AI学习——常见问题思考与解答整理
1. 为什么神经网络在训练的时候,每次都要用batch_size的样本去训练,而不是用全量样本?
- 计算效率:当我们使用GPU进行训练时,小批量的数据可以并行处理,从而提高计算效率
- 内存限制:全量样本可能会超过硬件的内存限制,特别是对于大型数据集和复杂模型。使用小批量样本可以有效地管理内存使用
- 收敛速度和泛化能力:使用小批量样本可以增加模型训练的随机性,这有助于防止模型陷入局部最优解,从而提高模型的收敛速度和泛化能力
- Batch Normalization:Batch Normalization是一种常用的训练神经网络的方法,它也需要在小批量样本上进行操作。
总的来说,使用batch_size的样本进行训练是一种权衡计算效率、内存使用、模型性能和训练稳定性的有效方法。
2. Batch Normalization 的概念、作用、通俗解释和举例。
- 概念:Batch Normalization是2015年由Google提出的一种数据归一化方法。它的主要目标是将每一层的输入都进行归一化处理,使得输入的数据符合同一分布。
- 作用:Batch Normalization的作用主要有以下几点:
a) 加快模型训练时的收敛速度。
b) 使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。
c) 起到一定的正则化作用,可在一定程度上替代Dropout.
- 通俗解释:Batch Normalization的操作可以简单地理解为以下几个步骤:
a) 计算一个批次(batch)内的数据均值和方差。
b) 使用这个均值和方差将原始数据标准化,使得数据的均值为0,方差为1。
c) 对标准化后的数据进行缩放和平移,这两个操作的参数是可学习的,可以通过反向传播进行优化。
- 举例:假设我们有一个批次的数据,每个数据点有三个特征。在进行Batch Normalization时,我们首先计算每个特征在这个批次中的均值和方差,然后使用这些均值和方差将每个特征标准化。最后,我们对每个特征进行缩放和平移,得到最终的输出.
3. 1x1卷积核的作用理解。
4.CNN感受野参数、计算量的计算。
5. 耦合、解耦合的概念、通俗解释、举例说明。
7.为什么梯度的方向是函数下降速度最快的方向?从定量+定性两个角度分别给出证明。
8.计算机视觉中的双线性插值法的概念、通俗解释、作用是啥?
9.机器学习中的 hold-out set的概念,作用是什么?
答:"hold-out set"通常指的是在数据集中留出来的一部分数据,这部分数据不参与模型的训练过程,而是用来最后评估模型的性能。这种方法可以帮助我们理解模型在未见过的新数据上的表现如何,从而评估模型的泛化能力。
10.简单来说,训练集、验证集、测试集分别的作用是什么?
答:训练集、验证集和测试集(也被称为hold-out set)。
- 训练集用于训练模型,验证集用于调整模型的超参数,测试集(hold-out set)则用于最后评估模型的性能。
- 例如,假设你有100个样本,你可能会选择使用75个样本作为训练集,15个样本作为验证集,剩下的10个样本作为测试集(hold-out set)。在训练和验证过程中,你会尝试不同的模型和超参数,然后选择在验证集上表现最好的模型和超参数。最后,你会使用测试集(hold-out set)来评估这个最优模型的性能。这样做的目的是为了得到一个更准确的估计,关于模型在未见过的新数据上的表现如何。
11.关于嵌入层embedding size为什么总是要在输入数据的unique values的维度个数上+1?
@from pages 183 of AAAMLP book
# embedding size is always 1 more than unique values in input out = layers.Embedding(num_unique_values + 1, embed_dim, name=c)(inp)
答: 这段代码是在创建一个嵌入层,用于将离散的输入(例如单词或类别标签)转换为连续的向量表示。这是自然语言处理和其他机器学习任务中常见的操作。这里的 num_unique_values + 1 是嵌入层的大小。num_unique_values 是输入数据中唯一值的数量。为什么要加呢?这是因为在处理离散数据时,我们通常会为不存在于训练数据中的值(例如,在测试数据中首次出现的单词)保留一个额外的索引。这就是为什么嵌入大小总是比输入中的唯一值数量多1的原因。所以,如果你有10个唯一的输入值,你的嵌入层的大小应该是。这样,如果在后续的数据中出现了一个新的、未在训练数据中见过的值,你的模型仍然可以处理它。这个额外的索引通常被称为“未知”或“OOV(词汇表外)”索引。
12.如何深入理解如下代码的含义?(体会下函数式编程写法)
# from pages 183 of AAAMLP book
1 num_unique_values = int(data[c].nunique()) 2 embed_dim = int(min(np.ceil((num_unique_values)/2), 50)) # 找出列中唯一值的数量,并将此数量作为嵌入向量维度 3 inp = layers.Input(shape=(1,)) # 这行代码定义了一个输入层,它的形状是(1,), 这意味着模型期望的输入是一个维度为1的向量。
# 这行代码定义了一个嵌入层,并将之前定义的输入层inp作为输入。嵌入层的大小是num_unique_values + 1# 嵌入的维度是embed_dim。这个嵌入层的名字是c。这里的双括号写法是函数式API的一种常见用法。layers.Embedding(num_unique_values + 1, embed_dim, name=c)定义了一个函数,这个函数接受一个输入,返回一个输出。当我们在后面加上(inp)时,就是在调用这个函数,输入是inp,输出赋值给了out。
4 out = layers.Embedding(num_unique_values + 1, embed_dim, name=c)(inp)
# 这行代码定义了一个1D空间dropout层,并将之前的嵌入层out作为输入。空间dropout是一种正则化技术,它在训练过程中随机丢弃输入的一部分,以防止过拟合。这里的0.3是丢弃率,意味着在训练过程中,输入的30%将被随机丢弃。 5 out = layers.SpatialDropout1D(0.3)(out)
13. 嵌入层的大小num_unique_values和嵌入维度embed_dim这两个有何区别?【概念易混淆】
答:嵌入层大小num_unique_values和嵌入维度embed_dim是两个不同的概念,例如:
- 假设我们有一个分类特征,它有四个唯一值:
{狗,猫,鸟,鱼}。这就意味着我们的嵌入层的大小num_unique_values是4(加1后为5,因为我们为未知类别预留了一个位置)。 - 现在,我们需要决定如何表示这些类别。我们可以选择将每个类别表示为一个二维向量(例如,
狗可以表示为[0.1, 0.3],猫可以表示为[0.4, 0.2]等)。这个二维向量就是我们的嵌入维度embed_dim。
综上,嵌入层大小num_unique_values决定了我们有多少个唯一的类别需要表示,而嵌入维度embed_dim决定了我们将如何表示每一个类别。
14. 下述代码应该如何理解?[__call__方法]
# from AAAMLP Books pages 159
class GreedyFeatureSelection: def __call__(self, X, y): """ Call function will call the class on a set of arguments """ # select features, return scores and selected indices scores, features = self._feature_selection(X, y) # transform data with selected features return X[:, features], scores X_transformed, scores = GreedyFeatureSelection()(X, y) # 这一行的写法?
答:__call__方法是Python中的一个特殊方法,它使得一个类的实例能够像函数一样被调用。也就是说,如果创建了一个类的实例obj,那么可以像调用函数一样调用obj(args),这将会执行类中的__call__方法。
在这个代码块中,首先使用make_classification函数生成了一些二分类数据,然后创建了一个GreedyFeatureSelection的实例,并调用它(就像调用函数一样)来进行特征选择。
15. 机器学习中经常谈到的pipeline是指什么?引出pipeline是什么解决什么问题?给出标准的概念、通俗解释和举例说明。
在机器学习中,“pipeline”(管道)是一种常用的概念,它可以帮助我们将多个处理步骤组合在一起,形成一个整体的处理流程。
标准概念:在Scikit-learn库中,Pipeline是一个包含多个转换步骤的工作流,最后一步可以是一个估计器。它按照顺序执行这些步骤,每一步都是一个元组,包含一个名称和一个转换器或者估计器对象。
通俗解释:你可以把pipeline想象成一个生产线,原始的数据就像是生产线上的原材料,每一步处理就像是生产线上的一个工作站,负责完成一项特定的任务,比如数据清洗、特征选择、模型训练等。最后,我们得到的就是经过一系列处理后的结果,比如预测的结果。
举例说明:假设我们有一个机器学习项目,需要先对数据进行标准化处理,然后进行主成分分析(PCA)降维,最后用逻辑回归模型进行训练。我们可以使用Pipeline来实现这个流程:
1 from sklearn.pipeline import Pipeline 2 from sklearn.preprocessing import StandardScaler 3 from sklearn.decomposition import PCA 4 from sklearn.linear_model import LogisticRegression 5 6 # 创建pipeline 7 pipe = Pipeline([ 8 ('scaler', StandardScaler()), # 数据标准化 9 ('pca', PCA(n_components=2)), # PCA降维 10 ('logistic', LogisticRegression()) # 逻辑回归 11 ]) 12 13 # 使用pipeline进行训练 14 pipe.fit(X_train, y_train) 15 16 # 使用pipeline进行预测 17 y_pred = pipe.predict(X_test)
引入pipeline的原因主要有两个:
- 简化代码:通过pipeline,我们可以将多个处理步骤组合在一起,使得代码更加简洁,也更容易理解。
- 防止数据泄露:如果我们在划分数据集之前就进行了预处理,可能会导致测试集的信息泄露到训练集中,从而影响模型的泛化能力。而pipeline可以确保我们的预处理步骤是在每一折的训练数据上独立完成的,从而避免了数据泄露的问题。
16. TF-IDF的全称、概念、引出的必要性、通俗解释并给出举例说明。
TF-IDF是"Term Frequency-Inverse Document Frequency"的缩写,中文可以翻译为"词频-逆文档频率"。它是一种常用于信息检索和文本挖掘的统计方法,用于评估一个词在一个文档集或一个语料库中的重要程度。
TF-IDF的概念:
- 词频 (TF) 是指一个词在文档中出现的频率。
- 逆文档频率 (IDF) 是一个词的重要性指标。如果一个词在很多文档中都出现,那么它的区分度就不高,IDF就会降低。
TF-IDF实际上是两者的乘积:
TF-IDF=TF×IDF
为什么要引出TF-IDF: 在处理文本数据时,我们经常需要从大量的文本中提取有用的信息,比如找出哪些词是重要的,哪些词是不重要的。TF-IDF就是一种有效的方法,它能够找出在某个文档中频繁出现,但在其他文档中不常出现的词,这些词往往能够很好地反映出文档的主题。
通俗解释: 假设我们有一篇关于篮球的文章,里面经常出现"篮球"、“投篮”、"运动员"这样的词,那么这些词的TF值就会很高。但是如果我们的语料库中有很多篇关于体育的文章,那么"运动员"这个词可能在很多文章中都会出现,所以它的IDF值就会降低。而"篮球"和"投篮"可能只在篮球相关的文章中出现,所以它们的IDF值就会较高。通过计算TF-IDF值,我们可以认为"篮球"和"投篮"是这篇文章的关键词。
举例说明:
好的,让我们通过一个具体的例子来看看如何计算TF-IDF。
假设我们有以下三篇文档:
- 文档1:篮球是一项很棒的运动。
- 文档2:足球也是一项很棒的运动。
- 文档3:篮球和足球都是很棒的运动。
我们想要计算"篮球"这个词在这三篇文档中的TF-IDF值。
步骤1:计算TF值
TF值是一个词在文档中出现的频率。在这个例子中,"篮球"在文档1和文档3中各出现了一次,而在文档2中没有出现。所以,"篮球"在文档1和文档3中的TF值为1,而在文档2中的TF值为0。
步骤2:计算IDF值
IDF值是一个词的重要性指标。它的计算公式为:
在这个例子中,总文档数为3,而包含"篮球"的文档数为2,所以"篮球"的IDF值为:
步骤3:计算TF-IDF值
TF-IDF值就是TF值和IDF值的乘积。所以,"篮球"在文档1和文档3中的TF-IDF值为:
而在文档2中的TF-IDF值为:
可以看到,尽管"篮球"在文档1和文档3中都出现了,但由于它在所有文档中的出现频率不高,所以它的TF-IDF值并不高。这就反映了TF-IDF的一个重要特性:一个词的TF-IDF值越高,那么这个词在描述文档的主题方面就越重要。

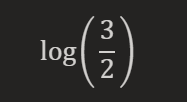
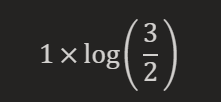
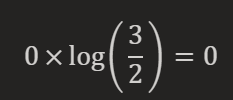
17. 机器学习中常见的超参数优化方法有哪些?
Cited from AAAMLP Books pages 176.
答:除了常见的Grid search, Random Search, 还有Downhill simplex algorithm, Nelder-Mead optimization, using a Bayesian technique with Gaussian process, genetic algorithm等算法。
18. 傅里叶变换详解。
19. 傅里叶变换最伟大的地方在于?该方法在人工智能、机器学习领域有哪些具体的使用场景?
伟大之处在于它能够将复杂的、时域上的信号转换为频域上的信号,这使得我们能够更好地理解和分析信号的特性。例如,我们可以通过傅里叶变换来分析信号的频率成分,或者找出信号中的周期性模式。
在人工智能和机器学习领域,傅里叶变换有许多具体的应用场景:
-
语音识别:在语音识别中,傅里叶变换可以用来提取语音信号的频率特征,这对于识别不同的语音和音素非常有用。
-
图像处理:在图像处理中,傅里叶变换可以用来分析图像的频率特性,例如边缘、纹理等。此外,傅里叶变换还可以用于图像的压缩和去噪。
-
时间序列分析:在时间序列分析中,傅里叶变换可以用来找出时间序列数据中的周期性模式,这对于预测和异常检测非常有用。
-
生物信息学:在生物信息学中,傅里叶变换可以用来分析基因序列和蛋白质结构。
-
雷达和无线通信:在雷达和无线通信中,傅里叶变换可以用来分析和处理信号。
这些只是傅里叶变换在人工智能和机器学习领域的一些应用,实际上,傅里叶变换的应用远不止这些。
20. **params 解包(unpacking)的代码写法如何理解?
答: 例如,我有一个字典params,它的内容如下:
params = {'n_estimators': 100, 'max_depth': 2}
当我们在调用函数或创建对象时,可以使用**params来将这个字典解包为关键字参数。例如:
model = ensemble.RandomForestClassifier(**params)
上一行代码等价于:
model = ensemble.RandomForestClassifier(n_estimators=100, max_depth=2)
这就是解包写法的精髓,自己体会下。
21. Python中常用的函数参数语法*args和**kwargs,举例说明下,加深理解。
*args:用于将参数打包成一个元组(tuple)。这在你不确定会有多少个参数,或者所有参数都是同类型并且可以按照顺序处理时非常有用。例如:
def add(*args): return sum(args) print(add(1, 2, 3, 4)) # 输出:10
**kwargs:用于将参数打包成一个字典(dictionary)。这在你需要处理一些可选的或者命名的参数时非常有用。例如:
def print_info(**kwargs): for key, value in kwargs.items(): print(f"{key}: {value}") print_info(name="Alice", age=25, city="London")
在这个例子中,print_info函数可以接受任意数量的命名参数,并打印出它们的信息。
这两种语法设计出来,就是为了可以让我们定义的函数更加灵活,能够处理各种不同的使用情况,应当理解这个初衷。
22. from functools import partial中,这两个模块的主要用途,使用场景分别是什么?
答:functools是Python的一个内置模块,提供了一些用于操作函数和可调用对象的工具。而partial是functools模块中的一个函数。
functools.partial的主要用途: functools.partial的主要用途是"冻结"一部分函数的参数或关键字参数,创建一个新的可调用对象。这个新的可调用对象可以更简单地调用原函数,因为你不需要提供所有的参数。
functools.partial的使用场景: 假设你有一个函数,它接受很多参数,但在大多数情况下,某些参数都是固定的。你可以使用functools.partial来创建一个新的函数,这个新函数已经包含了那些固定的参数。例如:
from functools import partial def power(base, exponent): return base ** exponent # 创建一个新的函数,计算平方 square = partial(power, exponent=2) print(square(5)) # 输出:25
注意:在数学中,"partial"确实常常用来表示偏导数,这意味着我们在考虑一个多变量函数时,固定其他变量,只关注某一个变量的变化。这与functools.partial的功能有一定的相似性,因为functools.partial也是固定一部分参数,创建一个新的函数。
然而,这两者之间还是有一些区别的。在数学中,偏导数是一种微分运算,关注的是函数值随着某一变量的微小变化而产生的变化。而在Python中,functools.partial并不涉及到任何微分或者变化,它只是简单地固定了一部分参数。
所以,虽然这两者在某种程度上都涉及到了"固定一部分,关注一部分"这一概念,但它们在具体的含义和应用上还是有所不同的。
23. multi-class, multi-label classification各自分别的概念、差异是什么?
答:这两者首先都是机器学习中的分类任务,但它们的目标和处理方式有所不同。
-
多类别分类【multi-class】:在这种任务中,每个样本只能属于一个类别。例如,假设我们有一个动物分类的任务,类别包括"猫"、“狗"和"鸟”,每个样本(动物的图片)只能被分类为这三个类别中的一个。
-
多标签分类【multi-label classification】:在这种任务中,每个样本可以属于多个类别。例如,假设我们有一个电影分类的任务,类别包括"喜剧"、“动作”、“爱情"等,每部电影可以被标记为多个类别,比如一部电影既可以是"动作"也可以是"爱情”。
24. albumentations这个库的作用和使用场景,最后举例说明下具体使用。
albumentations是一个Python库,用于图像增强。图像增强在深度学习和计算机视觉任务中被用来提高训练模型的质量。图像增强的目的是从现有数据中创建新的训练样本。
albumentations库提供了一种简单统一的API来处理所有数据类型:图像(RBG图像,灰度图像,多光谱图像),分割掩码,边界框和关键点。
该库包含超过70种不同的增强方法,以从现有数据生成新的训练样本。 albumentations库可以与流行的深度学习框架(如PyTorch和TensorFlow)一起使用,它被广泛应用于工业,深度学习研究,机器学习竞赛和开源项目中。
举例用法:
import albumentations as A import cv2 # 声明一个增强管道 transform = A.Compose( [ A.RandomCrop(width=256, height=256), A.HorizontalFlip(p=0.5), A.RandomBrightnessContrast(p=0.2), ] ) # 使用OpenCV读取图像并将其转换为RGB颜色空间 image = cv2.imread("image.jpg") image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 增强图像 transformed = transform(image=image) transformed_image = transformed["image"]
在上述案例中:我首先定义了一个名为transform的增强管道,然后使用这个管道对图像进行了增强,这就是albumentations的使用场景。
25. 向上采样的诸多方法中,分别解释下如下几种方法原理、作用、优缺点。
- 最近邻插值(Nearest neighbor interpolation)
- 双线性插值(Bi-linear interpolation)
- 双立方插值(Bi-cubic interpolation)
与上述方法相对应的,转置卷积(transposed convolution/or up-convolution)或反卷积(deconvolution),也要进行原理解释。
参考:https://cloud.tencent.com/developer/article/2029797?areaSource=106005.11
26. up-sampling, down-sampling的概念分别是什么?
答:
27. up-sampling与up-convolution有哪些区别?
答:
28. 在sklearn中,模型总是先fit数据A,然后再transform数据A,为什么fit和transform用的都是同一个数据A,而不是不同的数据?
# from AAAMLP Books pages 228
from sklearn.feature_extraction.text import CountVectorizer # create a corpus of sentences corpus = [ "hello, how are you?", "im getting bored at home. And you? What do you think?", "did you know about counts", "let's see if this works!", "YES!!!!" ] # initialize CountVectorizer ctv = CountVectorizer() # fit the vectorizer on corpus ctv.fit(corpus) corpus_transformed = ctv.transform(corpus) # 比如此处fit, transform都是用的corpus
答:在sklearn中,fit和transform方法通常用于预处理数据。这两个方法的目的和使用方式如下:
-
fit方法:该方法用于学习数据的属性。例如,在上述代码中,CountVectorizer的fit方法会学习语料库(corpus)中的所有单词,并将其保存为词汇表。 -
transform方法:该方法用于根据fit方法学习到的属性来转换数据。在上述代码中,CountVectorizer的transform方法会将语料库中的每个句子转换为一个向量,向量的每个元素对应于词汇表中的一个单词,元素的值表示该单词在句子中出现的次数。
为什么fit和transform用的是同一个数据集呢?这是因为我们需要确保模型是根据我们的训练数据进行训练的。如果我们在不同的数据集上fit和transform,那么我们的模型可能无法准确地反映训练数据的特性。例如,如果我们在一个包含很多专业术语的数据集上fit,然后在一个日常对话的数据集上transform,那么许多日常对话中的单词可能不会出现在词汇表中,从而导致转换的结果不准确。
然而,有时我们可能会在一个数据集上fit,然后在另一个数据集上transform。例如,在训练模型时,我们通常会在训练集上fit,然后在训练集和测试集上transform。这样做的目的是防止信息泄露,确保我们的模型在测试时能够公正地评估其对未知数据的预测能力。
29. 解释下如下代码的输出含义。
# from AAAMLP Books pages 228 from sklearn.feature_extraction.text import CountVectorizer # create a corpus of sentences corpus = [ "hello, how are you?", "im getting bored at home. And you? What do you think?", "did you know about counts", "let's see if this works!", "YES!!!!" ] # initialize CountVectorizer ctv = CountVectorizer() # fit the vectorizer on corpus ctv.fit(corpus) corpus_transformed = ctv.transform(corpus) # 比如此处fit, transform都是用的corpus print(corpus_transformed) (0, 2) 1 (0, 9) 1 (0, 11) 1 (0, 22) 1 (1, 1) 1 (1, 3) 1 (1, 4) 1 (1, 7) 1 (1, 8) 1 (1, 10) 1 (1, 13) 1 (1, 17) 1 (1, 19) 1 (1, 22) 2 (2, 0) 1 (2, 5) 1 (2, 6) 1 (2, 14) 1 (2, 22) 1 (3, 12) 1 (3, 15) 1 (3, 16) 1 (3, 18) 1 (3, 20) 1 (4, 21) 1
这个输出是一个稀疏矩阵,表示CountVectorizer转换后的语料库。每一行对应于语料库中的一个句子,每一列对应于词汇表中的一个单词。元素的值表示该单词在句子中出现的次数。
例如,(0, 2) 1表示在第一个句子(索引为0)中,词汇表中的第3个单词(索引为2)出现了1次。(1, 22) 2表示在第2个句子(索引为1)中,词汇表中的第23个单词(索引为22)出现了2次。
注意,由于CountVectorizer默认使用稀疏表示,所以只显示非零元素。也就是说,如果一个单词在一个句子中没有出现,那么这个单词对应的元素就不会在输出中显示。
30. NLP中的Stemming 和lemmatization 的概念、引出所为了解决的问题、通俗解释和举例说明、共性、差异性。
There are a lot more things in the basics of NLP. One term that you must be aware
of is stemming. Another is lemmatization. Stemming and lemmatization reduce a
word to its smallest form. In the case of stemming, the processed word is called the
stemmed word, and in the case of lemmatization, it is known as the lemma. It must
be noted that lemmatization is more aggressive than stemming and stemming is
more popular and widely used. Both stemming and lemmatization come from
linguistics.
—————— from AAAMLP Book pages 239
词干提取(stemming),另一个是词形还原(lemmatization),这两者都是将单词还原到其最小形式。”
-
词干提取(Stemming):这是一种将单词还原为其基本形式(或词干)的过程。例如,“running”、“runner”和“ran”这三个单词的词干都是“run”。词干提取的目的是减少词汇的复杂性,并将不同形式的同一单词统一表示。
-
词形还原(Lemmatization):这是一种更复杂的过程,它考虑了单词的词性和语法规则,以将单词还原为其词元(或基本形式)。例如,“am”、“are”和“is”这三个单词的词元都是“be”。词形还原的目的是获得更准确的单词基本形式。
这两种方法都是为了解决单词形态变化带来的问题。在自然语言处理中,我们通常希望将不同形式的同一单词视为相同的单词。
例如,在文本分类或情感分析等任务中,我们不希望因为单词的形态变化而影响我们的模型。通过词干提取和词形还原,我们可以将单词还原为其基本形式,从而减少词汇的复杂性,并提高模型的性能。
共性:
- 目标:两者都是用于将单词还原为其基本形式的技术,都旨在减少词汇的复杂性,并将不同形式的同一单词统一表示。
- 应用:在文本分类、情感分析、信息检索等自然语言处理任务中,都可以使用这两种技术。
差异性:
- 方法:词干提取通常使用启发式处理方法来去除单词的词尾,可能会导致产生不存在的单词。而词形还原则使用词典和词性分析来确定单词的基本形式,通常能得到更准确的结果。
- 结果:例如,对于单词“running”,词干提取可能得到“run”,而词形还原则会得到“run”。
- 精度:词形还原通常比词干提取更精确,但也更消耗计算资源。
31. 关于np.take_along_axis()函数的理解,和使用举例。
import numpy as np # 创建一个源数组 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 创建一个索引数组 indices = np.array([[2, 0, 1], [1, 2, 0], [1, 0, 2]]) # 使用numpy.take_along_axis()函数 result1 = np.take_along_axis(arr, indices, axis=0) # axis=0 箭头方向向下 print(result1) [[7 2 6] [4 8 3] [4 2 9]] result2 = np.take_along_axis(arr, indices, axis=1) # axis=1 箭头方向向右 print(result2) [[3 1 2] [5 6 4] [8 7 9]]
其实不难,只是不要弄混淆,可根据这个案例体会下np.take_along_axis(数组, 索引, 轴向)的用法。
32.AUC的计算原理推导
[参考:https://blog.csdn.net/weixin_41362649/article/details/89081651]
之前看过挺多博客,印象比较深刻的是这种证明思路,暂时没找到感觉介绍的最好的那篇博文,找了一篇比较接近的博文。
对于成为高手,切不可只单纯了解调个包,一定要了解AUC原理。


根据该博主BUPT-WT的介绍的这类思路,我手写了如下推导的AUC计算的代码:
def auc_score(y_true, y_pred): zipList = list(zip(y_pred, y_true)) rank = [val2 for val1, val2 in sorted(zipList, key=lambda x: x[0])] # 按照y_pred从小到大的顺序, 获取相应的y_true posRankList = [i+1 for i in range(len(rank)) if rank[i]==1] # 根据rank, 获所有正例的升序排名列表 posCount, negCount = 0, 0 for i in range(len(y_true)): if y_true[i] == 1: # 分别统计正例、负例的数目 posCount += 1 else: negCount += 1 auc = round((sum(posRankList) - posCount*(posCount+1)/2) / (posCount * negCount), 4) # 计算auc,着重了解下分子部分即可 return auc
33. 对于二分类的precision和多分类的precision, 要注意区别。
答:二分类的precision是再熟悉不过了,precision = tp/(tp+fp)。但是对于多分类的precision则不是这样定义的。
在信息检索和推荐系统等场景中,我们更关心的是前k个最相关的结果,因此引入了Precision at K这个概念。在这种情况下,精度被定义为前k个预测结果中正确的数量除以k。这是因为在这些场景中,我们通常只关心前k个最相关的结果,而不是所有预测为阳性的结果。
def pk(y_true, y_pred, k): """ pk: precision at a given value k This function calculates precision at k for a single sample """ if k==0: return 0 y_pred = y_pred[:k] pred_set = set(y_pred) true_set = set(y_true) commmon_values = pred_set.intersection(true_set) return len(commmon_values) / len(y_pred[:k])
34. 数值微分 和 梯度下降方法的优劣对比?为什么后者的计算效率要更高?
35. 高可用的概念理解
高可用性(High Availability,HA)是指系统能够在一定时间内保持运行并对外提供服务的能力。它的目的是确保关键业务系统在发生故障时仍能继续运行,最大限度地减少系统停机时间,从而降低因系统中断而带来的经济损失和影响。
高可用性的必要性来自于以下几个方面:
- 业务连续性:对于许多企业和组织而言,系统的中断可能会造成巨大的经济损失和声誉损害。例如,银行系统、航空管制系统、电力控制系统等,一旦发生中断,将会产生严重后果。
- 数据安全性:一些关键数据系统,如医疗记录、金融交易记录等,必须确保数据的完整性和可靠性。高可用性系统能够在发生故障时保护数据不受损坏或丢失。
- 用户体验:对于面向用户的服务,如电子商务网站、社交媒体平台等,高可用性能够确保用户可以随时访问和使用这些服务,提高用户体验。
那么,如何通俗地解释高可用性的概念呢?我们可以借助一个生活中的例子:
想象一下,你家里有一台电冰箱。如果这台电冰箱只有一个压缩机,一旦压缩机发生故障,整个冰箱就无法工作,里面的食物会很快变质。但是,如果冰箱设计成有两个压缩机,当一个压缩机出现故障时,另一个压缩机可以立即接手工作,从而确保冰箱持续运行,食物不会变质。这就是高可用性的一个典型例子。
在现实中,高可用性通常是通过冗余、负载均衡、故障转移等技术手段来实现的。例如,在一个Web服务系统中,可以部署多台服务器,通过负载均衡将用户请求分发到不同的服务器上。如果某台服务器发生故障,负载均衡器会自动将请求转移到其他健康的服务器上,从而确保整个系统持续运行。
总之,高可用性旨在最大限度地减少系统中断时间,确保关键业务系统的连续运行,提高系统的可靠性和用户体验。
36. FAISS到底是什么东西,有什么作用,是只有cpu版本的吗?
FAISS的全称是"Facebook AI Similarity Search"。
Faiss 是一个由 Facebook AI 研究院开发的密集向量的高效相似度搜索库。它的主要作用是加速大规模相似向量搜索。
通俗来解释的话,FAISS就是一个用于快速搜索相似向量的工具库。
我们先理解什么是"相似向量"。向量可以简单地理解为一组有序数值,例如[1.2, 3.4, 2.1]就是一个三维向量。
在机器学习和人工智能领域,我们经常会把非结构化数据(如文本、图像等)先映射为向量表示,这样就可以用数值的方式来处理和分析这些数据了。
而"相似向量搜索"的任务,就是在一个大规模向量集合中,快速找到与给定向量最相似的若干个向量。这在信息检索、推荐系统、聚类等应用中非常有用。
FAISS之所以高效, 是因为它使用了多种优化的最近邻搜索算法和数据结构, 并针对不同硬件(CPU或GPU)进行了优化和加速。此外, 它还支持对海量向量进行压缩存储,节省内存开销。
总之,FAISS就是Facebook开源的一个工具库,用于加速在海量向量数据集上快速搜索最相似的向量,以支持相似性分析、推荐等人工智能应用。
具体来说,Faiss 可以用于:
- 向量搜索(Nearest Neighbor Search) 给定一个向量,快速找到库中与该向量最相似的 K 个向量。这在推荐系统、信息检索等领域有广泛应用。
- 向量聚类(Clustering) 对海量向量进行聚类,将相似的向量分为同一类。
- 向量编码(Encoding) 压缩海量向量,使用较少的内存来存储,从而加速搜索。
Faiss 支持 CPU 和 GPU 两种模式:
- CPU 模式 纯 CPU 版本,利用 BLAS/薄板机部分功能进行加速。
- GPU 模式 利用 GPU 并行计算能力加速向量间的距离计算和搜索,性能相比 CPU 版本有数量级的提升。
所以总结一下:
- Faiss 是一个高效的相似向量搜索库
- 支持 CPU 和 GPU 模式,GPU 模式性能更佳
- 在推荐系统、信息检索等需要向量搜索的场景有重要应用
- 由 Facebook AI 研究院开源
在 RocketQA 中,Faiss 主要被用于从海量候选段落中快速检索与问题相关的 Top-K 段落,作为最终答案生成的语料输入,从而提高了 QA 系统的效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号