“G”术时刻:南大通用GBase 8a 数据库数据分布策略
南大通用GBase 8a MPP Cluster数据库集群中的表分为分布表和复制表。
1、复制表在所有节点上进行存储,且所有节点上的数据一致。以下是复制表的数据存放的示意图:

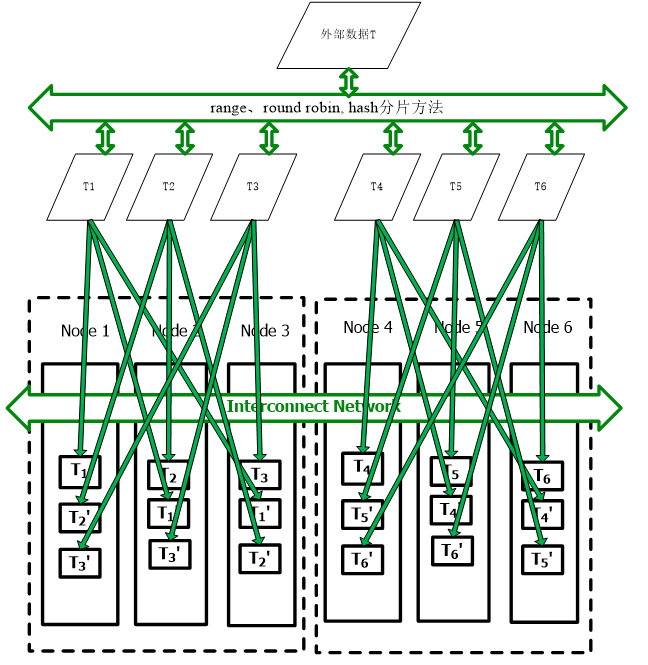
2、分布表的数据进行分片存储,采用(range、round robin, hash)等不同方式把数据进行拆分,拆分完毕后把数据存储到各个节点上,为了保证数据的高可用,分片后的数据也进行冗余的备份存储。例如T数据被分片成T1、T2,T3备份数据分别为T1'、T2',T3',每一个节点同时存储了另两个节点分片数据的备份数据。
分布表的数据存放示意图如下:
分布表通常采用hash的方法进行数据分片,故hash分布键选择的是否合理,将直接影响MPP数据库的性能表现,在选择表的分布策略时,需要重点考虑以下问题(问题由重要程度由高到低列出):
1、均匀的数据分布 -- 为了尽可能达到最好的性能,所有的数据节点应该尽量存储等量的数据。若数据的分布不平衡或倾斜,那些存储了较多数据的节点在处理自己那部分数据时将需要耗费更多的工作量。为了实现数据的均匀分布,尽量选取具有唯一性的分布键。但往往有很多表没有唯一键,那么尽量选择数据分布规律性强且取值范围非常大的字段作为分布键。
2、本地操作与分布式操作 -- 在处理查询时,很多处理如join、分组聚合等,若能够在节点本地完成,其效率将远高于跨节点(需要在各节点间交叉传输数据)的操作。当不同的表使用相同的分布键时,在分布键上的join或分组操作将会以最高效的方式在本地完成。如果采用随机分布策略,将大大限制本地操作的可能。所以在实际的使用中,如果一个字段被大量的join使用的话,建议以该字段作为分布键。
3、平坦的查询处理 -- 在查询正被处理时,我们希望所有的节点都能处理等量的工作负载,从而尽可能达到最好的性能。有时候查询场景与数据分布策略很不吻合,这就会导致工作负载的倾斜。例如,有一张销售交易表,该表的分布键为公司名称,那么数据分布的Hash算法将基于公司名称的值来计算,假如有一个查询以某个特定的公司名称作为查询条件,该查询任务将仅在一个节点上执行,其他节点处于闲置状态。工作负载倾斜就是如此发生的。
除此之外,还有一种数据倾斜的原因是由于数据本身分布不均衡导致的,比如按照号码的哈希做分布,如果某些号段的数据记录数本身就比较多,就会产生数据的倾斜,相应的计算也会产生倾斜。
在具体模型设计阶段,建议按照如下的原则选择HASH分布键:
* 选择某数据列随机性很大的字段,如phone_no,subs_id,account_id等,一般不建议将statis_date,area_code等作为分布键
* 建议经常用于表关联的字段作为分布键,将经常关联的表的分布键设计为一致。以减少数据关联时分布键不一致导致的某张表数据的重分布。分布键字段类型建议保持一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号