
【Python数据分析】文本情感分析——电影评论分析(二)文本向量化建立模型总结与改进方向
目录
-
文本向量化
-
-
词袋模型
-
TF-IDF
-
-
建立模型
-
-
构建训练集与测试集
-
特征选择
-
-
方差分析
-
-
逻辑回归
-
朴素贝叶斯
-
-
总结与改进方向
-
-
总结
-
改进
-
文本向量化
文本要进行模型训练,进而判断文本是积极的还是消极,而此时的文本依然是字符串形式,机器学习只能进行数值类型数据的计算,不能完成非数值类型的计算。所以需要把文本转化成数值类型,才能让模型训练学习,而把文本转化为数值的形式就是 文本向量化 。 文本向量化的步骤: 1、文本分词,拆分成更容易处理的单词。 2、将单词转换为数值类型,即用合适的数值来表示每个单词。
词袋模型
词袋模型是一种能将文本向量化的方式。在词袋模型中,每个文档为一个样本,在这个例子中每条评论就是一个样本,每个不重复的单词为一个特征,而单词在文档中出现的次数就作为该特征的特征值。
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
docs = {
"Today is Sunday,it is a fine day.",
"Good Good Study,Day Day Up."
}
bag = count.fit_transform(docs)
#输出的bag是一个稀疏矩阵
print(bag)
#将稀疏矩阵转换为稠密矩阵
print(bag.toarray())
#获取每个特征对应的单词
print(count.get_feature_names())
# 输出单词与编号的对应关系
print(count.vocabulary_)
结果: 
Countvectorizer只会对字符长度不小于2的单词进行处理,如果单词就一个字符,这个单词就会被忽略。 注意 ,经过训练后,CountVectorizer就可以对测试集文件进行向量化了,但是向量化出来的特征只是训练集出现的单词特征,如果测试集出现了训练集中没有的单词,就无法在词袋模型中体现了。
TF-IDF
用CountVectorizer类可以进行文档向量化出来,在向量化过程中将单词的频数作为特征取值,频数越大就认为这个单词越重要?其实这是相对的。就好比你去找工作,期望薪资是2000元,老板给了你4000元,你很高兴的接受了这份工作,但你第二天去上班发现,别的同事都是5000元,这时你就会觉得自己没受到重视,这是什么原因呢?因为,2000元对你自己来说你觉得很多,但是放在其他地方,2000元就不多了。同样的道理,单词的重要程度也不能仅仅从它在一个文档里出现的次数来衡量,还要考虑它在其他文档中出现的次数,如果它在其他文档中出现次数也很多,那这个单词可能就是个大众词汇,它的重要性就会大大降低了。就像每天新闻联播里出现的“中国”、“发展”这些词,频率很高啊,也不能说明它对当前文档很重要,因为这些词又没有特别有意义的信息。 TF-IDF就是用来调整单词在文档中的权重的: TF(Term-Frequency):词频,单词在文档中出现的次数。 IDF(Inverse Document——frequency):逆文档频率。 计算公式: 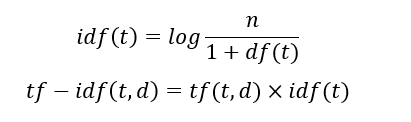 t:某个单词: n:语料库中文档的总数; df(t):语料库中含有单词t的文档个数。 scikit-learn库中的tf-idf转换与标准公式稍微不同,而且tf-idf结果会用L1或L2范数进行标准化。
t:某个单词: n:语料库中文档的总数; df(t):语料库中含有单词t的文档个数。 scikit-learn库中的tf-idf转换与标准公式稍微不同,而且tf-idf结果会用L1或L2范数进行标准化。
from sklearn.feature_extraction.text import TfidfTransformer
count = CountVectorizer()
docs = {
"Where there is a river,there is a city.",
"There is no royal road to learning"
}
bag = count.fit_transform(docs)
tfidf = TfidfTransformer()
t = tfidf.fit_transform(bag)
print(t.toarray())
结果:  scikit-learn中的TfidfVectorizer类可以直接将文档转换为TF- IDF值,这个类相当于继承了CountVectorizer与TfidTransformer两个类的功能。
scikit-learn中的TfidfVectorizer类可以直接将文档转换为TF- IDF值,这个类相当于继承了CountVectorizer与TfidTransformer两个类的功能。
from sklearn.feature_extraction.text import TfidfVectorizer
docs = {
"Where there is a river,there is a city.",
"There is no royal road to learning"
}
tfidf = TfidfVectorizer()
t = tfidf.fit_transform(docs)
print(t.toarray())
结果:  两种方法的值是一样的。
两种方法的值是一样的。
建立模型
构建训练集与测试集
#目前词汇是以列表类型呈现的,因为文本向量化需要传递空格分开的字符串数组类型,现在需要将每条评论的词汇组合在一起,成为字符串类型,用空格隔开。
def join(text_list):
return " ".join(text_list)
data['comment'] = data['comment'].apply(join)
结果:  构造目标列,好评为2,中评为1,差评为0
构造目标列,好评为2,中评为1,差评为0
data['target'] = np.where(data['score'] >=4.5, 2,np.where(data['score'] >=3,1,0))
data['target'].value_counts()
结果:  可以看出,样本分布悬殊大,好评数与其他两个评论的数量不在一个数量级。 对于样本分布不均衡,可采用上采样、下采样、混合采样等方法,这里用下采样的方式。
可以看出,样本分布悬殊大,好评数与其他两个评论的数量不在一个数量级。 对于样本分布不均衡,可采用上采样、下采样、混合采样等方法,这里用下采样的方式。
p = data[data['target'] == 2]
m = data[data['target'] == 1]
n = data[data['target'] == 0]
p = p.sample(len(m))
m = m.sample(len(m))
data2 = pd.concat([p,m,n],axis=0)
data2['target'].value_counts()
结果:  构建训练集和测试集。
构建训练集和测试集。
from sklearn.model_selection import train_test_split
X = data2['comment']
y = data2['target']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25)
print('训练集样本数:',X_train.shape[0],'测试集样本数',X_test.shape[0])
结果: 
特征选择
vec = TfidfVectorizer(ngram_range=(1,2),max_df=0.5,min_df=1)
X_train_trans = vec.fit_transform(X_train)
X_test_trans = vec.fit_transform(X_test)
display(X_train_trans,X_test_trans)
结果:总共有21.36万个特征。 ngram_range:考虑一个词和两个词的顺序,即两个连着的词也会统计考虑,比如“武松打虎”和“虎打武松”,两句话语义完全相反但向量化都是一样的结果即“武松”、“打”、“虎”,此时需要考虑词的顺序,即“武松”、“打”、“武松打”、“虎”、“打虎”都会被考虑。据经验,考虑3个连词和2个连词的效果差不多,但是取3个连词的特征量会比取2个连词的多得多; max_df:含有某个单词的最大文档数百分比,如果大于这个频率,这个词就不要了,就是删除太大众化的词; min_df:含有某个单词的最小文档数,如果小于这个数,这个词就不要了,就是删除太小众化的词。
方差分析
并不是所有的特征都对建模有帮助,所以在建模前要进行特征选择。这里用 方差分析-ANOVA 来进行特征选择,选择与目标分类变量最相关的2万个特征。 方差分析是用来分析两个或多个样本(来自不同总体)的均值是否相等,进而可以检验分类变量与联系变量之间是否相关。根据分类变量的不同取值将样本分组,计算组内差异(SSE)和组间差异(SSM)。 F统计量: 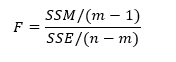 m:组的数量;n:观测值的数量。 组内差异来自采样的影响,组间差异来自采样影响和分组影响。所以,组间差异大于等于组内差异。如果不同的类别,没有影响到同一个单词的特征值不同,那就意味着组间差异几乎是没有的,此时的F值近似于1;如果组间差异很大,F值就大于1,组间差异越大,F值越大于1。所以F的值就能表示一个单词在不同组中的影响 该统计量服从自由度为(m-1,n-m)的F分布,F检验的原假设为各种均值相等,备择假设为至少存在两组数据均值不相等。 均值相等,即这个单词在每个分组表现得都差不多,也就是这个单词对分类没影响。
m:组的数量;n:观测值的数量。 组内差异来自采样的影响,组间差异来自采样影响和分组影响。所以,组间差异大于等于组内差异。如果不同的类别,没有影响到同一个单词的特征值不同,那就意味着组间差异几乎是没有的,此时的F值近似于1;如果组间差异很大,F值就大于1,组间差异越大,F值越大于1。所以F的值就能表示一个单词在不同组中的影响 该统计量服从自由度为(m-1,n-m)的F分布,F检验的原假设为各种均值相等,备择假设为至少存在两组数据均值不相等。 均值相等,即这个单词在每个分组表现得都差不多,也就是这个单词对分类没影响。
from sklearn.feature_selection import f_classif
#根据y进行分组,计算X中每个特征的F值和P值,F值越大,P越小
f_classif(X_train_trans,y_train)
结果:F值越大,P值越小  需要选取影响最大的20000万特征
需要选取影响最大的20000万特征
from sklearn.feature_selection import SelectKBest
#tf-idf值精度不用太高,使用32位的浮点数表示,节省存储空间
X_train_trans = X_train_trans.astype(np.float32)
X_test_trans = X_test_trans.astype(np.float32)
#定义特征选择器,用来选择最好的k个特征
selector = SelectKBest(f_classif,k=min(20000,X_train_trans.shape[1]))
selector.fit(X_train_trans,y_train)
#对训练集和测试集进行特征选择
X_train_trans = selector.transform(X_train_trans)
selector.fit(X_test_trans,y_test)
X_test_trans = selector.transform(X_test_trans)
print(X_train_trans.shape,X_test_trans.shape)
结果:(59294, 20000) (19765, 20000)
逻辑回归
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
lr = LogisticRegression(class_weight='balanced',multi_class='ovr',solver='sag')
lr.fit(X_train_trans,y_train)
y_hat = lr.predict(X_test_trans)
print(classification_report(y_test,y_hat))
由于样本并不那么均衡,用balanced调节权重,根据样本数量调节权重,数量越多权重越小。 优化方式选择平均梯度下降的方式。
结果: 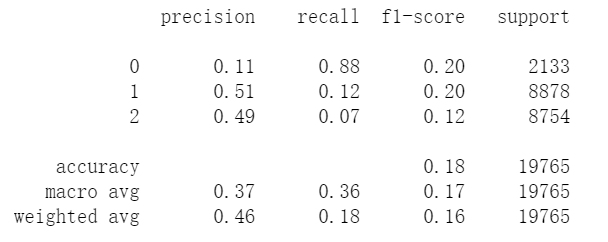
朴素贝叶斯
from sklearn.naive_bayes import ComplementNB
gnb = ComplementNB()
gnb.fit(X_train_trans,y_train)
y_hat = gnb.predict(X_test_trans)
print(classification_report(y_test,y_hat))
结果: 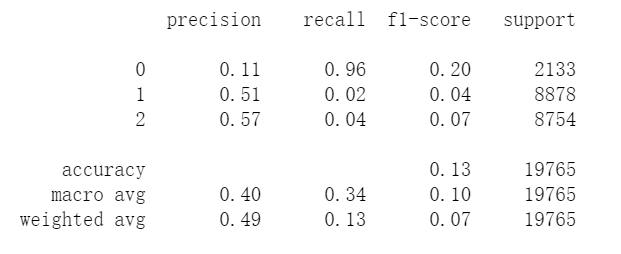
总结与改进方向
总结
这两篇博文主要总结了文本数据预处理方法,个性化词云图的生成,文本向量化,利用方差分析实现特征值的选择。选择的两种模型效果都不好。
改进
选择的两种方法结果都差不多,效果都不好,不知道是预处理没做好还是特征选择没做好,如果前面都没错,是模型问题的话,可以从以下几个方向改进: 1.调整算法中的超参数。 2.尝试其他分类算法。 3.用其他方式来应对样本不均衡问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号