day4迭代器&生成器&正则表达式
一、迭代器
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不能后退,不过这也没什么,因为人们很少在迭代途中后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如N个G的文件。
特定:
(1).访问者不需要关心迭代器内部的文件,仅需通过next()方法不断去取下一个内容;
(2).不能随机访问集合中的某个值,只能从头到尾依次访问;
(3).访问到一半时不能往回退;
(4).便于循环比较大的数据集合,节省内存生成一个迭代器。
iter()用来声明迭代器,示例如下:
names = iter(["eric","aoi","alex"])
print(names)
print(names.__next__())
print(names.__next__())
print(names.__next__())
声明一个迭代器,在遍历文件的时候,for line in f:就是使用迭代的方式实现的。
>>> names = iter(["eric","alex","aoi"])
>>> names.__next__()
'eric'
>>> names.__next__()
'alex'
>>> names.__next__()
'aoi'
>>> names.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
迭代器只能一个一个读取,不能跳读,不能回退,读取完了之后会结束迭代,报错Stoplteration。
我们知道,我们打开读取文件的时候,可以使用f.read(),f.readline(),f.readlines()等方式,但是我们在读取的时候,Python是将文件加载到内存然后进行读取的,速度会很慢,我们可以采用下面的方式进行读取:
with open(filename,"r") as f:
for line in f:
print(line)
上面代码就是按照逐行读取的方式进行读取的。这样是一行一行读(next())读取一行加载一行,实现的方式就是迭代器,这样读取文件的速度会很快,因此我们在读取大文件的时候可以采用for line in f:这样的方式进行读取。
二、生成器generator
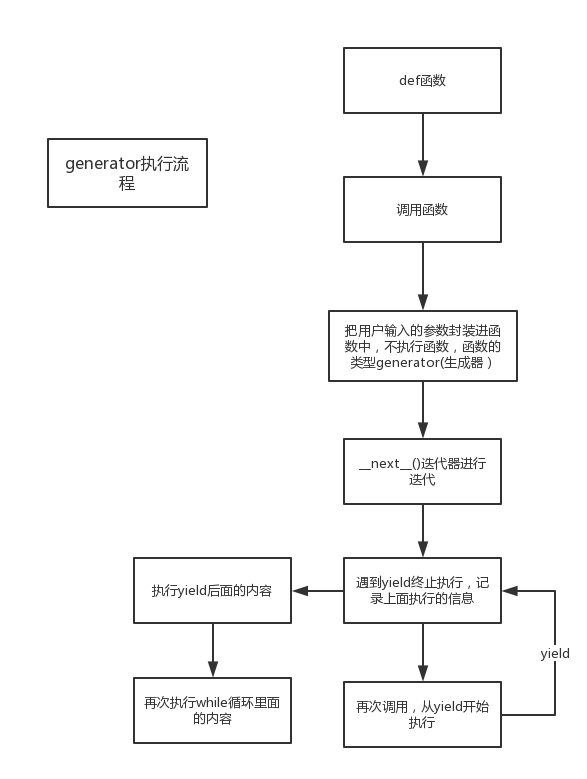
定义:一个函数调用时返回一个迭代器,那这个函数就叫做生成器(generator),如果函数中包含yield语法,那这个函数就会变成生成器。
def cash_money(amount):
while amount > 0:
amount -= 100
yield 100 #yield 100中100是返回值,执行的时候返回值
print("又来取钱了")
atm = cash_money(500) #给函数生成器传递参数
上面代码,我们执行,但是没有返回值,为什么呢?我们执行调用了函数,按说应该打印又来取钱了,但是然并卵没有打印,下面我们来看看atm的类型。
print(type(atm))
运行结果如下:
<class 'generator'>
变量atm类型是一个generator,是一个生成器。函数是一个生成器函数,返回的是一个迭代器,迭代器要使用__next__()方法进行调用:
def cash_money(amount):
while amount > 0:
amount -= 100
yield 100
print("又来取钱了")
atm = cash_money(500)
print(type(atm))
print(atm.__next__())
print(atm.__next__())
print("叫个大保健")
print(atm.__next__())
运行结果如下:
<class 'generator'>
100
又来取钱了
100
叫个大保健
又来取钱了
100
假如我们编写一个程序去取钱,比如5万,银行要审核大额取款,审核时间三十分钟,如果通常的串行程序,就要等银行的反馈结果,程序才能继续执行,yield就是避免这种情况,让程序继续等待,程序本身执行下面程序。串行是同步,生成器就是异步的情况。
生成器可以从断点处继续执行代码。生成器可以保存函数的中断状态。
作用:
这个yield的主要效果呢,就是可以使函数中断,并保存中断状态,中断后,代码可以继续往下执行,过一段时间还可以再重新调用这个函数,从上次yield的下一句执行。
另外,还可以通过yield实现在单线程的情况下并发运算的效果。
下面来看一个实例:
import time
#导入时间函数,让程序执行等待
def consumer(name):
#消费者模型
print("%s 准备吃包子啦!"%name)
while True:
baozi = yield
print("包子[%s]来了,被[%s]吃了!" %(baozi,name))
def producer(name):
#来了两个消费者买包子
c = consumer("A")
c2 = consumer("B")
c.__next__()
c2.__next__()
print("老子开始准备做包子啦!")
for i in range(10):
time.sleep(1)
print("做了2个包子!")
c.send(i)
c2.send(i)
producer("alex")
导入时间模块,定义生产者多久可以生成包子,定义两个模块,一个是生成者模块,一个是消费这模块,消费者模块功能是告诉生产者有消费者来买包子了,并且接收生产者生产的包子;生产者的模型是接收两个消费者来的消息,并且开始生产包子,并且生产者生成包子是需要时间的,生产完包子之后把使用send把包子发给消费者。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号