

【问题4】:kaggle练习题《自行车租赁业务预测》--带数据分析,用了随机森林,支持向量机,岭回归等本次就分析到这里
第一步:读取数据 并对数据进行分析
import numpy as np
import pandas as pd
df_train = pd.read_csv('data/kaggle_bike_competition_train.csv')
print(df_train.head())
print(df_train.shape)
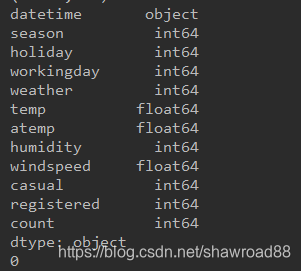
print(df_train.dtypes) # 看一下各字段类型
# 看时候有缺失值
print(df_train.isnull().sum().sum()) # 输出为0,表示没有缺失值
[/code]
读取出来的数据 下面这个表columns名与数据错一位。 datetime对应的是日期那一列,第一列是序号。
datetime | season | holiday | workingday | weather | temp | atemp
| humidity | windspeed | casual | registered | count
---|---|---|---|---|---|---|---|---|---|---|---
0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81
| 0.0000 | 3 | 13 | 16
1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80
| 0.0000 | 8 | 32 | 40
2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80
| 0.0000 | 5 | 27 | 32
3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75
| 0.0000 | 3 | 10 | 13
4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75
| 0.0000 | 0 | 1 | 1
从上面得出了各字段的类型,并且得出没有缺失值。。。因为最后一行代码输出为0.
### **第二步:处理一些字段 如:datetime那一列。**
```code
# 把月,日和小时单独拎出来,搞成三列
df_train['month'] = pd.DatetimeIndex(df_train.datetime).month
df_train['day'] = pd.DatetimeIndex(df_train.datetime).dayofweek
df_train['hour'] = pd.DatetimeIndex(df_train.datetime).hour
# print(df_train.head())
# 那个,既然时间大串已经被我们处理过了,那这个字段放着太占地方,干脆就不要了吧
# 先上一个粗暴的版本,咱们把注册租户和未注册租户也先丢掉,回头咱们再看另外一种处理方式
# 保险起见,保存一下刚才处理的数据
df_train_origin = df_train
# 删除掉不需要的字段
df_train = df_train.drop(['datetime', 'casual', 'registered'], axis=1)
# print(df_train.head()) # 查看处理后的数据
# print(df_train.shape) # 显然列变为了12
# 开始分数据 count是标签
df_train_target = df_train['count'].values
df_train_data = df_train.drop(['count'], axis=1).values
[/code]
这一步我们将日期拆开,分别增加三列:month, day, hour。 并且把注册租户和未注册租户以及原先datetime列删除 。。防止他们干扰。
最后得出 特征值和标签值。
### **第三步:模型走起**
_**1. 岭回归** _
```code
print("岭回归\n")
kfold = KFold(n_splits=3, shuffle=True, random_state=42)
for train, test in kfold.split(df_train_data):
clf = Ridge()
clf.fit(df_train_data[train], df_train_target[train])
print("训练集准确率:{},测试集准确率:{}".format(
clf.score(df_train_data[train], df_train_target[train]),
clf.score(df_train_data[test], df_train_target[test])
))
[/code]
先进行3折交叉验证,然后用岭回归进行训练。 最后得出的结果很尴尬

**_2.支持向量机模型_ **
```code
print("支持向量机\n")
for train, test in kfold.split(df_train_data):
clf = SVR(kernel='rbf', C=10, gamma=0.001)
clf.fit(df_train_data[train], df_train_target[train])
print("训练集准确率:{},测试集准确率:{}".format(
clf.score(df_train_data[train], df_train_target[train]),
clf.score(df_train_data[test], df_train_target[test])
))
[/code]
结果:

这个结果也挺尴尬 。 支持向量机曾几何时也是神器。
**_3.随机森林_ **
```code
print("随机森林\n")
for train, test in kfold.split(df_train_data):
clf = RandomForestRegressor(n_estimators=80)
clf.fit(df_train_data[train], df_train_target[train])
print("训练集准确率:{},测试集准确率:{}".format(
clf.score(df_train_data[train], df_train_target[train]),
clf.score(df_train_data[test], df_train_target[test])
))
[/code]
结果还是不错的。

**_4.用网格搜索给随机森林找一组参数,然后在用随机森林预测_ **
```code
x_train, x_test, y_train, y_test = train_test_split(df_train_data, df_train_target, test_size=0.2, random_state=42)
params = {"n_estimators": [30, 60, 90]}
scores = ['r2']
for score in scores:
print(score)
clf = GridSearchCV(RandomForestRegressor(), params, cv=5, scoring=score)
clf.fit(x_train, y_train)
print(clf.best_estimator_)
[/code]
找到了一组合适的参数。如下

我们用这组参数再次进行随机森林预测
```code
print("随机森林\n")
for train, test in kfold.split(df_train_data):
clf = RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=90, n_jobs=None,
oob_score=False, random_state=None, verbose=0, warm_start=False)
clf.fit(df_train_data[train], df_train_target[train])
print("训练集准确率:{},测试集准确率:{}".format(
clf.score(df_train_data[train], df_train_target[train]),
clf.score(df_train_data[test], df_train_target[test])
))

附加: 走一波数据分析
画出几个特征与流通量的关系
# 风速与流通量
df_train_origin.groupby('windspeed').mean().plot(y='count', marker='o')
plt.show()
# 湿度与流通量
df_train_origin.groupby('humidity').mean().plot(y='count', marker='o')
plt.show()
# 温度与流通量
df_train_origin.groupby('temp').mean().plot(y='count', marker='o')
plt.show()
# 温度湿度变化
df_train_origin.plot(x='temp', y='humidity', kind='scatter')
plt.show()
[/code]

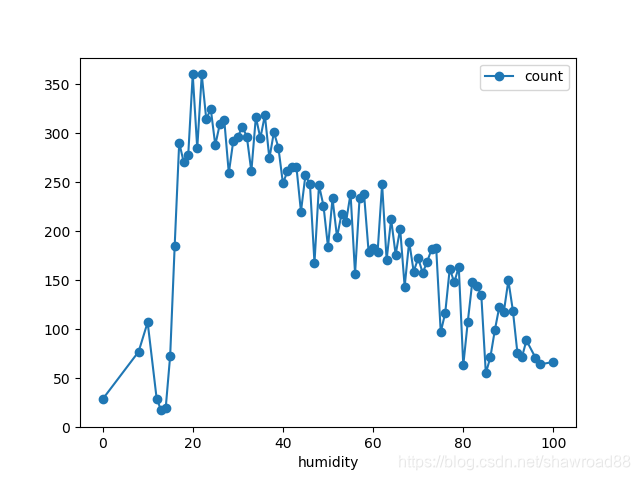
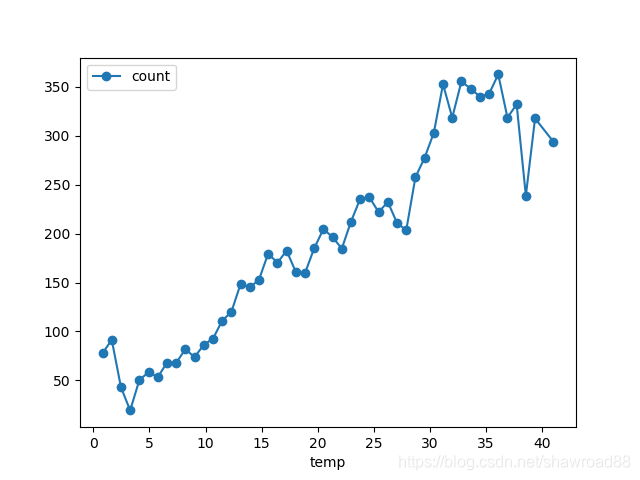
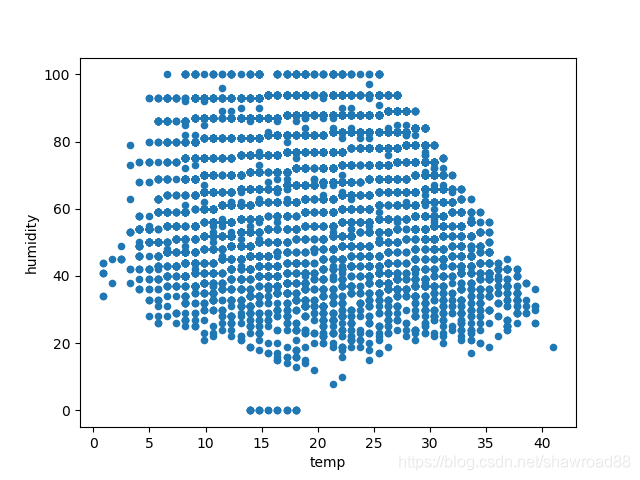
画出各个维度与count的关系
```code
fig, axs = plt.subplots(nrows=2, ncols=3)
df_train_origin.plot(kind='scatter', x='temp', y='count', ax=axs[0, 0], figsize=(16, 8), color='magenta')
df_train_origin.plot(kind='scatter', x='atemp', y='count', ax=axs[0, 1], color='cyan')
df_train_origin.plot(kind='scatter', x='humidity', y='count', ax=axs[0, 2], color='red')
df_train_origin.plot(kind='scatter', x='windspeed', y='count', ax=axs[1, 0], color='yellow')
df_train_origin.plot(kind='scatter', x='month', y='count', ax=axs[1, 1], color='blue')
df_train_origin.plot(kind='scatter', x='hour', y='count', ax=axs[1, 2], color='green')
plt.show()
[/code]
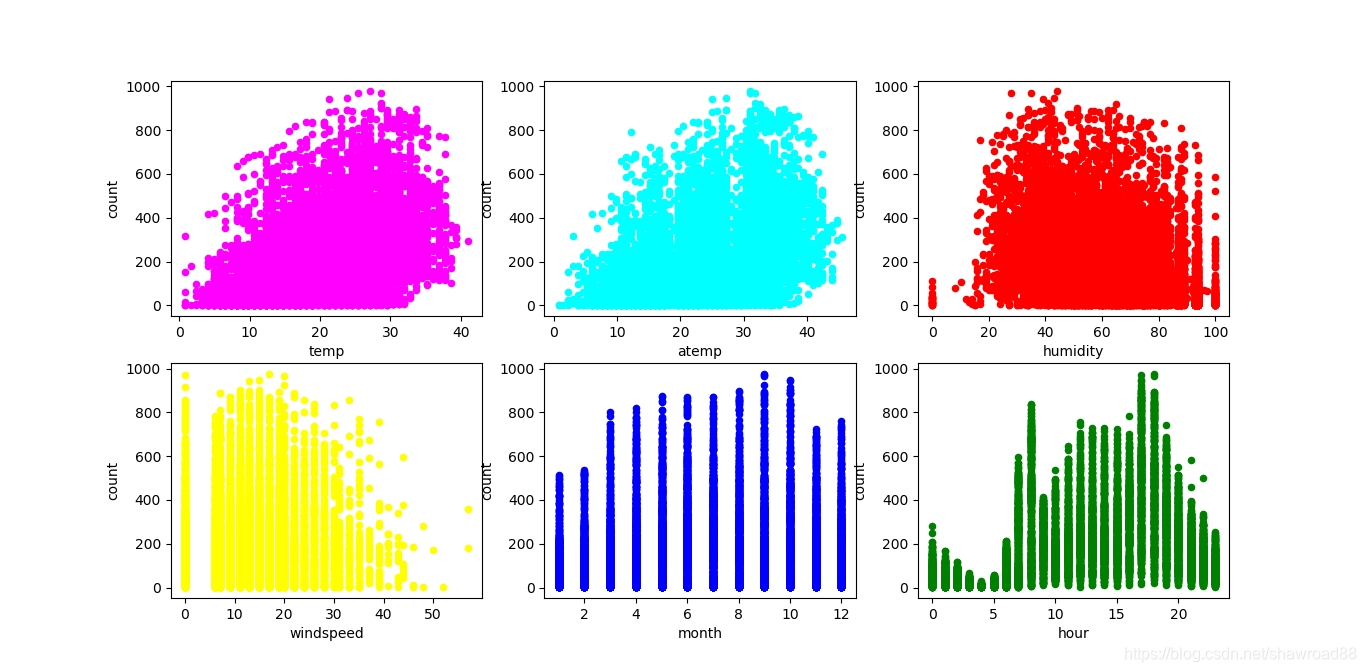
画出各个特征之间的相关性
```code
corr = df_train_origin[['temp', 'weather', 'windspeed', 'day', 'month', 'hour', 'count']].corr()
print(corr)
# 用颜色深浅来表示相关度
plt.matshow(corr)
plt.colorbar()
plt.show()
[/code]
相关性矩阵 带负号表示负相关
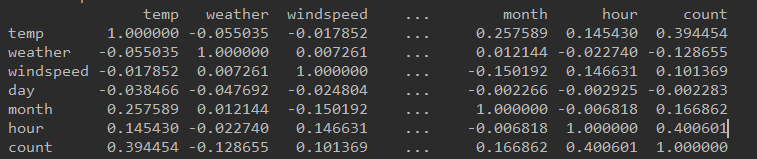
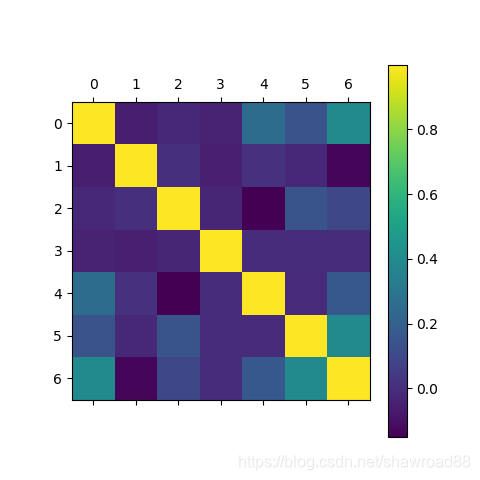
由上向下,相关性一次减小。。
# 本次就分析到这里 。。。未完待续 连载中。。。。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号