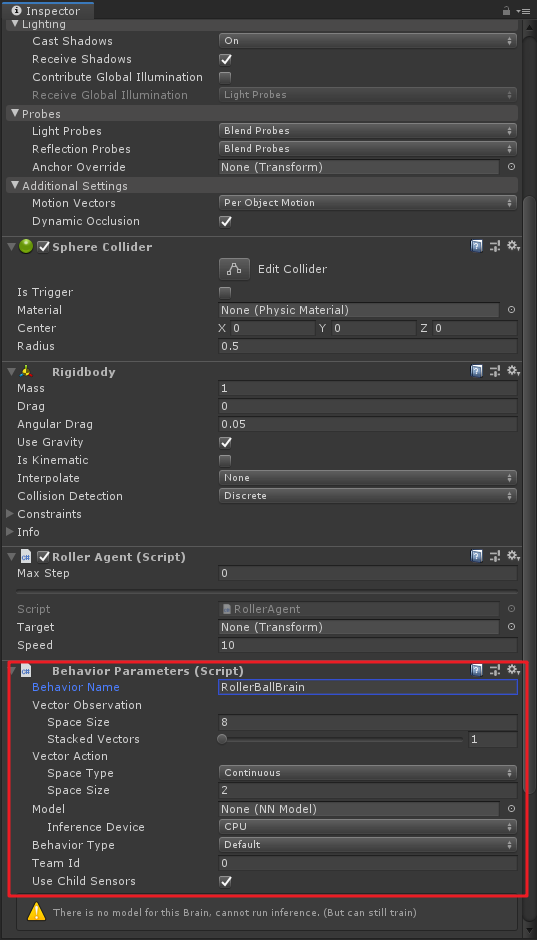
-
这步一定要记得,老版里没有,需要加
Decision Requester组件,并将Decision Period改为10!这里英文文档也写得不起眼,要是不加这个脚本,你的小球是动不起来的。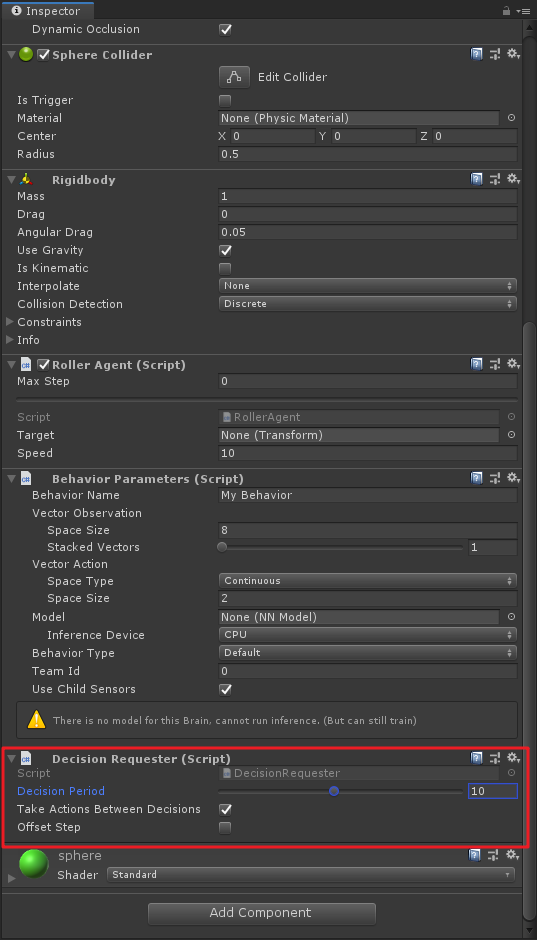
手动测试环境
在开始长时间训练之前,手动测试你的测试环境是一个明智的做法。为了手动测试,我们需要在Roller Agent脚本中添加Heuristic()方法,以此来代替Brain决策,代码如下:
/// <summary>
/// 手动测试
/// </summary>
/// <returns></returns>
public override float[] Heuristic()
{
var action = new float[2];
action[0] = Input.GetAxis("Horizontal");
action[1] = Input.GetAxis("Vertical");
return action;
}
其实这里就是通过键盘来对动作空间action[]数组进行赋值来使得agent动作。
然后还需要在Behavior Parameters组件中将Behavior Type改为Heuristic Only,如下:

这个时候我们可以运行一下,(突然发现Roller中的Targer忘记拖了,将方块目标拖进来),然后就可以使用WSAD或上下左右来控制小球了,到方块附近,方块会自动重新置位,如果小球掉落,也会重新置位。
OK,我们Behavior Type改回Default,准备开始训练了~
五、进行训练
打开Anaconda3,找到我们之前建好的训练环境,启动“Terminal”。

cd到ml-agent的根目录,例如我的路径:
cd /d D:\Unity Projects\ml-agents
这里插一下,我们修改一下ml-agents中的Config文件,找到ml-agents中config文件夹,并打开trainer_config.yaml配置文件,在最后加一句
RollerBallBrain:
batch_size: 10
buffer_size: 100
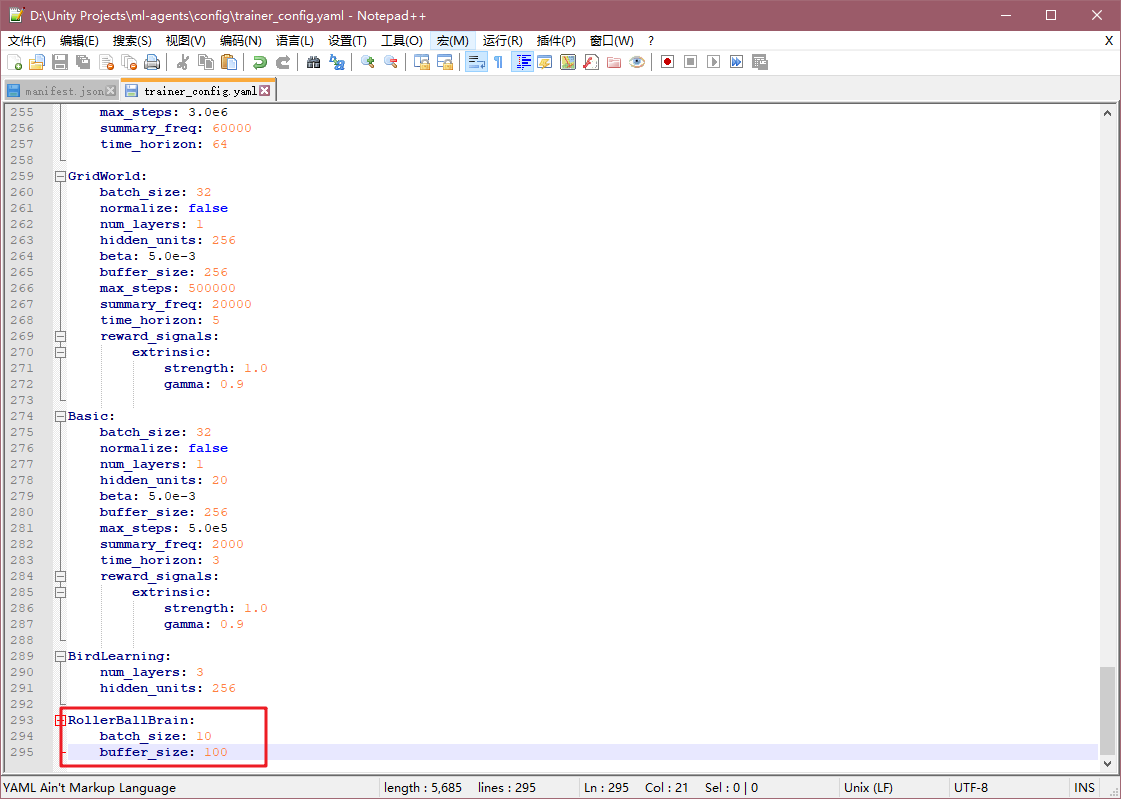
这里可以看到RollerBallBrain其实就是我刚才在Behavior Parameters组件中设置的Behavior Name。这里修改这两个参数会覆盖配置文件最前的默认项default,这两个超参数值修改小可以使得训练速度加快,如果用原来的参数(batch_size: 1024,buffer_size: 10240),则需要训练大约300000步,但是修改后只需要低于20000步。这里应该是根据具体项目具体设置的。
我们配置完之后,回到命令行,输入:
mlagents-learn config/trainer_config.yaml --run-id=RollerBall-1 --train
运行Unity中的程序。
如果Unity与Anaconda训练环境成功通讯,则会在命令行中发现你的训练配置:
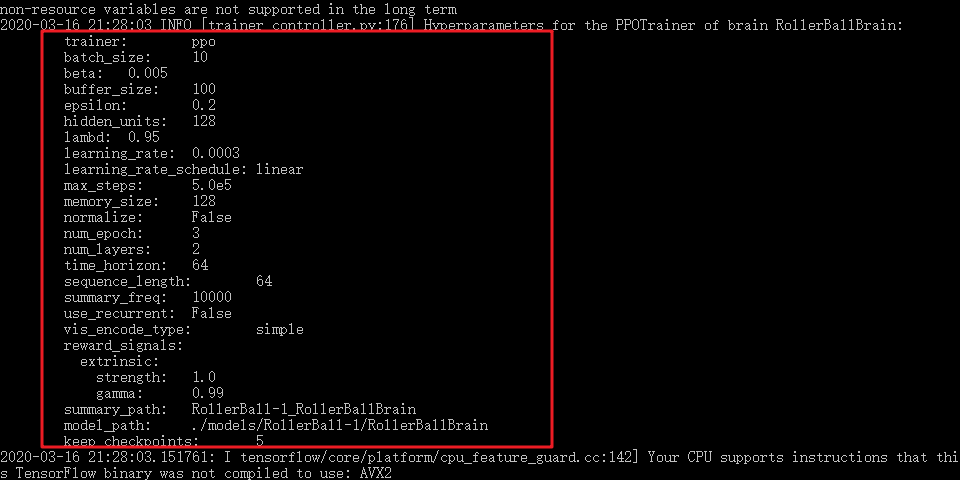
同时,可以看到Unity中小球开始自己快速运动,方块也会根据不同状态来随机生成。
过一段时间,命令行中会显示相应的执行步数,经过的时间,平均奖励等信息。
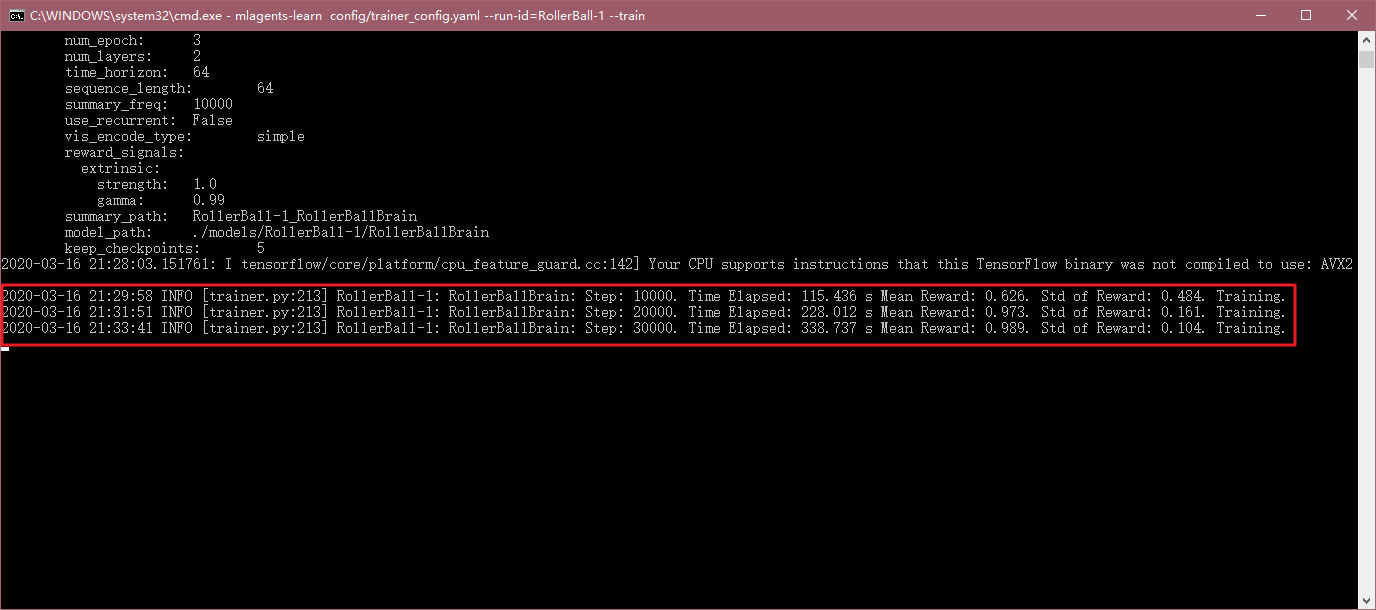
随着训练的进行,会发现小球很难掉下平台,且一直跟随方块的位置:
最后训练时间太长了,可以通过配置文件中的max_steps来修改最大训练步骤,所以我这里直接Ctrl+C了,这样也会将训练模型存下来。
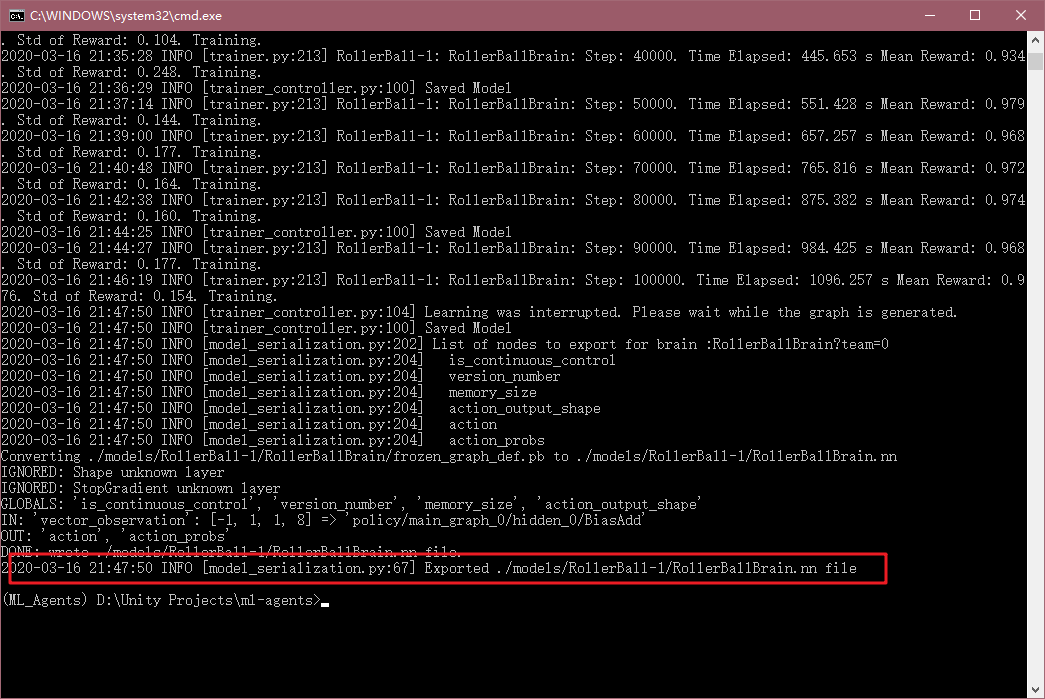
找到这个RolerBallBrain.nn文件,在ml-agent的models文件夹下,将这个.nn文件考入Unity中,如下:
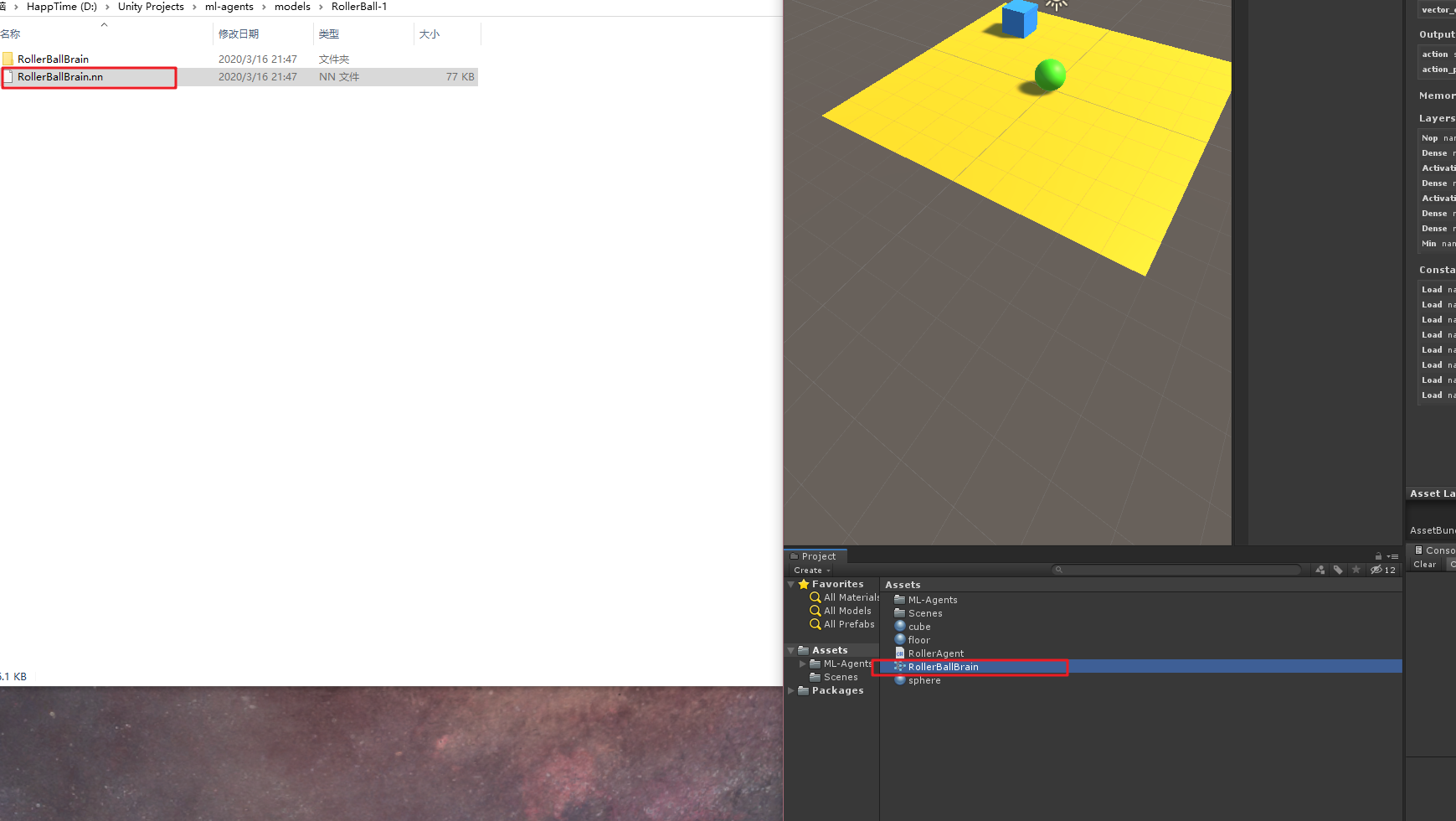
然后选中场景中的小球,将Behavior Parameters组件中Model属性中,选择刚才训练好的模型,并将Behavior Type选为Inference Only,如下:
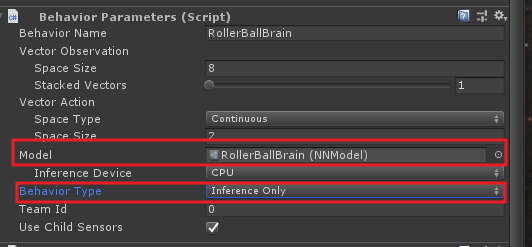
然后点击运行,就可以看到小球利用我们训练好的模型开始找方块了。
TensorBoard统计信息
我们在命令行中,还可以找到刚才训练的图表信息,在命令行中输入:
tensorboard --logdir=summaries

然后将地址在浏览器中打开,一般都是http://localhost:6006/
则可以看到随着训练步数各个数值变化值。
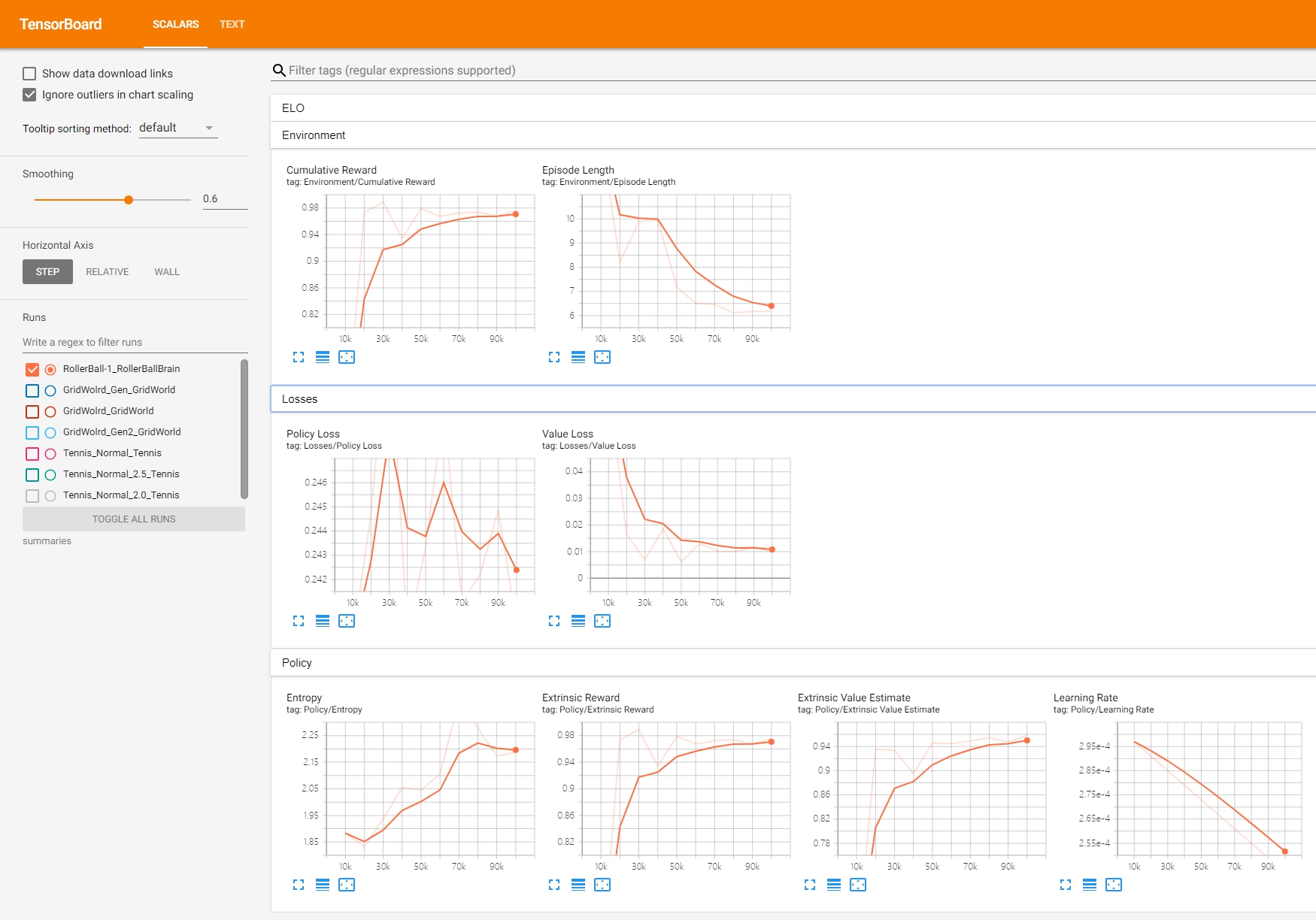
这些值的含义,抄一些官方中文文档:
-
Lesson - 只有在进行课程训练]时才有意义。
-
Cumulative Reward - 所有 agent 的平均累积场景奖励。 在成功训练期间应该增大。
-
Entropy - 模型决策的随机程度。在成功训练过程中 应该缓慢减小。如果减小得太快,应增大
beta超参数。 -
Episode Length - 所有 agent 在环境中每个场景的 平均长度。
-
Learning Rate - 训练算法搜索最优 policy 时需要多大的 步骤。随着时间推移应该减小。
-
Policy Loss - policy 功能更新的平均损失。与 policy (决定动作的过程)的变化程度相关。此项的幅度 在成功训练期间应该减小。
-
Value Estimate - agent 访问的所有状态的平均价值估算。 在成功训练期间应该增大。
-
Value Loss - 价值功能更新的平均损失。与模型 对每个状态的价值进行预测的能力相关。此项 在成功训练期间应该减小。
OK,以上就是官方训练的一个小例子全过程了。
记录这个还挺累,不过欢迎大家一起留言讨论~
引用:
https://github.com/Unity-Technologies/ml-agents/tree/master/docs
写文不易~因此做以下申明:
1.博客中标注原创的文章,版权归原作者 煦阳(本博博主) 所有;
2.未经原作者允许不得转载本文内容,否则将视为侵权;
3.转载或者引用本文内容请注明来源及原作者;
4.对于不遵守此声明或者其他违法使用本文内容者,本人依法保留追究权等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号