



【数据分析】基于大信息的新能源充电安全与热失控预警分析系统 | 大数据毕设实战项目 文档指导 运行部署 选题推荐 可视化大屏 Hadoop SPark
作者:计算机毕业设计杰瑞
个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,研发项目包括大内容、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己研发中遇到的难题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
想说的话:感谢大家的关注与支持!
网站实战工程
安卓/小程序实战方案
大数据实战项目
深度学校实战项目
计算机毕业设计选题推荐
目录
基于大数据的新能源充电安全与热失控预警分析系统介绍
《基于大素材的新能源充电安全与热失控预警分析体系》是一个综合性的数据应用平台,其核心目标是利用大数据技术对新能源汽车充电过程中的海量材料进行深度分析与可视化呈现。本系统以精选的十万条模拟真实充电材料作为分析基础,技术架构上,后端采用主流且稳定的Java SpringBoot框架,确保了服务的高效与可靠;前端则通过Vue.js配合ElementUI和Echarts图表库,构建了现代化、响应式的用户交互界面与动态数据大屏。系统的灵魂在于其大数据处理能力,我们没有采用传统数据库的容易查询,而是引入了Hadoop分布式文件系统(HDFS)作为海量数据的存储基石,并利用内存计算框架Apache Spark及其强大的Spark SQL模块作为核心分析引擎。通过这套技术栈,系统能够高效处理和分析复杂的充电日志,包括电压、电流、温度等数十个指标。功能上,系统不仅具备了标准的用户管理与个人信息模块,更重要的是提供了三大核心板块:“新能源充电安全管理”模块负责展示和管理识别出的高风险充电事件;“数据分析管理”模块是后台分析任务的执行中心,能够运行我们预设的分析算法,例如识别温度异常升高、电压剧烈波动等潜在热失控前兆;而“大屏可视化”模块则将这些复杂的分析结果,以直观的图表、仪表盘和地理热力图等形式实时展现在架构首页,让管理者能够一目了然地掌握整个充电网络的安全态势,从而建立从数据采集、存储、分析到预警和可视化监控的完整闭环。
基于大数据的新能源充电安全与热失控预警分析系统演示视频
【数据分析】基于大数据的新能源充电安全与热失控预警分析系统 | 大内容毕设实战项目 文档指导 运行部署 选题推荐 可视化大屏 Hadoop SPark
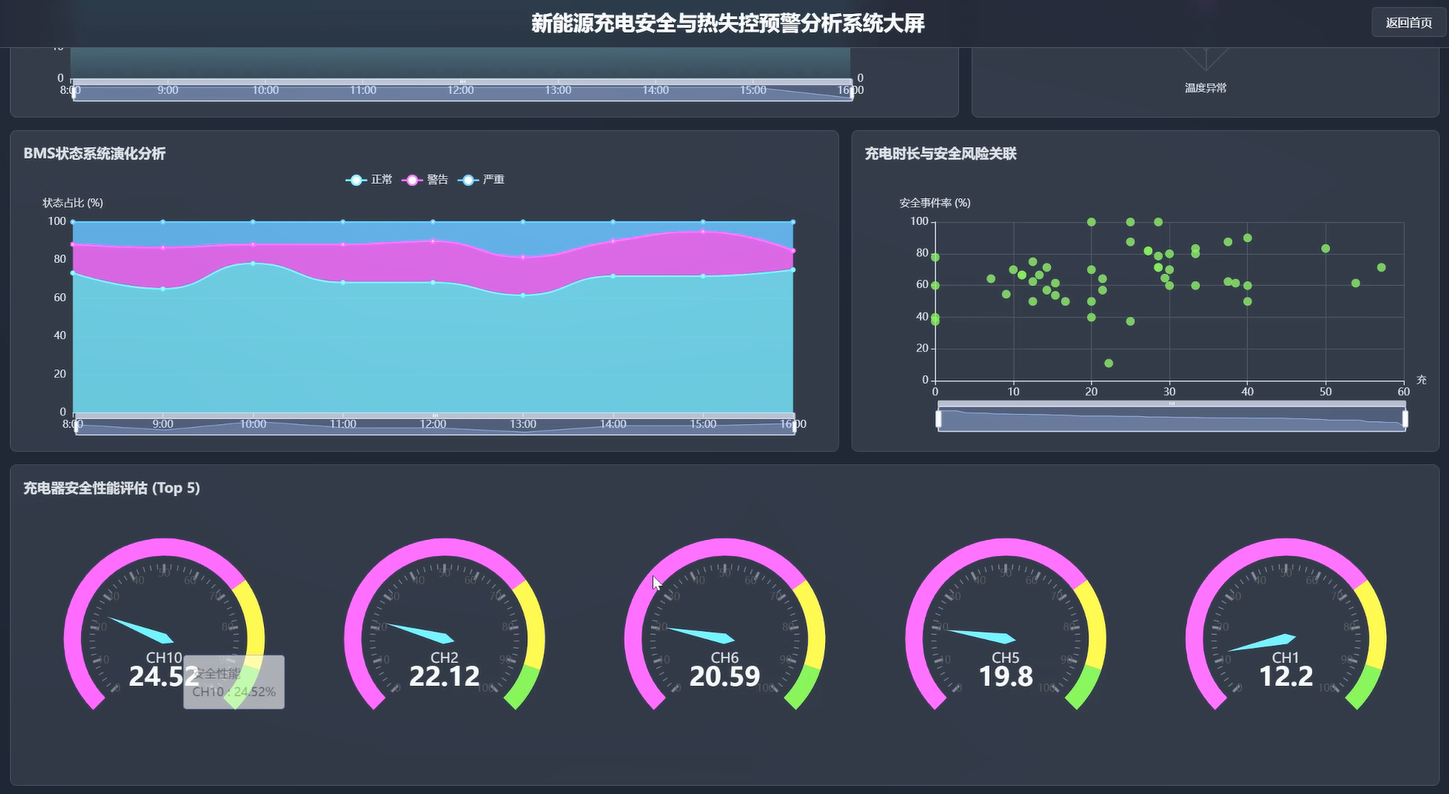
基于大信息的新能源充电安全与热失控预警分析体系演示图片







基于大数据的新能源充电安全与热失控预警分析平台代码展示
// 引入SparkSession等大数据相关工具
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
// 假设这是我们的服务类
@Service
public class ChargingDataAnalysisService {
// ① 初始化SparkSession,这是与大数据环境交互的入口
private SparkSession spark = SparkSession.builder()
.appName("NewEnergyChargingAnalysis")
.master("local[*]") // 在本地模式下运行,[*]表示使用所有可用的CPU核心
.getOrCreate();
/**
* 核心功能1:数据分析管理 - 执行热失控预警分析
* 业务逻辑:从HDFS加载数据,使用Spark SQL分析温度异常升高和电压大幅波动的充电记录。
* 温度阈值 > 80,电压波动率 > 5%
*/
public List<Row> performThermalRunawayAnalysis() {
// 从HDFS加载数据到DataFrame
Dataset<Row> chargingLogsDF = spark.read().json("hdfs://namenode:9000/data/charging_logs");
// 创建一个临时视图,以便后续使用SQL查询
chargingLogsDF.createOrReplaceTempView("charging_records");
// 编写Spark SQL查询,筛选出高风险记录
String sqlQuery = "SELECT " +
"recordId, " +
"stationId, " +
"vehicleId, " +
"timestamp, " +
"temperature, " +
"voltage, " +
"current, " +
"ROUND((voltage - lag(voltage, 1, voltage) OVER (PARTITION BY vehicleId, stationId ORDER BY timestamp)) / lag(voltage, 1, voltage) OVER (PARTITION BY vehicleId, stationId ORDER BY timestamp) * 100, 2) AS voltage_fluctuation_rate " +
"FROM charging_records " +
"WHERE temperature > 80.0";
// 执行SQL查询
Dataset<Row> highRiskBaseDF = spark.sql(sqlQuery);
// 再次筛选,找出电压波动率也满足条件的记录
Dataset<Row> finalHighRiskDF = highRiskBaseDF.filter("voltage_fluctuation_rate > 5.0");
// 将分析结果收集起来返回给Controller
List<Row> results = finalHighRiskDF.collectAsList();
// 打印部分结果以供调试
finalHighRiskDF.show();
// 在实际应用中,这里会把结果存入MySQL或直接返回
return results;
}
/**
* 核心功能2:大屏可视化 - 提供统计数据
* 业务逻辑:执行多个聚合查询,为前端Echarts大屏提供不同维度的数据。
* 包括:总告警数、各类型告警分布、充电站负载排行。
*/
public Map<String, Object> getDashboardStatistics() {
// 假设高风险表已经通过上面的分析任务生成并存储
// 这里为了演示,我们再次基于原始日志进行分析
chargingLogsDF.createOrReplaceTempView("charging_records_for_dashboard");
// 1. 查询总告警数(模拟高温告警和高压告警)
Dataset<Row> totalWarningsDF = spark.sql("SELECT COUNT(*) as total_warnings FROM charging_records_for_dashboard WHERE temperature > 80 OR voltage > 450");
long totalWarnings = totalWarningsDF.first().getLong(0);
// 2. 查询各类型告警分布
String warningTypeSql = "SELECT " +
"CASE " +
"WHEN temperature > 80 AND voltage <= 450 THEN 'High Temperature' " +
"WHEN temperature <= 80 AND voltage > 450 THEN 'High Voltage' " +
"WHEN temperature > 80 AND voltage > 450 THEN 'High Temp & Voltage' " +
"END AS warning_type, " +
"COUNT(*) as count " +
"FROM charging_records_for_dashboard " +
"WHERE temperature > 80 OR voltage > 450 " +
"GROUP BY warning_type";
Dataset<Row> warningTypeDF = spark.sql(warningTypeSql);
List<Row> warningTypeDistribution = warningTypeDF.collectAsList();
// 3. 充电站使用次数排行TOP 5
Dataset<Row> stationLoadDF = spark.sql("SELECT stationId, COUNT(DISTINCT recordId) as session_count FROM charging_records_for_dashboard GROUP BY stationId ORDER BY session_count DESC LIMIT 5");
List<Row> stationLoadRanking = stationLoadDF.collectAsList();
// 将所有结果封装到一个Map中返回给前端
Map<String, Object> dashboardData = new java.util.HashMap<>();
dashboardData.put("totalWarnings", totalWarnings);
dashboardData.put("warningTypeDistribution", warningTypeDistribution);
dashboardData.put("stationLoadRanking", stationLoadRanking);
return dashboardData;
}
/**
* 核心功能3:新能源充电安全管理 - 分页查询高风险事件列表
* 业务逻辑:根据前端传来的分页参数,查询已识别出的高风险事件列表。
* 这里演示直接使用DataFrame API进行筛选和排序。
*/
public List<Row> getHighRiskChargingEvents(int pageNum, int pageSize) {
// 使用DataFrame API进行操作
Dataset<Row> allLogsDF = spark.read().json("hdfs://namenode:9000/data/charging_logs");
// 定义筛选条件
Dataset<Row> filteredDF = allLogsDF.filter("temperature > 80 OR voltage > 450 OR current < 0");
// 按时间戳降序排序
Dataset<Row> sortedDF = filteredDF.orderBy(org.apache.spark.sql.functions.col("timestamp").desc());
// 计算偏移量
int offset = (pageNum - 1) * pageSize;
// 这里Spark没有直接的offset,我们通过收集后在Java中处理分页
// 或者使用更高级的技巧如 `limit(offset + pageSize)` 然后再处理
// 为简化演示,我们加载一个子集
// 在真实分布式环境中,应避免`collectAsList`整个大数据集
// 更优的做法是先limit,或者将结果写入支持分页的数据库如MySQL
// 此处为模拟分页效果
List<Row> allHighRiskEvents = sortedDF.collectAsList();
int fromIndex = Math.min(offset, allHighRiskEvents.size());
int toIndex = Math.min(offset + pageSize, allHighRiskEvents.size());
if(fromIndex > toIndex) {
return new java.util.ArrayList<>();
}
return allHighRiskEvents.subList(fromIndex, toIndex);
}
}基于大数据的新能源充电安全与热失控预警分析架构文档展示

作者:计算机毕业设计杰瑞
个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小代码、Python、Golang、安卓Android等,开发项目包括大资料、深度学习、网站、小脚本、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己研发中遇到的困难的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
想说的话:感谢大家的关注与拥护!
网站实战项目
安卓/小工具实战计划
大材料实战项目
深度学校实战项目
计算机毕业设计选题推荐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号