学习笔记-10
区块链智能合约的发展现状:架构、应用与发展趋势
是什么把这个过程记录在链上,即数据如何上链,怎么判断是否上链,是什么机制使得智能合约实现的过程上链。
论文内容
本文致力于以区块链智能合约为研究对象, 对已有的研究成果进行全面的梳理和系统的概述,提出了智能合约的基础架构模型并以此为研究框架阐述了智能合约的运行机制与基础架构,总结了智能合约的研究挑战与进展、介绍了智能合约的技术优势与典型应用领域、讨论了智能合约的发展趋势,以期为智能合约的后续研究提供参考。
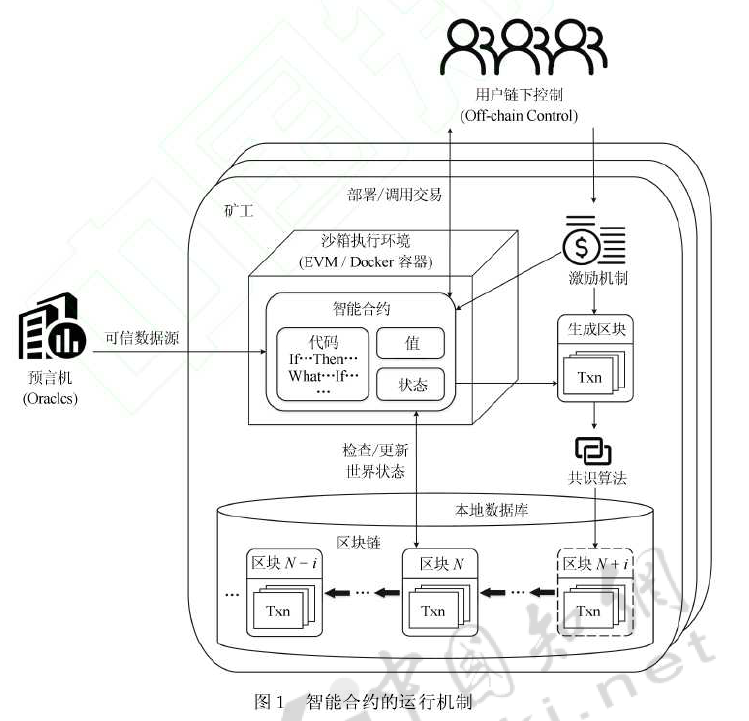
智能合约的运行机制
以太坊
以太坊在整体上可看作是一个基于交易的状态机: 起始于一个创世块 (Genesis) 状态, 然后随着交易的执行状态逐步改变一直到最终状态,这个最终状态就是以太坊世界的权威版本。 以太坊中引入了账户的概念以取代比特币 UTXO 模型,账户分为外部账户和合约账户两类, 两类账户都具有与之关联的账户状态和账户地址, 都可以存储以太坊专用加密货币以太币, 区别在于外部账户由用户私钥控制, 没有代码与之关联, 合约账户由合约代码控制, 有代码与之关联。用户只能通过外部账户在以太坊中发起交易,交易可以包含二进制数据 (Payload) 和以太币, 交易执行过程中可能产生一系列消息调用。 当交易或消息调用的接收者为以太坊指定空集 ? 时, 创建合约。 新合约账户地址由合约创建者的地址和该地址发出过的交易数量 Nonce 计算得到, 创建合约交易的Payload 被编译为 EVM 字节码执行, 执行的输出作为合约代码被永久存储。 当接收者为合约账户时, 合约账户内代码被激发在本地 EVM 中执行,Payload 作为合约的输入参数, 可信数据源则为合约提供必要外部世界信息。 所有执行结束后, 返回执行结果, 完整交易经矿工广播验证后和新的世界状态一起存入区块链。考虑到以太坊交易伴随带宽消耗, 存储消耗, 计算消耗等, 为了激励全球算力的投入和合理分配使用权, 避免系统因恶意程序走向失控, 以太坊中所有程序的执行都需要支付费用。 各种操作费用以 Gas 为单位计算, 任意的程序片段都可以根据规则计算出消耗的燃料数量, 完整交易的发起者需支付所有执行费用。 交易完成后, 剩余的燃料以购买时的价格退回到交易发送者账户, 未退回的费用作为挖出包含此交易区块的矿工的奖励。 若交易执行过程中发生燃料不足 (Out of gas, OOG)、堆栈溢出、无效指令等异常中止, 交易将成为无效交易, 已消耗 Gas 仍作为矿工贡献其计算资源的奖励。
超级账本超级账本 (Hyperledger fabric)
最早是由 IBM 牵头发起的致力于打造区块链技术开源规范和标准的联盟链, 2015 年起成为开源项目并移交给 Linux 基金会维护。 不同于比特币、以太坊等全球共享的公有链, 超级账本只允许获得许可的相关商业组织参与、共享和维护, 由于这些商业组织之间本身就有一定的信任基础, 超级账本被认为并非完全去中心化。超级账本使用模块化的体系结构, 开发者可按需求在平台上自由组合可插拔的会员服务、共识算法、加密算法等组件组成目标网络及应用。 链码 (Chaincode) 是超级账本中的智能合约, 开发者利用链码与超级账本交互以开发业务, 定义资产和管理去中心化应用。 联盟链中每个组织成员都拥有和维护代表该组织利益的一个或多个 Peer 节点, 联盟链由多个组织的 Peer 节点共同构成。 Peer 节点是链码及分布式账本的宿主, 可在 Docker 容器中运行链码, 实现对分布式账本上键―值对或其他状态数据库的读/写操作, 从而更新和维护账本。
超级账本的运行过程包含三个阶段 :
- 提议 (Proposal): 应用程序创建一个包含账本更新的交易提议 (Proposal), 并将该提议发送给链码中背书策略指定的背书节点集合 (Endorsing peers set) 作签名背书 。 每个背书节点独立地执行链码并生成各自的交易提议响应后 ,将响应值、读 / 写集合和签名等返回给应用程序 。 当应用程序收集到足够数量的背书节点响应后 , 提议阶段结束 。
- 打包 (Packaging): 应用程序验证背书节点的响应值、读 / 写集合和签名等 , 确认所收到的交易提议响应一致后 ,将交易提交给排序节点 (Orderer)。 排序节点对收到的众多交易进行排序并分批打包成数据区块后将数据区块广播给所有与之相连接的 Peer 节点 。
- 验证 (Validation): 与排序节点相连接的 Peer 节点逐一验证数据区块中的交易 ,确保交易严格依照事先确定的背书策略由所有对应的组织签名背书 。 验证通过后 , 所有 Peer 节点将新的数据区块添加至当前区块链的末端 , 更新账本 。 需要注意的是 ,此阶段不需要运行链码 , 链码仅在提议阶段运行 。
智能合约的基础模型
智能合约的生命周期根据其运行机制可概括为协商、开发、部署、运维、学习和自毁五个阶段, 其中开发阶段包括合约上链前的合约测试, 学习阶段包括智能合约的运行反馈与合约更新等。 图 2 所示为智能合约的基础架构模型, 模型自底向上由基础设施层、合约层、运维层、智能层、表现层和应用层组成, 以下将分层进行阐述。基础设施层: 封装了支持智能合约及其衍生应用实现的所有基础设施, 包括分布式账本及其关键技术、开发环境和可信数据源等, 这些基础设施的选择将在一定程度上影响智能合约的设计模式和合约属性。
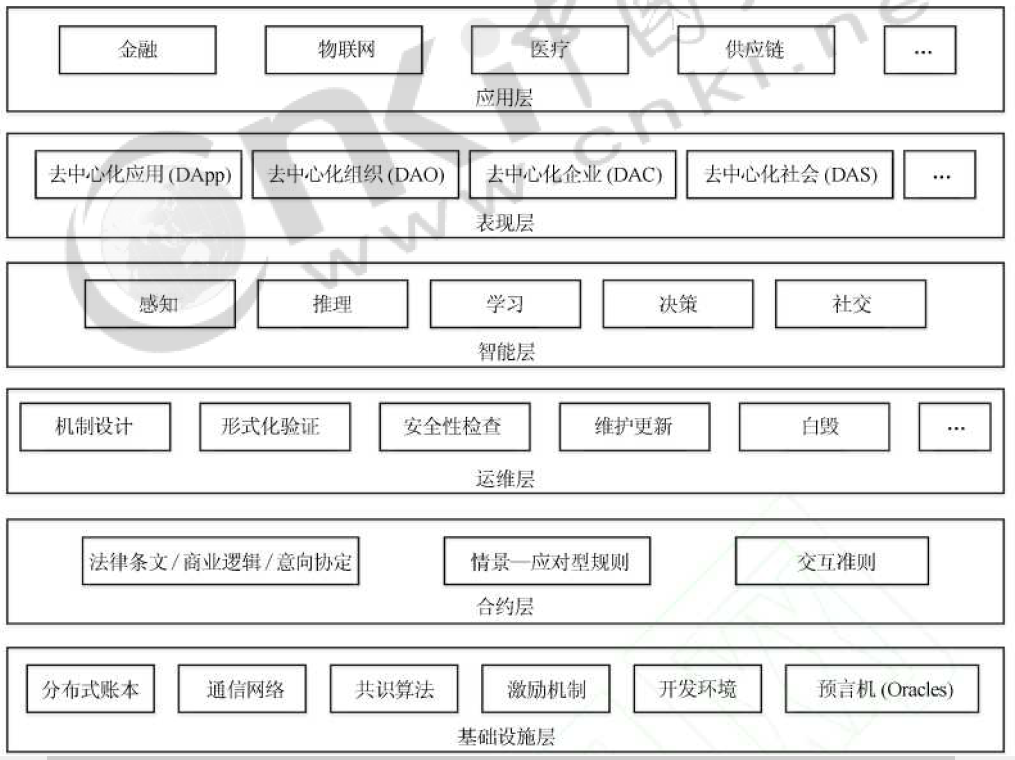
预言机
为保证区块链网络的安全, 智能合约一般运行在完全隔离的沙箱执行环境中 (如以太坊的EVM 及超级账本的 Docker 容器等), 除交易的附加数据外, 预言机可提供可信外部数据源供合约查询外部世界的世界状态或触发合约执行。 同时, 为保持分布式节点的合约执行结果一致, 智能合约也通过查询预言机实现随机性。
表现层
封装了智能合约在实际应用中的各类具体表现形式。 包括去中心化应用 (Decentralized application, DApp)、去中心化自治组织 (Decen-tralized autonomous organization, DAO)、去中心化自治企业 (Decentralized autonomous corpora-tion, DAC) 和去中心化自治社会 (Decentralized autonomous society, DAS) 等。区块链是具有普适性的去中心化技术架构, 可封装节点复杂行为的智能合约相当于区块链的应用接口, 帮助区块链的分布式架构植入不同场景。通过将核心的法律条文、商业逻辑和意向协定存储在智能合约中, 可产生各种各样的去中心化应用 (DApp), 而利用前四层构建的多代理系统, 又可逐步演化出各类去中心化自治组织 (DAO, 亦称去中心化自治企业, DAC) 和去中心化自治社会 (DAS), 这些表现形式有望改进传统的商业模式和社会生产关系, 为可编程社会奠定基础, 并最终促成分布式人工智能的实现。 以 DAO 为例, 只需将组织的管理制度和规则以智能合约的形式预先编码在区块链上,即可实现组织在无中心或权威控制干预下的自主运行。 同时, 由于 DAO 中的成员可以通过购买股份、代币 (Token), 或提供服务的形式成为股东并分享收益, DAO 被认为是一种对传统"自顶向下" 式层级管理的颠覆性变革, 可有效降低组织的运营成本, 减少管理摩擦, 提高决策民主化。
相关知识
1、OP-RETURN
在比特币的每一笔交易信息中,包含input和output两个部分。output里的脚本又称验证脚本,input里的脚本又称调用脚本。要想花掉交易A的ouput中的比特币,就需要构造一个交易B,能够使B的调用脚本满足A的验证脚本。
区块链可以看作是一个不可变的数据结构,所以人们试图利用这一特性开发其它应用。这就需要在交易记录中存储其它的数据。在普通的P2PH(pay to pubKey hash)交易中,可以将output里的验证脚本换成其它数据。这么做,会导致这笔交易里的比特币不能再被花费,因为很难再找到满足条件的调用脚本(需要反求哈希)。这种方法还有一个严重的缺点,即在比特币节点上,通常出于速度考虑,未被花费的交易(UTXO)都会被存储在内存中,因此这种交易就会占用许多内存空间,影响比特币网络的效率。
OP_RETURN的优点
通过OP_RETURN,我们可以在BCH区块链上存储任意信息而不会被篡改和删除。因为OP_Return数据是受BCH区块链保护的,伴随着我们所发送的交易。OP_Return一旦写入了区块链,就相当于有了一个时间戳,哪怕是同一区块里的交易,都因排序不一样,而有不同的时间戳。
其次,协议规定OP_RETURN不是UTXO,包含OP_RETURN的交易输出是不可花费(Unspendable)的,节点可以安全地将其移出UTXO集,从而不会影响UTXO集合的总体积,造成全网UTXO的膨胀。
目前按照BCH的协议规定,每个TX只能携带一个OP_RETURN输出,每个OP_RETURN最多携带220字节的数据。
写入OP_RETURN的方法
写入OP_RETURN可以使用createrawtransaction命令行接口或者JSON-RPC接口调用。当然通过一些类似于Memo.cash的去中心化的应用,你发布的信息都是被直接写入OP_RETURN的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号