
Java Programming 【Chapter 4_QA】
1、这里提到的默认的构造方法长什么样呢?

默认的构造方法是无参数的,并且会调用基类的无参数构造方法。
基于提供的代码,Base 类的默认构造方法如下:
public class Base { private String member; public Base() { super(); // 默认调用 Object 类的无参数构造方法 } public Base(String member) { this.member = member; } }
由于 Base 类已经定义了一个带参数的构造方法(public Base(String member)),默认的无参数构造方法不会被自动生成,除非显式添加。
2、为什么第一次输出是0,第二次输出是123?理解下这个输出逻辑。
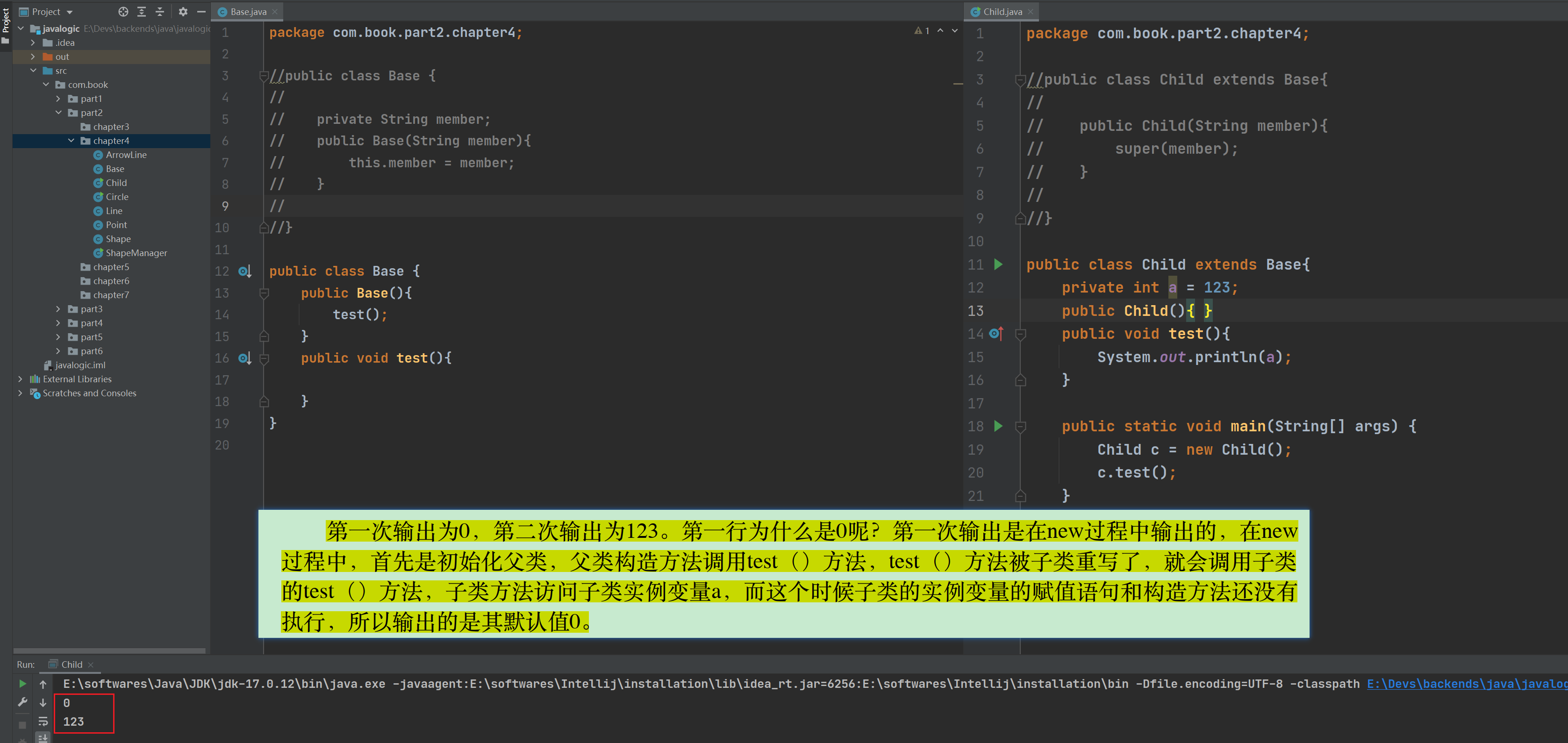
总结:
像这样,在父类构造方法中调用可被子类重写的方法,是一种不好的实践,容易弓引起混淆,应该只调用private的方法
3、如何深入理解以下输出结果 的顺序?
4.3.1 示例


以下是对代码的详细分析,基于上图的 Base、Child 和 Test 三个类,以及程序的输出结果。
代码概述
- Base 类:
- 包含一个静态变量 s 和一个实例变量 a。
- 有一个静态代码块、一个实例代码块和一个构造方法。
- 定义了 step() 方法(会被子类重写)和 action() 方法(调用 step())。
- Child 类:
- 继承自 Base 类,同样定义了自己的静态变量 s 和实例变量 a。
- 包含一个静态代码块、一个实例代码块和一个构造方法。
- 重写了 step() 方法。
- Test 类:
- 包含 main 方法,创建 Child 对象,调用 action() 方法,并通过 Base 类型的引用调用方法和访问变量。
输出分析
以下是逐行解释输出结果的顺序和原因:
输出部分 1:---- new Child()
---- new Child() 基类静态代码块,s: 0 子类静态代码块, s: 0 基类实例代码块,a: 0 基类构造方法, a: 1 子类实例代码块, a: 0 子类构造方法, a: 10
分析:
- 触发 new Child():
- 当 Child c = new Child() 执行时,JVM 需要创建 Child 类的实例。由于 Child 继承自 Base,JVM 会先确保 Base 和 Child 类的静态初始化完成,然后执行实例初始化。
- 基类静态代码块,s: 0:
- 在创建 Child 对象之前,JVM 首先加载 Base 类(因为 Child 继承自 Base)。
- 加载 Base 类时,执行其静态代码块。Base.s 是静态变量,初始化为默认值 0(整型默认值)。
- 静态代码块打印 "基类静态代码块,s: 0",然后将 Base.s 赋值为 1。
- 输出:基类静态代码块,s: 0。
- 子类静态代码块, s: 0:
- 加载 Child 类时,执行其静态代码块。Child.s 是 Child 类的静态变量,独立于 Base.s,初始化为默认值 0。
- 静态代码块打印 "子类静态代码块, s: 0",然后将 Child.s 赋值为 10。
- 输出:子类静态代码块, s: 0。
- 注意:静态代码块只在类加载时执行一次,且按继承链从父类到子类顺序执行。
- 基类实例代码块,a: 0:
- 静态初始化完成后,JVM 开始创建 Child 对象。因为 Child 继承自 Base,先执行 Base 的实例初始化。
- Base 的实例代码块先于构造方法执行。Base.a 是实例变量,初始化为默认值 0。
- 实例代码块打印 "基类实例代码块,a: 0",然后将 Base.a 赋值为 1。
- 输出:基类实例代码块,a: 0。
- 基类构造方法, a: 1:
- 紧接着,Base 的构造方法执行。此时 Base.a 已被实例代码块赋值为 1。
- 构造方法打印 "基类构造方法, a: 1",然后将 Base.a 赋值为 2。
- 输出:基类构造方法, a: 1。
- 子类实例代码块, a: 0:
- Base 的实例初始化完成后,JVM 执行 Child 的实例初始化。
- Child 的实例代码块先执行。Child.a 是 Child 类的实例变量,独立于 Base.a,初始化为默认值 0。
- 实例代码块打印 "子类实例代码块, a: 0",然后将 Child.a 赋值为 10。
- 输出:子类实例代码块, a: 0。
- 子类构造方法, a: 10:
- 最后,Child 的构造方法执行。此时 Child.a 已被实例代码块赋值为 10。
- 构造方法打印 "子类构造方法, a: 10",然后将 Child.a 赋值为 20。
- 输出:子类构造方法, a: 10。
小结:
- 静态代码块按类加载顺序执行(Base → Child),只执行一次。
- 实例初始化按继承链顺序执行:Base 的实例代码块和构造方法先执行,然后是 Child 的实例代码块和构造方法。
- 每个类的变量(s 和 a)在初始化时都有默认值(0),然后被代码块或构造方法修改。
输出部分 2:---- c.action()
---- c.action() start child s: 10, a: 20 end
分析:
- 调用 c.action():
- c 是 Child 类型的引用,指向 Child 对象。调用 c.action() 会执行 Base 类中定义的 action() 方法(因为 Child 没有重写 action())。
- action() 方法打印 "start",调用 step(),然后打印 "end"。
- start:
- action() 方法首先打印 "start"。
- 输出:start。
- child s: 10, a: 20:
- action() 调用 step()。由于 step() 是实例方法,且 Child 重写了 step(),JVM 动态绑定调用 Child 的 step() 方法(多态)。
- 在 Child.step() 中:
- s 引用 Child.s(因为 s 是静态变量,Child 类有自己的 s),值为 10(由 Child 的静态代码块设置)。
- a 引用 Child.a(实例变量),值为 20(由 Child 的构造方法设置)。
- 因此,打印 "child s: 10, a: 20"。
- 输出:child s: 10, a: 20。
- end:
- action() 方法继续执行,打印 "end"。
- 输出:end。
小结:
- c.action() 调用的是 Base 的 action() 方法,但由于 step() 被 Child 重写,实际执行的是 Child 的 step(),体现了多态。
输出部分 3:---- b.action()
---- b.action() start child s: 10, a: 20 end
分析:
- 创建 Base b = c:
- b 是 Base 类型的引用,但指向同一个 Child 对象(c)。这不会触发新的对象创建或初始化。
- 调用 b.action():
- 调用 b.action() 执行 Base 的 action() 方法(与 c.action() 相同)。
- action() 方法打印 "start",调用 step(),然后打印 "end".
- start:
- 打印 "start"。
- 输出:start。
- child s: 10, a: 20:
- step() 是虚方法,JVM 根据对象的实际类型(Child)调用 Child 的 step() 方法。
- 结果与 c.action() 相同,打印 "child s: 10, a: 20"。
- 输出:child s: 10, a: 20。
- end:
- 打印 "end"。
- 输出:end。
小结:
- 即使 b 是 Base 类型,step() 方法的调用仍然基于对象的实际类型(Child),因此输出与 c.action() 一致。
输出部分 4:---- b.s: 1
---- b.s: 1
分析:
- b 是 Base 类型的引用,访问 b.s 时,JVM 解析到 Base 类的静态变量 s。
- Base.s 在 Base 的静态代码块中被赋值为 1。
- 因此,打印 "---- b.s: 1"。
- 输出:---- b.s: 1。
注意:
- 静态变量是类级别的,Base.s 和 Child.s 是独立的。b 的类型决定了访问 Base.s。
输出部分 5:---- c.s: 10
---- c.s: 10
分析:
- c 是 Child 类型的引用,访问 c.s 时,JVM 解析到 Child 类的静态变量 s。
- Child.s 在 Child 的静态代码块中被赋值为 10。
- 因此,打印 "---- c.s: 10"。
- 输出:---- c.s: 10。
注意:
- Child.s 和 Base.s 是不同的静态变量,值互不影响。
输出部分 6:Process finished with exit code 0
- 表示程序正常退出,没有异常。
总结
输出的顺序由以下规则决定:
- 类加载与静态初始化:
- 类加载时,静态代码块按继承链顺序执行(Base → Child)。
- 静态变量初始化为默认值(0),然后由静态代码块修改。
- 对象创建与实例初始化:
- 实例初始化按继承链顺序执行:Base 的实例代码块和构造方法先于 Child 的实例代码块和构造方法。
- 实例变量初始化为默认值(0),然后由实例代码块和构造方法修改。
- 方法调用与多态:
- 实例方法的调用基于对象的实际类型(Child),因此 step() 调用 Child 的版本。
- 静态变量的访问基于引用类型(Base 或 Child),因此 b.s 和 c.s 访问不同的变量。
- 静态变量与实例变量的独立性:
- Base.s 和 Child.s 是独立的静态变量。
- Base.a 和 Child.a 是独立的实例变量,分别存储在对象的 Base 和 Child 部分。
4、在我如图所示的这个代码中,加上@Override和不加@Override,最后结果都是一样的,而且Intellij编译器也没有报错。那么这个@Override到底有何作用,加不加影响大吗?
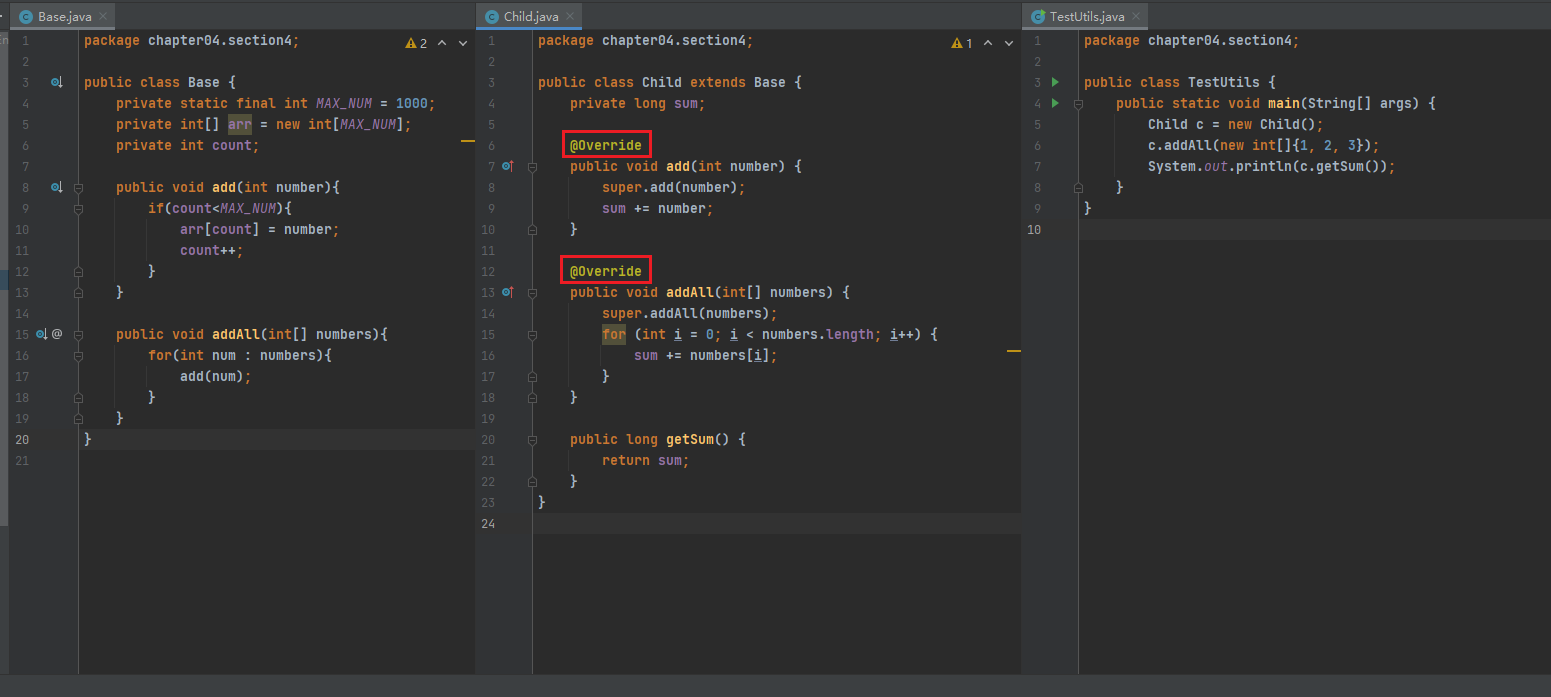
@Override 注解被用在 Child 类的 add(int number) 和 addAll(int[] numbers) 方法上,用于标记这些方法是重写(override)了父类 Base 中的方法。
然而,你观察到加上 @Override 和不加 @Override 的运行结果是一致的,IntelliJ IDEA 编译器也没有报错。这引发了关于 @Override 作用和必要性的疑问。以下是详细解释:
@Override 的作用
- 标记方法重写:
- @Override 是 Java 中的一个注解,告诉编译器该方法是意图重写父类的某个方法。如果子类中的方法签名与父类的方法完全匹配(包括方法名、参数类型和返回类型),编译器会确认这是合法的重写。
- 它是一种文档化手段,让代码更具可读性,明确表明子类有意覆盖父类的行为。
- 编译时检查:
- 当你加上 @Override 时,编译器会严格检查:
- 子类方法是否真的重写了父类中的某个方法。
- 方法签名是否完全匹配(包括参数列表和返回类型)。
- 如果不匹配(例如拼写错误、参数类型不一致或父类没有对应方法),编译器会报错,提示开发者修复问题。
- 当你加上 @Override 时,编译器会严格检查:
- 提高代码鲁棒性:
- 防止意外的错误。例如,如果父类方法被重命名或移除,而子类未更新,编译器会报错,提醒开发者注意。
- 它有助于在重构或维护代码时减少 bug。
为什么加上 @Override 和不加结果一样?
- 代码运行依赖动态绑定:
- Java 是面向对象的语言,方法调用基于对象的实际类型(多态)。在你的代码中,Child 对象的 add 和 addAll 方法会被调用,无论是否加了 @Override,运行时行为不会改变,因为方法签名和逻辑是正确的。
- IntelliJ IDEA 未报错:
- 在你的代码中,Child 中的 add(int number) 和 addAll(int[] numbers) 方法确实正确重写了 Base 中的对应方法(方法名、参数类型和返回类型都匹配)。因此,编译器(包括 IntelliJ 的检查)认为这是合法的重写,不需要报错。
- 如果方法签名不匹配(例如参数类型错误或返回类型不兼容),不加 @Override 不会报错,但加了 @Override 会导致编译错误。
- @Override 是可选的:
- @Override 是一个可选注解。Java 允许子类重写父类方法而不加此注解,只要方法签名匹配,程序依然能正常运行。
加不加 @Override 影响大吗?
- 不加 @Override 的潜在问题:
- 误写方法名:如果子类方法名拼写错误(例如写成 addd 而不是 add),而不加 @Override,编译器不会报错,因为这会被视为一个新方法。加了 @Override 后,编译器会检测到父类没有对应方法,报错提示修正。
- 维护难度增加:没有 @Override 的明确标记,后续开发者可能不清楚某个方法是否意在重写父类,增加代码理解成本。
- 重构风险:如果父类方法被修改或移除,子类方法可能无意中变成无效重写,缺乏 @Override 的检查可能导致问题被忽略。
- 加 @Override 的好处:
- 错误预防:编译时检查能及时发现重写错误,提高代码可靠性。
- 代码清晰度:明确表示方法是重写的,方便团队协作和代码审查。
- 工具支持:IDE(如 IntelliJ)可以利用 @Override 提供更好的代码导航和重构支持。
- 实际影响:
- 运行时无影响:加不加 @Override,程序的输出结果(例如 System.out.println(c.getSum()); 的值)不会改变。
- 开发时有影响:加了 @Override 可以避免因疏忽导致的编译错误,特别是在大型项目或多人协作中。
你的代码的具体情况
- 在 Base 类中,add(int number) 和 addAll(int[] numbers) 是公共方法,Child 类正确重写了这些方法。
- 运行 TestUtils.main() 时,创建 Child 对象 c,调用 c.addAll(new int[]{1, 2, 3}) 和 c.getSum(),结果计算基于 Child 的实现(sum 累加了 1 + 2 + 3 = 6)。
- 无论是否加 @Override,sum 的值和输出 6 都不会改变,因为方法逻辑一致。
建议
- 推荐加上 @Override:
- 特别是在团队开发或维护复杂代码时,@Override 能提高代码质量和可维护性。
- 它是一个好习惯,符合 Java 编码规范(例如 Oracle 的 Java 编码标准)。
- 不加也可以:
- 如果是个人小项目,且确信方法重写无误,可以不加。但这可能在未来维护时埋下隐患。
总结
@Override 的主要作用是编译时检查和文档化重写行为,加不加对运行结果没有影响,但在开发和维护阶段有显著好处。
鉴于你的代码目前正确重写了方法,IntelliJ 未报错是正常的,但建议保留 @Override 以确保代码鲁棒性和可读性。
5、如何理解, Java 中的继承和组合,对比例子说明。
如下将通过代码示例对比 Java 中的继承和组合,帮助理解两者的区别和使用场景。以下是具体的代码和解释:
代码示例
// 父类(用于继承) class Animal { protected String name; public Animal(String name) { this.name = name; } public void eat() { System.out.println(name + " is eating."); } } // 子类(通过继承) class Dog extends Animal { public Dog(String name) { super(name); } public void bark() { System.out.println(name + " is barking."); } } // 组件类(用于组合) class Leg { public void move() { System.out.println("Leg is moving."); } } // 主类(通过组合) class Robot { private Leg leg; // 持有 Leg 对象的引用 public Robot() { this.leg = new Leg(); // 初始化组合对象 } public void walk() { leg.move(); // 调用组合对象的 move 方法 System.out.println("Robot is walking."); } } public class Main { public static void main(String[] args) { // 使用继承 Dog dog = new Dog("Buddy"); dog.eat(); // 从 Animal 继承的方法 dog.bark(); // Dog 特有的方法 System.out.println("---"); // 使用组合 Robot robot = new Robot(); robot.walk(); // 调用 Robot 的 walk 方法,内部使用 Leg } }
输出结果
Buddy is eating. Buddy is barking. --- Leg is moving. Robot is walking.
对比解释
1. 继承 (Inheritance)
- 定义:子类通过 extends 关键字继承父类的属性和方法,子类可以直接使用或重写父类的方法。
- 代码体现:
- Dog 继承了 Animal,直接获得了 eat() 方法,并添加了自己的 bark() 方法。
- 使用 super(name) 调用父类的构造方法。
- 特点:
- 表示“is-a”关系(Dog is a Animal)。
- 代码复用性强,但继承层次过深可能导致复杂性增加。
- 无法在运行时改变父类行为(静态绑定)。
- 优点:简单直接,适合表示类之间的强耦合关系。
- 缺点:继承是单继承(Java 中一个类只能有一个直接父类),灵活性有限。
2. 组合 (Composition)
- 定义:一个类通过持有另一个类的对象(引用)来使用其功能,类似于“has-a”关系。
- 代码体现:
- Robot 包含一个 Leg 对象的引用,通过 leg.move() 调用 Leg 的方法。
- Robot 的 walk() 方法结合了 Leg 的功能和自己的逻辑。
- 特点:
- 表示“has-a”关系(Robot has a Leg)。
- 运行时可以动态替换或修改组合对象(例如换一个 Leg 实现)。
- 更灵活,适合模块化设计。
- 优点:解耦性强,可以在运行时调整组件,扩展性好。
- 缺点:需要手动管理组合对象,代码可能稍显冗长。
对比总结
| 特性 | 继承 (Dog extends Animal) | 组合 (Robot has a Leg) |
|---|---|---|
| 关系 | is-a | has-a |
| 实现方式 | extends | 持有对象引用 |
| 灵活性 | 较低(单继承) | 较高(可动态替换) |
| 耦合度 | 较高 | 较低 |
| 使用场景 | 表示类层次结构 | 模块化、复用组件 |
理解建议
- 继承适合描述“本质上的分类”(如狗是动物),但要避免过度继承导致的“继承地狱”。
- 组合适合构建复杂的对象(如机器人由腿、手等组成),更符合现代面向对象设计的“优先使用组合而非继承”原则。
6、虚方法的概念、该如何理解?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号