



基于融智学双重形式化的汉字汉语数学建模技巧
摘要:本文提出基于融智学双重形式化的汉字汉语数学建模途径。通过建立笔画、偏旁、汉字结构模型,将汉字分为形、音、实、虚等八类属性,语言单位分为言、辞、链等八类层次。采用有向图表示层面型结构,线性序列表示线串型结构,并定义复合迭加运算统一二者。运用范畴论建立统一数学模型,设计并验证通过的言和语的关系数据库实现方案。该体系为汉字汉语的计算理解和智能处理供应了完整的数学基础。
关键词:汉字汉语中文;融智学;双重形式化;数学模型;整个体系;统一数学结构;可视化图解
正文:
该模型完全纳入融智学双重形式化体系,为实现汉字汉语中文的深度计算理解与智慧重用奠定坚实基础。
以汉字汉语中文为例,分别对基本笔画和偏旁部首及所有不重复的汉字建立数学模型,对单音节(言)字(层面型结构)与混音节(语)即线串型结构的关系(两类结构迭加的复合型结构)分别按照八类字(言)含音形实虚解用象释八类字与八类语(言辞链块读句段篇)的数学建模,均可纳入融智学双重形式化!
以汉字汉语中文为典型范例,运用融智学双重形式化方法,对其内在结构进行精细的数学建模。
汉字汉语中文的融智学双重形式化数学模型
一、 基本元素的形式化定义
1.1 基本笔画层(元子层)
设基本笔画集合为:
B = {b₁, b₂, ..., bₙ}
其中每个 bᵢ 代表一个不可再分的笔画,如:横(一)、竖(丨)、撇(丿)、点(丶)、折()等。
笔画可定义为带属性的元组:
bᵢ = (type, start_point, end_point, curvature, stroke_order)
· type: 笔画类型
· start_point/end_point: 起止坐标
· curvature: 弯曲度参数
· stroke_order: 笔顺序号
1.2 偏旁部首层(元组层)
设偏旁部首集合为:
R = {r₁, r₂, ..., rₘ}
笔画的合法组合:就是每个偏旁部首
rⱼ = (b_{j1}, b_{j2}, ..., b_{jk}) ∈ B⁺
且满足组合约束条件 C_R(rⱼ) = true
二、 层面型结构:单音节字的八类字模型
2.1 汉字的形式化定义
设汉字集合为:
C = {c₁, c₂, ..., cₚ}
每个汉字 c 可表示为七元组:
c = (shape, sound, semantic, grammatical, explanatory, pragmatic, symbolic, interpretive)
其中各分量对应八类属性:
· shape ∈ S:形字(字形结构)
· sound ∈ P:音字(发音)
· semantic ∈ M:实字(实质含义)
· grammatical ∈ G:虚字(语法能力)
· explanatory ∈ E:解字(解释性)
· pragmatic ∈ U:用字(用法)
· symbolic ∈ I:象字(象征意义)
· interpretive ∈ T:释字/元字(阐释性)
2.2 层面型结构的数学表达
每个汉字 c 的层面型结构可建模为有向图:
Graph(c) = (V, E)
其中:
· 顶点集 V ⊆ B ∪ R ∪ {c} (笔画、偏旁、整字)
· 边集 E ⊆ V × V 表示组成关系
层面型结构的生成函数:
Layered_Structure: C → Graph
三、 线串型结构:混音节语的八类语模型
3.1 语言单位的形式化定义
设语言单位集合为语言 L 的克林闭包:
L = C⁺
八类语构成一个层次结构:
```
Language_Units = {
word: C¹, -- 言(单字词)
phrase: C^{2..4}, -- 辞(词组)
chain: C^{2..6}, -- 链(语链)
chunk: C^{3..8}, -- 块(语块)
reading: C^{5..20}, -- 读(语读)
sentence: C^{5..50},-- 句(句子)
paragraph: C^{30..200}, -- 段(段落)
discourse: C^{200..∞} -- 篇(语篇)
}
```
3.2 线串型结构的数学表达
对于任意语言单位 u ∈ Language_Units,其线串型结构为:
Linear_Structure(u) = (c₁, c₂, ..., cₙ)
其中 cᵢ ∈ C,且满足语法约束Grammar(u) = true
线串型结构的生成函数:
Linear_Structure: Language_Units → C⁺
四、 迭加结构:层面与线串的复合模型
4.1 复合结构定义
对于任意语言单位 u,其完整结构是层面型与线串型的笛卡尔积:
Composite_Structure(u) = Layered_Structure(u) × Linear_Structure(u)
具体地,对于 u = (c₁, c₂, ..., cₙ):
Composite_Structure(u) = (Graph(c₁), Graph(c₂), ..., Graph(cₙ), Syntax(u))
其中 Syntax(u) 是 u 的句法结构树。
4.2 迭加原理的数学表述
迭加运算 ⊕ 定义为:
Layered ⊕ Linear = Composite
满足以下性质:
· 结合性: (a ⊕ b) ⊕ c = a ⊕ (b ⊕ c)
· 分配性: 对语言单位的连接运算 ·,有 (u·v) ⊕ w = (u ⊕ w)·(v ⊕ w)
五、 八类字与八类语的统一范畴论模型
5.1 范畴定义
建立汉字汉语范畴 ChineseCategory:
· 对象Ob(ChineseCategory):B ∪ R ∪ C ∪ Language_Units
· 态射Mor(ChineseCategory):包含:
· compose: B⁺ → R (笔画组合成偏旁)
· form: (R ∪ B)⁺ → C (形成汉字)
· combine: C⁺ → Language_Units (字组合成语)
· interpret: C → {S,P,M,G,E,U,I,T} (八类字解释)
· analyze: Language_Units → {word,...,discourse} (八类语分析)
5.2 函子与自然变换
八类字解释函子:
Char_Type: ChineseCategory → Set
将每个汉字映射到其八类属性的幂集:
Char_Type(c) = {s ∈ {S,P,M,G,E,U,I,T} | c 具有属性 s}
八类语分析函子:
Lang_Unit: ChineseCategory → Set
将每个语言单位映射到其所属的语类:
Lang_Unit(u) = {l ∈ {word,...,discourse} | u 属于 l 类}
六、 数据库构建模型
6.1 关系数据库模式
```sql
-- 元子表
CREATE TABLE Strokes (
stroke_id INT PRIMARY KEY,
stroke_type VARCHAR(10),
start_point POINT,
end_point POINT,
curvature FLOAT,
stroke_order INT
);
-- 元组表
CREATE TABLE Radicals (
radical_id INT PRIMARY KEY,
stroke_sequence INT[], -- 引用Strokes表
semantic_category VARCHAR(20)
);
-- 汉字表(八类属性)
CREATE TABLE Characters (
char_id INT PRIMARY KEY,
glyph VARCHAR(1),
pronunciation VARCHAR(50),
shape_id INT REFERENCES Radicals(radical_id),
semantic_value TEXT,
grammatical_function VARCHAR(20),
explanation TEXT,
usage_examples TEXT[],
symbolic_meaning TEXT,
interpretation TEXT
);
-- 语言单位表
CREATE TABLE LanguageUnits (
unit_id INT PRIMARY KEY,
unit_type VARCHAR(10), -- word, phrase, etc.
character_sequence INT[], -- 引用Characters表
syntactic_structure JSONB,
semantic_representation TEXT
);
```
6.2 范畴数据库的数学表述
范畴数据库可建模为纤维范畴:
Fib: ChineseCategory^op → Cat
对于每个汉字 c,其纤维 Fib(c) 是以 c 的所有可能解释和用法为对象的范畴。
七、 统一的形式化体系
整个汉字汉语中文的双重形式化体系可总结为以下图解:
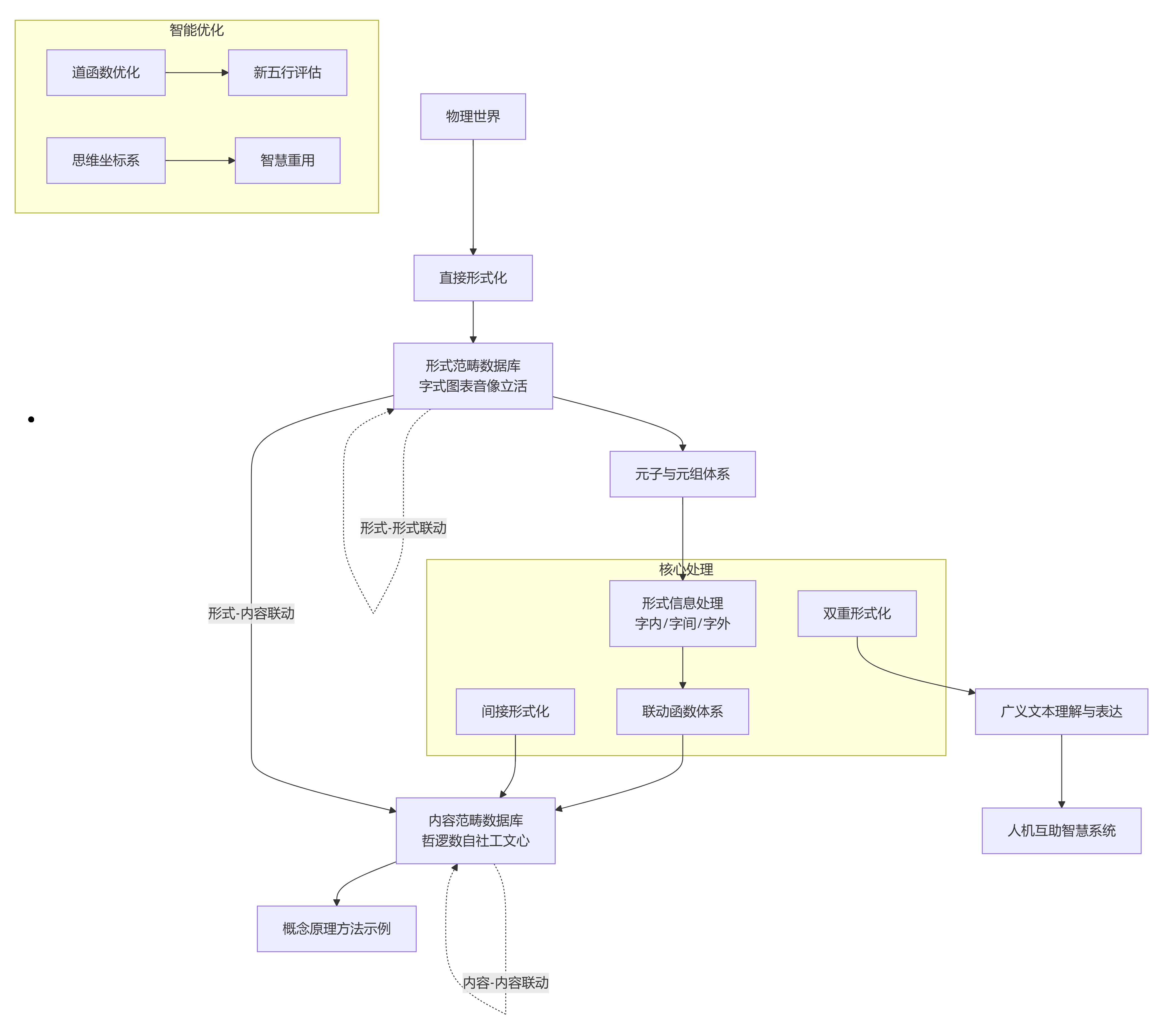
```mermaid
graph TB
A[基础笔画 B] --> B[偏旁部首 R]
B --> C[汉字 C]
C --> D[八类字属性<br>形/音/实/虚/解/用/象/释]
C --> E[语言单位 L]
E --> F[八类语层次<br>言/辞/链/块/读/句/段/篇]
G[层面型结构<br>GraphC] --> H[迭加结构<br>Composite]
I[线串型结构<br>Linear] --> H
J[关系数据库<br>存储具体数据] --> K[查询分析]
L[范畴数据库<br>存储关系与变换] --> K
H --> M[融智学双重形式化<br>完整体系]
subgraph 双重形式化
G
I
end
subgraph 数据库实现
J
L
end
```
总结:
这个数学模型为汉字汉语中文建立了完整的双重形式化体系:
1. 层面型结构精确刻画了从笔画到汉字的内部构成
2. 线串型结构系统描述了从字到篇的语言组合
3. 八类字模型提供了多维度语义分析框架
4. 八类语模型构建了层次化的语言单位体系
5. 迭加原理统一了微观字形与宏观语篇
6. 范畴论框架为整个体系提供了严格的数学基础
该模型完全可纳入融智学双重形式化体系,为实现汉字汉语中文的深度计算理解与智慧重用奠定了坚实基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号