利用爬虫获取网上医院药品价格信息 (下)
因为之前的爬虫存在着各种不足,在此我们进行一些必要的扩展和改进。
一、加入代理服务器
首先,编写另外一个爬虫搜集网上的免费代理服务器
编写代理服务器数据爬虫程序”getproxy2.py”,代码如下:


1 from bs4 import BeautifulSoup 2 import urllib2 3 from myLog import MyLog 4 import csv 5 import time 6 import re 7 8 class Item(object): 9 IP = None #IP地址 10 port = None #端口 11 type = None #类型 12 address = None #地址 13 14 class Get_proxy(object): 15 def __init__(self): 16 self.log = MyLog() 17 self.log.info(u'Get_proxy 开始运行!') 18 self.urls = self.get_urls() 19 self.log.info(u'获取需要访问的url,共 %d 个' % len(self.urls)) 20 self.proxy_list = self.spider(self.urls) 21 self.log.info(u'获取到代理服务器地址,共 %d 个' % len(self.proxy_list)) 22 self.alivelist = self.testproxy(self.proxy_list) 23 self.pipelines(self.alivelist) 24 self.log.info(u'Get_proxy 运行结束!') 25 26 def get_urls(self): 27 urls = [] 28 num_max = 20 29 for n in range(1,num_max+1): 30 url = 'http://www.xicidaili.com/wn/'+str(n) 31 urls.append(url) 32 return urls 33 34 def getresponsecontent(self,url): 35 try: 36 Headers = {"User-Agent":"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11"} 37 request = urllib2.Request(url.encode('utf8'),headers = Headers) 38 response = urllib2.urlopen(request) 39 except: 40 self.log.error(u'返回 URL: %s 数据失败' % url) 41 return '' 42 else: 43 self.log.info(u'返回URL: %s 数据成功' % url) 44 return response 45 46 def spider(self,urls): 47 items = [] 48 for url in urls: 49 time.sleep(10) 50 htmlcontent = self.getresponsecontent(url) 51 if htmlcontent == '': 52 continue 53 soup = BeautifulSoup(htmlcontent,'lxml') 54 proxys = soup.find_all('tr',attrs={'class':'odd'}) 55 for proxy in proxys: 56 item = Item() 57 elements = proxy.find_all('td') 58 item.IP = elements[1].get_text().strip() 59 item.port = elements[2].get_text().strip() 60 item.address = elements[3].get_text().strip() 61 item.type = elements[5].get_text().strip() 62 items.append(item) 63 64 return items 65 66 def testproxy(self,proxylist): 67 self.log.info(u'开始对获取到的代理服务器进行测试 ...') 68 aliveList = [] 69 ip_list = [] 70 URL = r'http://www.china-yao.com/' 71 regex = re.compile(r'china-yao.com') 72 for proxy in proxylist: 73 if proxy.IP in ip_list: 74 continue #去除列表中重复的代理服务器 75 server = proxy.type.lower() + r'://' + proxy.IP + ':' + proxy.port 76 self.log.info(u'开始测试 %s' % server) 77 opener = urllib2.build_opener(urllib2.ProxyHandler({proxy.type.lower():server})) 78 urllib2.install_opener(opener) 79 try: 80 response = urllib2.urlopen(URL,timeout=3) 81 except: 82 self.log.info(u'%s 连接失败' % server) 83 continue 84 else: 85 try: 86 string = response.read() 87 except: 88 self.log.info(u'%s 连接失败' % server) 89 continue 90 if regex.search(string): 91 self.log.info(u'%s 连接成功 .......' % server) 92 ip_list.append(proxy.IP) 93 aliveList.append(proxy) 94 return aliveList 95 96 97 def pipelines(self,alivelist): 98 filename = 'proxylist.csv' 99 self.log.info(u'准备将获取到的代理服务器地址保存数据到csv文件中...') 100 writer = csv.writer(file(filename,'wb')) 101 #writer.writerow([u'IP地址'.encode('utf8'),u'端口'.encode('utf8'),u'类型'.encode('utf8'),u'地址'.encode('utf8')]) 102 for aliveproxy in alivelist: 103 writer.writerow([aliveproxy.IP.encode('utf8'),aliveproxy.port.encode('utf8'),aliveproxy.type.encode('utf8'),aliveproxy.address.encode('utf8')]) 104 self.log.info(u'数据保存完毕!') 105 106 if __name__ == '__main__': 107 Get_proxy() 108
代码过长,进行了折叠
从网站http://www.xicidaili.com/wn/中抓取https格式的免费代理服务器。没必要太多,这里只抓取了前20页的信息,之后利用函数testproxy对这些代理服务器进行简单的测试,把那些没有响应的代理服务器删除,将能够正常使用的全部保存到输出文件'proxylist.csv'中,以便随后在主程序中读取调用。
在原先的主程序“main.py”开头处添加代码导入
1 from getproxy2 import Get_proxy
在类GetInfor中的__init__中增加Get_proxy的调用
如下:
1 Get_proxy() 2 self.proxylist = self.getproxylist('proxylist.csv')
编写GetInfor的方法 getproxylist
1 def getproxylist(self,filename): 2 proxylist = [] 3 reader = csv.reader(open(filename,'rb')) 4 for proxy in reader: 5 proxylist.append(proxy) 6 return proxylist
在原有的方法getresponsecontent的基础上,增加一个类似的方法,其中使用代理服务器。代码如下:
1 def getresponsecontent_by_proxy(self,url): 2 Headers = {"User-Agent":"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11"} 3 request = urllib2.Request(url.encode('utf8'),headers = Headers) 4 proxy = random.choice(self.proxylist) 5 server = proxy[2].lower() + r'://' + proxy[0] + ':' + proxy[1] 6 self.log.info(u'使用代理服务器 %s 访问 %s' % (server,url)) 7 opener = urllib2.build_opener(urllib2.ProxyHandler({proxy[2].lower():server})) 8 urllib2.install_opener(opener) 9 try: 10 response = urllib2.urlopen(request,timeout=3) 11 except: 12 self.log.error(u'返回 URL: %s 数据失败' % url) 13 return '' 14 else: 15 self.log.info(u'返回URL: %s 数据成功' % url) 16 return response.read() 17
每次访问都将利用random.choice(self.proxylist)在获取的所有代理服务器中随机挑选一个作为当前的代理服务器,这样每次对指定的URL的访问都是不同的代理服务器。
二、使用多线程同步运行spider
因为考虑到需要使用多线程同步抓取数据,所以这里需要修改原先的spider方法,而且还需要把之前的部分功能分到其他函数里。
这里先将编写一个方法get_urls,来根据药品名称获取所有需要抓取的url,代码如下:
1 def geturls(self,names): 2 urls = [] 3 for name in names: 4 if name != '': 5 self.log.info(u'尝试爬取%s 信息' % name.decode('GBK')) 6 url = 'http://www.china-yao.com/?act=search&typeid=1&keyword='+name.decode('GBK') 7 try: 8 htmlcontent = self.getresponsecontent(url) 9 except: 10 self.log.info(u'药品 %s 信息获取失败!' % name.decode('GBK')) 11 with open('namelist_error.txt','a') as namelist_error: 12 namelist_error.write(name+'\n') 13 continue 14 if htmlcontent == '': 15 self.log.info(u'药品 %s 信息获取失败!' % name.decode('GBK')) 16 with open('namelist_error.txt','a') as namelist_error: 17 namelist_error.write(name+'\n') 18 continue 19 soup = BeautifulSoup(htmlcontent,'lxml') 20 tagul = soup.find('ul',attrs={'class':'pagination'}) 21 tagpage = tagul.find_all('a') 22 self.log.info(u'此药品信息共%d 页' % len(tagpage)) 23 time.sleep(4) 24 if len(tagpage) == 0: 25 page = 0 26 else: 27 try: 28 page = int(tagpage[-1].get_text().strip()) 29 except: 30 page = int(tagpage[-2].get_text().strip()) 31 for i in range(1,page+1): 32 newurl = url+'&page='+str(i) 33 urls.append(newurl) 34 return urls
简单修改原本的spider 方法如下,访问url时使用刚刚创建的方法getresponsecontent_by_proxy。
1 def spider(self,urls,thread_num): 2 filename_error = u'N%dthread_errorlist.txt' % thread_num 3 for url in urls: 4 try: 5 htmlcontent = self.getresponsecontent_by_proxy(url) 6 if htmlcontent == '': 7 self.log.info(u'%s 页面读取失败!' % url) 8 with open(filename_error,'a') as f_error: 9 f_error.write(url.encode('utf8')+'\n') 10 continue 11 soup = BeautifulSoup(htmlcontent,'lxml') 12 tagtbody = soup.find('tbody') 13 tagtr = tagtbody.find_all('tr') 14 self.log.info(u'该页面共有记录 %d 条,开始爬取' % len(tagtr)) 15 for tr in tagtr: 16 tagtd = tr.find_all('td') 17 item = Item() 18 item.mc = tagtd[0].get_text().strip() 19 item.jx = tagtd[1].get_text().strip() 20 item.gg = tagtd[2].get_text().strip() 21 item.ghj = tagtd[3].get_text().strip() 22 item.lsj = tagtd[4].get_text().strip() 23 item.scqy = tagtd[5].get_text().strip() 24 self.items.append(item) 25 self.log.info(u'页面%s 数据已保存' % url) 26 sleeptime = random.randint(2,5) 27 time.sleep(sleeptime) 28 except: 29 with open(filename_error,'a') as f_error: 30 f_error.write(url.encode('utf8')+'\n') 31 continue
利用模块threading开启多线程,首先调用模块
1 import threading
编写方法run,利用threading中的类Thread开启多线程调用前面编写的方法run,代码如下:
1 def run(self,urls,thread): 2 urls_list = [] 3 if len(urls)%thread==0: 4 length = len(urls)//thread 5 else: 6 length = len(urls)//thread+1 7 for i in range(thread): 8 urls_list.append(urls[length*i:length*i+length]) 9 self.log.info(u'开始多线程模式,线程数: %d' % thread) 10 for j in range(1,thread+1): 11 time.sleep(1) 12 t = threading.Thread(target=self.spider,args=(urls_list[j-1],j,)) 13 t.start() 14 t.join() 15 self.log.info(u'多线程模式结束')
这里先把需要访问的url列表urls_list按照分配的线程数平均分割给各线程,之后再分别调用方法run来抓取分配到的url上的信息。
三、运行程序
代码修改结束后,运行程序。
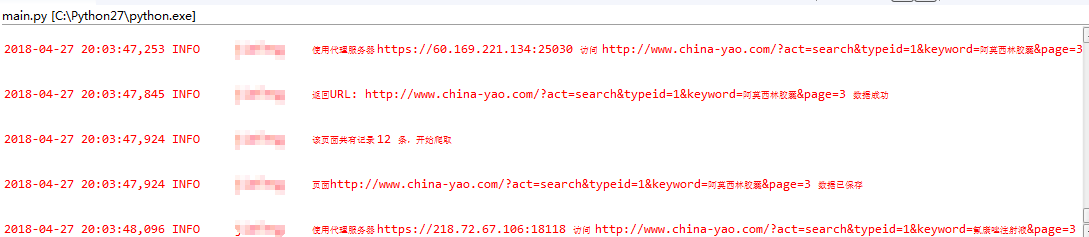
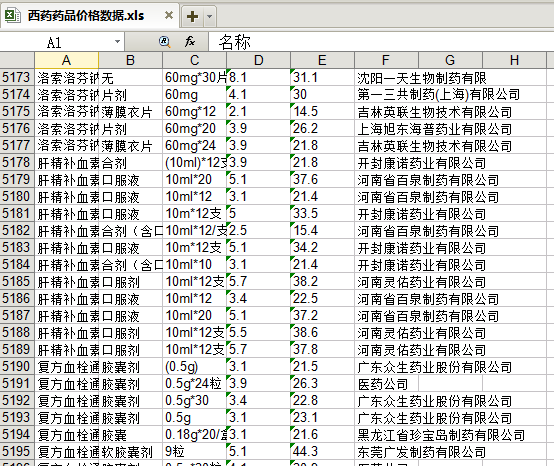
从生成的结果来看,效果还算满意。
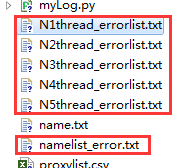
其中,“namelist_error.txt”,“N1thread_errorlist.txt”····“N5thread_errorlist.txt”为因服务器或网络原因而抓取失败的药品名称和url列表,数量不多,单独设计spider进行抓取就可。如果抓取的数据量过大,将__init__中的self.pipelines_xls(self.items)替换成self.pipelines_csv(self.items),将获取到的数据保存到csv文件中。
下面为修改后的main.py文件的全部代码:
1 from bs4 import BeautifulSoup 2 import urllib2 3 from myLog import MyLog 4 import time 5 import xlwt 6 import csv 7 import random 8 from getproxy2 import Get_proxy 9 import threading 10 11 class Item(object): 12 mc = None #名称 13 jx = None #剂型 14 gg = None #规格 15 ghj = None #供货价 16 lsj = None #零售价 17 scqy = None #生成企业 18 19 class GetInfor(object): 20 def __init__(self): 21 Get_proxy() 22 self.log = MyLog() 23 self.items = [] 24 self.thread = 5 25 self.starttime = time.time() 26 self.log.info(u'爬虫程序开始运行,时间: %s' % time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(self.starttime))) 27 self.medicallist = self.getmedicallist('name.txt') 28 self.proxylist = self.getproxylist('proxylist.csv') 29 self.urls = self.geturls(self.medicallist) 30 self.run(self.urls,self.thread) 31 self.log.info(u'共获取信息 %d 条' % len(self.items)) 32 self.pipelines_xls(self.items) 33 self.endtime = time.time() 34 self.log.info(u'爬虫程序运行结束,时间: %s' % time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(self.endtime))) 35 self.usetime = self.endtime - self.starttime 36 self.log.info(u'用时 %d时 %d分%d秒' % (self.usetime//3600,(self.usetime%3600)//60,(self.usetime%3600)%60)) 37 38 def getmedicallist(self,filename): 39 medicallist = [] 40 with open(filename,'r') as fp: 41 s = fp.read() 42 for name in s.split(): 43 medicallist.append(name) 44 self.log.info(u'从文件%s 中读取药品名称成功!获取药品名称 %d 个' % (filename,len(medicallist))) 45 return medicallist 46 47 def getproxylist(self,filename): 48 proxylist = [] 49 reader = csv.reader(open(filename,'rb')) 50 for proxy in reader: 51 proxylist.append(proxy) 52 return proxylist 53 54 def geturls(self,names): 55 urls = [] 56 for name in names: 57 if name != '': 58 self.log.info(u'尝试爬取%s 信息' % name.decode('GBK')) 59 url = 'http://www.china-yao.com/?act=search&typeid=1&keyword='+name.decode('GBK') 60 try: 61 htmlcontent = self.getresponsecontent(url) 62 except: 63 self.log.info(u'药品 %s 信息获取失败!' % name.decode('GBK')) 64 with open('namelist_error.txt','a') as namelist_error: 65 namelist_error.write(name+'\n') 66 continue 67 if htmlcontent == '': 68 self.log.info(u'药品 %s 信息获取失败!' % name.decode('GBK')) 69 with open('namelist_error.txt','a') as namelist_error: 70 namelist_error.write(name+'\n') 71 continue 72 soup = BeautifulSoup(htmlcontent,'lxml') 73 tagul = soup.find('ul',attrs={'class':'pagination'}) 74 tagpage = tagul.find_all('a') 75 self.log.info(u'此药品信息共%d 页' % len(tagpage)) 76 time.sleep(4) 77 if len(tagpage) == 0: 78 page = 0 79 else: 80 try: 81 page = int(tagpage[-1].get_text().strip()) 82 except: 83 page = int(tagpage[-2].get_text().strip()) 84 for i in range(1,page+1): 85 newurl = url+'&page='+str(i) 86 urls.append(newurl) 87 ## print urls 88 return urls 89 90 def spider(self,urls,thread_num): 91 filename_error = u'N%dthread_errorlist.txt' % thread_num 92 ## n = 0 93 for url in urls: 94 try: 95 htmlcontent = self.getresponsecontent_by_proxy(url) 96 if htmlcontent == '': 97 self.log.info(u'%s 页面读取失败!' % url) 98 with open(filename_error,'a') as f_error: 99 f_error.write(url.encode('utf8')+'\n') 100 continue 101 soup = BeautifulSoup(htmlcontent,'lxml') 102 tagtbody = soup.find('tbody') 103 tagtr = tagtbody.find_all('tr') 104 self.log.info(u'该页面共有记录 %d 条,开始爬取' % len(tagtr)) 105 for tr in tagtr: 106 tagtd = tr.find_all('td') 107 item = Item() 108 item.mc = tagtd[0].get_text().strip() 109 item.jx = tagtd[1].get_text().strip() 110 item.gg = tagtd[2].get_text().strip() 111 item.ghj = tagtd[3].get_text().strip() 112 item.lsj = tagtd[4].get_text().strip() 113 item.scqy = tagtd[5].get_text().strip() 114 self.items.append(item) 115 self.log.info(u'页面%s 数据已保存' % url) 116 sleeptime = random.randint(2,5) 117 time.sleep(sleeptime) 118 except: 119 with open(filename_error,'a') as f_error: 120 f_error.write(url.encode('utf8')+'\n') 121 continue 122 ## n += 1 123 ## if n >= 5: 124 ## break 125 ## self.log.info(u'数据爬取结束,共获取 %d条数据。' % len(items)) 126 127 def run(self,urls,thread): 128 urls_list = [] 129 if len(urls)%thread==0: 130 length = len(urls)//thread 131 else: 132 length = len(urls)//thread+1 133 for i in range(thread): 134 urls_list.append(urls[length*i:length*i+length]) 135 self.log.info(u'开始多线程模式,线程数: %d' % thread) 136 for j in range(1,thread+1): 137 time.sleep(1) 138 t = threading.Thread(target=self.spider,args=(urls_list[j-1],j,)) 139 t.start() 140 t.join() 141 self.log.info(u'多线程模式结束') 142 143 144 def pipelines_xls(self,medicallist): 145 filename = u'西药药品价格数据.xls'.encode('GBK') 146 self.log.info(u'准备保存数据到excel中...') 147 book = xlwt.Workbook(encoding = 'utf8',style_compression=0) 148 sheet = book.add_sheet(u'西药药品价格') 149 sheet.write(0,0,u'名称'.encode('utf8')) 150 sheet.write(0,1,u'剂型'.encode('utf8')) 151 sheet.write(0,2,u'规格'.encode('utf8')) 152 sheet.write(0,3,u'供货价'.encode('utf8')) 153 sheet.write(0,4,u'零售价'.encode('utf8')) 154 sheet.write(0,5,u'生产企业'.encode('utf8')) 155 for i in range(1,len(medicallist)+1): 156 item = medicallist[i-1] 157 sheet.write(i,0,item.mc) 158 sheet.write(i,1,item.jx) 159 sheet.write(i,2,item.gg) 160 sheet.write(i,3,item.ghj) 161 sheet.write(i,4,item.lsj) 162 sheet.write(i,5,item.scqy) 163 book.save(filename) 164 self.log.info(u'excel文件保存成功!') 165 166 def pipelines_csv(self,medicallist): 167 filename = u'西药药品价格数据.csv'.encode('GBK') 168 self.log.info(u'准备保存数据到csv中...') 169 writer = csv.writer(file(filename,'wb')) 170 writer.writerow([u'名称'.encode('utf8'),u'剂型'.encode('utf8'),u'规格'.encode('utf8'),u'供货价'.encode('utf8'),u'零售价'.encode('utf8'),u'生产企业'.encode('utf8')]) 171 for i in range(1,len(medicallist)+1): 172 item = medicallist[i-1] 173 writer.writerow([item.mc.encode('utf8'),item.jx.encode('utf8'),item.gg.encode('utf8'),item.ghj.encode('utf8'),item.lsj.encode('utf8'),item.scqy.encode('utf8')]) 174 self.log.info(u'csv文件保存成功!') 175 176 def getresponsecontent(self,url): 177 Headers = {"User-Agent":"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11"} 178 request = urllib2.Request(url.encode('utf8'),headers = Headers) 179 response = urllib2.urlopen(request) 180 try: 181 response = urllib2.urlopen(request,timeout=3) 182 except: 183 self.log.error(u'返回 URL: %s 数据失败' % url) 184 return '' 185 else: 186 self.log.info(u'返回URL: %s 数据成功' % url) 187 return response.read() 188 189 def getresponsecontent_by_proxy(self,url): 190 Headers = {"User-Agent":"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11"} 191 request = urllib2.Request(url.encode('utf8'),headers = Headers) 192 proxy = random.choice(self.proxylist) 193 server = proxy[2].lower() + r'://' + proxy[0] + ':' + proxy[1] 194 self.log.info(u'使用代理服务器 %s 访问 %s' % (server,url)) 195 opener = urllib2.build_opener(urllib2.ProxyHandler({proxy[2].lower():server})) 196 urllib2.install_opener(opener) 197 try: 198 response = urllib2.urlopen(request,timeout=3) 199 except: 200 self.log.error(u'返回 URL: %s 数据失败' % url) 201 return '' 202 else: 203 self.log.info(u'返回URL: %s 数据成功' % url) 204 return response.read() 205 206 if __name__ == '__main__': 207 GetInfor() 208

 浙公网安备 33010602011771号
浙公网安备 33010602011771号