
Bert源码解读(二)之Transformer 代码实现
一、注意力层(attention layer)
重要:本层主要就是根据论文公式计算token之间的attention_scores(QKT),并且做softmax之后变成attention_probs,最后再与V相乘。值得注意的是,中间利用了attention_mask的技巧,返回多头注意力值。
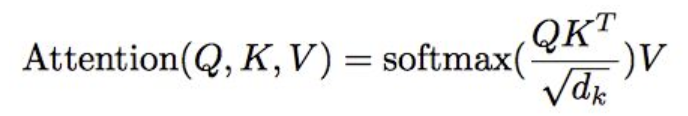
def attention_layer(from_tensor, # from_tensor映射为query,shape为[batch_size, from_seq_length,from_width] to_tensor, #to_tensor映射为key和value,shape为[batch_size, to_seq_length, to_width] attention_mask=None, # 里面的值为0或者1,在计算attention_score后,1的score值保持不变,0的score被置为-10000,shape [batch_size,from_seq_length, to_seq_length] num_attention_heads=1, size_per_head=512, #from_tensor映射为query后的维度,key同理 query_act=None, #通过一个全连接网络映射为query,所以有激活函数选项,其实transformer在调用的时候设置激活函数为None,没有用激活函数。 key_act=None, #同理 value_act=None,#同理 attention_probs_dropout_prob=0.0, #somfmax后的attention_probs会被随机drop掉一些,原论文中是0.1 initializer_range=0.02, do_return_2d_tensor=False, batch_size=None, from_seq_length=None, to_seq_length=None): """Performs multi-headed attention from `from_tensor` to `to_tensor`. This is an implementation of multi-headed attention based on "Attention is all you Need". If `from_tensor` and `to_tensor` are the same, then this is self-attention. Each timestep in `from_tensor` attends to the corresponding sequence in `to_tensor`, and returns a fixed-with vector. #这里from_tensor映射为query, This function first projects `from_tensor` into a "query" tensor and `to_tensor` into "key" and "value" tensors. These are (effectively) a list of tensors of length `num_attention_heads`, where each tensor is of shape [batch_size, seq_length, size_per_head]. Then, the query and key tensors are dot-producted and scaled. These are softmaxed to obtain attention probabilities. The value tensors are then interpolated by these probabilities, then concatenated back to a single tensor and returned. #实际中,多头注意力同时进行 In practice, the multi-headed attention are done with transposes and reshapes rather than actual separate tensors. Args: from_tensor: float Tensor of shape [batch_size, from_seq_length, from_width]. to_tensor: float Tensor of shape [batch_size, to_seq_length, to_width]. attention_mask: (optional) int32 Tensor of shape [batch_size, from_seq_length, to_seq_length]. The values should be 1 or 0. The attention scores will effectively be set to -infinity for any positions in the mask that are 0, and will be unchanged for positions that are 1. num_attention_heads: int. Number of attention heads. size_per_head: int. Size of each attention head. query_act: (optional) Activation function for the query transform. key_act: (optional) Activation function for the key transform. value_act: (optional) Activation function for the value transform. attention_probs_dropout_prob: (optional) float. Dropout probability of the attention probabilities. initializer_range: float. Range of the weight initializer. do_return_2d_tensor: bool. If True, the output will be of shape [batch_size * from_seq_length, num_attention_heads * size_per_head]. If False, the output will be of shape [batch_size, from_seq_length, num_attention_heads * size_per_head]. batch_size: (Optional) int. If the input is 2D, this might be the batch size of the 3D version of the `from_tensor` and `to_tensor`. from_seq_length: (Optional) If the input is 2D, this might be the seq length of the 3D version of the `from_tensor`. to_seq_length: (Optional) If the input is 2D, this might be the seq length of the 3D version of the `to_tensor`. Returns: float Tensor of shape [batch_size, from_seq_length, num_attention_heads * size_per_head]. (If `do_return_2d_tensor` is true, this will be of shape [batch_size * from_seq_length, num_attention_heads * size_per_head]). Raises: ValueError: Any of the arguments or tensor shapes are invalid. """ def transpose_for_scores(input_tensor, batch_size, num_attention_heads, seq_length, width): output_tensor = tf.reshape( input_tensor, [batch_size, seq_length, num_attention_heads, width]) output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3]) return output_tensor from_shape = get_shape_list(from_tensor, expected_rank=[2, 3]) to_shape = get_shape_list(to_tensor, expected_rank=[2, 3]) if len(from_shape) != len(to_shape): raise ValueError( "The rank of `from_tensor` must match the rank of `to_tensor`.") if len(from_shape) == 3: batch_size = from_shape[0] from_seq_length = from_shape[1] to_seq_length = to_shape[1] elif len(from_shape) == 2: if (batch_size is None or from_seq_length is None or to_seq_length is None): raise ValueError( "When passing in rank 2 tensors to attention_layer, the values " "for `batch_size`, `from_seq_length`, and `to_seq_length` " "must all be specified.") # Scalar dimensions referenced here: # B = batch size (number of sequences) # F = `from_tensor` sequence length # T = `to_tensor` sequence length # N = `num_attention_heads` # H = `size_per_head` from_tensor_2d = reshape_to_matrix(from_tensor) to_tensor_2d = reshape_to_matrix(to_tensor) # `query_layer` = [B*F, N*H],映射为query query_layer = tf.layers.dense( from_tensor_2d, num_attention_heads * size_per_head, activation=query_act, name="query", kernel_initializer=create_initializer(initializer_range)) # `key_layer` = [B*T, N*H], 映射为key key_layer = tf.layers.dense( to_tensor_2d, num_attention_heads * size_per_head, activation=key_act, name="key", kernel_initializer=create_initializer(initializer_range)) # `value_layer` = [B*T, N*H] ,映射为value value_layer = tf.layers.dense( to_tensor_2d, num_attention_heads * size_per_head, activation=value_act, name="value", kernel_initializer=create_initializer(initializer_range)) # `query_layer` = [B, N, F, H],转置 query_layer = transpose_for_scores(query_layer, batch_size, num_attention_heads, from_seq_length, size_per_head) # `key_layer` = [B, N, T, H],转置 key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads, to_seq_length, size_per_head) # Take the dot product between "query" and "key" to get the raw # attention scores. # `attention_scores` = [B, N, F, T],QK相乘,得到attention_scores attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True) attention_scores = tf.multiply(attention_scores, 1.0 / math.sqrt(float(size_per_head))) if attention_mask is not None: #利用attention_mask,去掉占位符带来的影响,attention_mask矩阵中占位符的位置设置为0 # `attention_mask` = [B, 1, F, T] attention_mask = tf.expand_dims(attention_mask, axis=[1]) # Since attention_mask is 1.0 for positions we want to attend and 0.0 for # masked positions, this operation will create a tensor which is 0.0 for # positions we want to attend and -10000.0 for masked positions. adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0 # Since we are adding it to the raw scores before the softmax, this is # effectively the same as removing these entirely. attention_scores += adder # Normalize the attention scores to probabilities. # `attention_probs` = [B, N, F, T],进行softmax,变成attention_probs attention_probs = tf.nn.softmax(attention_scores) # This is actually dropping out entire tokens to attend to, which might # seem a bit unusual, but is taken from the original Transformer paper. attention_probs = dropout(attention_probs, attention_probs_dropout_prob) # `value_layer` = [B, T, N, H] value_layer = tf.reshape( value_layer, [batch_size, to_seq_length, num_attention_heads, size_per_head]) # `value_layer` = [B, N, T, H] value_layer = tf.transpose(value_layer, [0, 2, 1, 3]) # `context_layer` = [B, N, F, H],最后与V相乘 context_layer = tf.matmul(attention_probs, value_layer) # `context_layer` = [B, F, N, H] context_layer = tf.transpose(context_layer, [0, 2, 1, 3]) if do_return_2d_tensor: # `context_layer` = [B*F, N*H] context_layer = tf.reshape( context_layer, [batch_size * from_seq_length, num_attention_heads * size_per_head]) else: # `context_layer` = [B, F, N*H] context_layer = tf.reshape( context_layer, [batch_size, from_seq_length, num_attention_heads * size_per_head]) return context_layer
Return:[batch_size, from_seq_length, num_attention_heads * size_per_head]
二、Transformer
下面就是Transformer框架的核心代码,也就是论文《Attention is all you need》中多层Encoder的完整实现,因为Bert只用了其中的encoder部分。
def transformer_model(input_tensor, #shape=[batch_size, seq_length, hidden_size] attention_mask=None, hidden_size=768, #这里就是论文中的H,也叫dmodel num_hidden_layers=12,#这里就是论文中的L num_attention_heads=12,#这里就是论文中的A intermediate_size=3072,#这里就是论文中的4H,也叫dff intermediate_act_fn=gelu,#feed-forward的激活函数 hidden_dropout_prob=0.1, attention_probs_dropout_prob=0.1, initializer_range=0.02, do_return_all_layers=False, share_parameter_across_layers=True): """Multi-headed, multi-layer Transformer from "Attention is All You Need". This is almost an exact implementation of the original Transformer encoder. See the original paper: https://arxiv.org/abs/1706.03762 Also see: https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py Args: input_tensor: float Tensor of shape [batch_size, seq_length, hidden_size]. attention_mask: (optional) int32 Tensor of shape [batch_size, seq_length, seq_length], with 1 for positions that can be attended to and 0 in positions that should not be. hidden_size: int. Hidden size of the Transformer. num_hidden_layers: int. Number of layers (blocks) in the Transformer. num_attention_heads: int. Number of attention heads in the Transformer. intermediate_size: int. The size of the "intermediate" (a.k.a., feed forward) layer. intermediate_act_fn: function. The non-linear activation function to apply to the output of the intermediate/feed-forward layer. hidden_dropout_prob: float. Dropout probability for the hidden layers. attention_probs_dropout_prob: float. Dropout probability of the attention probabilities. initializer_range: float. Range of the initializer (stddev of truncated normal). do_return_all_layers: Whether to also return all layers or just the final layer. Returns: float Tensor of shape [batch_size, seq_length, hidden_size], the final hidden layer of the Transformer. Raises: ValueError: A Tensor shape or parameter is invalid. """ if hidden_size % num_attention_heads != 0: raise ValueError( "The hidden size (%d) is not a multiple of the number of attention " "heads (%d)" % (hidden_size, num_attention_heads)) attention_head_size = int(hidden_size / num_attention_heads) input_shape = get_shape_list(input_tensor, expected_rank=3) batch_size = input_shape[0] seq_length = input_shape[1] input_width = input_shape[2] # The Transformer performs sum residuals on all layers so the input needs # to be the same as the hidden size. if input_width != hidden_size: raise ValueError("The width of the input tensor (%d) != hidden size (%d)" % (input_width, hidden_size)) # We keep the representation as a 2D tensor to avoid re-shaping it back and # forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on # the GPU/CPU but may not be free on the TPU, so we want to minimize them to # help the optimizer. prev_output = reshape_to_matrix(input_tensor) all_layer_outputs = [] for layer_idx in range(num_hidden_layers): if share_parameter_across_layers: name_variable_scope="layer_shared" else: name_variable_scope="layer_%d" % layer_idx # share all parameters across layers. add by brightmart, 2019-09-28. previous it is like this: "layer_%d" % layer_idx with tf.variable_scope(name_variable_scope, reuse=True if (share_parameter_across_layers and layer_idx>0) else False): #定义Transformer每一层Encoder的输入 layer_input = prev_output with tf.variable_scope("attention"): attention_heads = [] with tf.variable_scope("self"): #带入Attention计算公式进行计算 attention_head = attention_layer( from_tensor=layer_input, to_tensor=layer_input, attention_mask=attention_mask, num_attention_heads=num_attention_heads, size_per_head=attention_head_size, attention_probs_dropout_prob=attention_probs_dropout_prob, initializer_range=initializer_range, do_return_2d_tensor=True, batch_size=batch_size, from_seq_length=seq_length, to_seq_length=seq_length) attention_heads.append(attention_head) attention_output = None if len(attention_heads) == 1: attention_output = attention_heads[0] else: # In the case where we have other sequences, we just concatenate # them to the self-attention head before the projection. attention_output = tf.concat(attention_heads, axis=-1) # Run a linear projection of `hidden_size` then add a residual # with `layer_input`. #Attention计算完毕后进入一个线性映射,不带激活函数,因为有多头拼接,维度有变化,所以线性映射就确保输出的维度是hidden_size with tf.variable_scope("output"): attention_output = tf.layers.dense( attention_output, hidden_size, kernel_initializer=create_initializer(initializer_range)) attention_output = dropout(attention_output, hidden_dropout_prob) #最终输出前再add残差块要求的最初输入,然后再做批量Norm,变成均值为0方差为1的分布,BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的,这样不至于随着网络深度的加深,数据分布发生变化,网络收敛变得越来越慢。 attention_output = layer_norm(attention_output + layer_input) # The activation is only applied to the "intermediate" hidden layer. #进入feed-forward层,先是一个全连接网络层,输出维度intermediate_size=4*H,激活函数是GELU with tf.variable_scope("intermediate"): intermediate_output = tf.layers.dense( attention_output, intermediate_size, activation=intermediate_act_fn, kernel_initializer=create_initializer(initializer_range)) # Down-project back to `hidden_size` then add the residual. #再进入一个线性映射,不带激活函数,只是确保输出维度是hidden_size with tf.variable_scope("output"): layer_output = tf.layers.dense( intermediate_output, hidden_size, kernel_initializer=create_initializer(initializer_range)) layer_output = dropout(layer_output, hidden_dropout_prob) #同样残差块和批量Norm layer_output = layer_norm(layer_output + attention_output) #这里的layer_output或者prev_output就是每一层的输出 prev_output = layer_output all_layer_outputs.append(layer_output) if do_return_all_layers: final_outputs = [] for layer_output in all_layer_outputs: final_output = reshape_from_matrix(layer_output, input_shape) final_outputs.append(final_output) return final_outputs else: final_output = reshape_from_matrix(prev_output, input_shape)#直接返回最后一层的输出 return final_output
输入:[batch_size, seq_length, hidden_size]
输出:[batch_size, seq_length, hidden_size]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号