
面向可维护性的构造技术学习概要(下)
Outline:
1.软件维护和演化;
2.维护性中的准则;
3.模块化设计及其准则;
4.OO设计准则:SOLID;
5.基于语法的构建;
2022-06-03 13:38:36
4.OO设计准则:SOLID
SOLID是指五个针对类的设计原则:
▪ (SRP) The Single Responsibility Principle 单一责任原则
▪ (OCP) The Open-Closed Principle 开放-封闭原则
▪ (LSP) The Liskov Substitution Principle Liskov替换原则
▪ (DIP) The Dependency Inversion Principle 依赖转置原则
▪ (ISP) The Interface Segregation Principle 接口聚合原则
- 单一责任原则(SRP):ADT中不应该有多于1个原因让其发生变化,否则就拆分开。责任即变化的原因,一个类只能有一个责任,这是最简单的原则却也是最难做到的原则。一般而言,我们编写程序时先写好框架,先满足高内聚低耦合的条件,再去查看一个类中是否只有一个责任,不是的话再去拆分开。而不是一开始就去将类进行拆分,因为实际上我们不知道哪些方法是会再次发生改变的,所以为了避免多此一举,编写完之后再去拆分是一个不错的选择。这里给出一个拆分的例子:
![]()
- 开放-封闭原则(OCP):对扩展性的开放,对修改的封闭。前者是指模块的行为应是可扩展的,从而该模块可表现出新的行为以满足需求的变化;后者则是指模块自身的代码是不应被修改的,扩展模块行为的一般途径是修改模块的内部实现,如果一个模块不能被修改,那么它通常被认为是具有固定的行为。对于这个原则,一般的实现的方法是抽象技术。举一个例子:
![]()
这里的画图方法对于不同的图形定义了不同的方法,并且采取了分支逻辑判断,给人的感觉很冗余。对其进行修改如下:
![]()
此时将图形抽象出来,形成一个抽象类,并且内置一个抽象的画图方法,不同的图形只需继承它并且实现自己独特的画图方法即可,最终画图的调用委托给GraphicEditor来做。
- Liskov替换原则(LSP):子类型必须能够替换其基类型,意即派生类必须 能够通过其基类的接口使用,客户端无需了解二者之间的差异。具体内容非常丰富,简要概述一下:子类型可以增加方法但是不能删除,子类型需要实现抽象类型中的所有未实现的方法,子类型中重写的方法的返回值是协变(co-variant)的,但参数是逆变(contra-variant)的(现在Java中一般视其为重载),子类型中重写的方法不能抛出额外的异常(协变的异常),更强的不变量、更弱的前置条件、更强的后置条件。更具体的内容属于面向复用的构造,此处不再赘述。
- 接口隔离原则(ISP):不能强迫客户端依赖于它们不需要的接口,只提供必需的接口,避免接口污染,避免胖接口。意即客户端不需要的接口就不要让他们继承、实现,我们应当使客户能够选择自己想要的。一个较为清晰的示意图如下:
![]() 我们不要将所有方法整合到一个接口中,将其根据功能划分为不同的等价类接口,这样不仅能使客户避免了继承自己不需要的接口,还能提高聚合度。举个例子:
我们不要将所有方法整合到一个接口中,将其根据功能划分为不同的等价类接口,这样不仅能使客户避免了继承自己不需要的接口,还能提高聚合度。举个例子:![]()
worker接口有工作和吃饭两个方法,但是子类RobotWorker不需要吃饭这个方法,引入了子类不需要的方法,有时候会带来很不好的影响。修改后如下:
![]()



 我们不要将所有方法整合到一个接口中,将其根据功能划分为不同的等价类接口,这样不仅能使客户避免了继承自己不需要的接口,还能提高聚合度。举个例子:
我们不要将所有方法整合到一个接口中,将其根据功能划分为不同的等价类接口,这样不仅能使客户避免了继承自己不需要的接口,还能提高聚合度。举个例子:

依赖转置原则(DIP):高层模块不应该依赖于低层模块,二者都应该依赖于抽象;抽象不应该依赖于实现细节,实现细节应该依赖于抽象 。一般可以通过委托(Delegation)来实现。一个例子如下: ,通过使用接口组合或聚合的方法,实现委托,就可以实现依赖转置,使得高层模块不会因底层模块的变动而变动,使得代码编写更易于维护。一个示意图:
,通过使用接口组合或聚合的方法,实现委托,就可以实现依赖转置,使得高层模块不会因底层模块的变动而变动,使得代码编写更易于维护。一个示意图: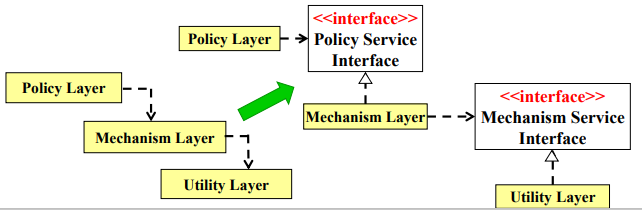
小结:OO设计的两大武器
抽象(abstraction):模块之间通过抽象隔离开来,将稳定部分和容易 变化部分分开
LSP:对外界看来,父类和子类是“一样”的;
DIP:对接口编程,而不是对实现编程,通过抽象接口隔离变化;
OCP:当需要变化时,通过扩展隐藏在接口之后的子类加以完成,而不要修 改接口本身。
分离(Separation): Keep It Simple, Stupid (KISS)
SRP:按责任将大类拆分为多个小类,每个类完成单一职责,规避变化,提 高复用度;
ISP:将接口拆分为多个小接口,规避不必要的耦合。
归纳起来:让类保持责任单一、接口稳定。
5.基于语法的构建
有一类应用,从外部读取文本数据, 在应用中做进一步处理。例如:从网络上传输过来的消息,遵循特定的协议,或者用户在命令行输入的指令,遵循特定的格式。这就要求我们使用grammar判断字符串是否合法,并解析成程序里使用的数据结构。一般使用正则表达式来判断一个字符串是否合乎规定的语法结构。
有关语法分析树、终止节点、叶结点、终止符、产生式、非产生式等的概念不再赘述,这些都是在形式语言中出现的常见概念,不过有一点需要提出,这里的选择运算符并非加号“+”,而是符号“|”。一个简单的例子: 这个正则表达式代表的是形如“http://bilibili.com/”这样的URL。上例中的word也可以简写为[a-z]。还有一些常见的运算符:?、*、+。
这个正则表达式代表的是形如“http://bilibili.com/”这样的URL。上例中的word也可以简写为[a-z]。还有一些常见的运算符:?、*、+。
语法分析树的一个例子: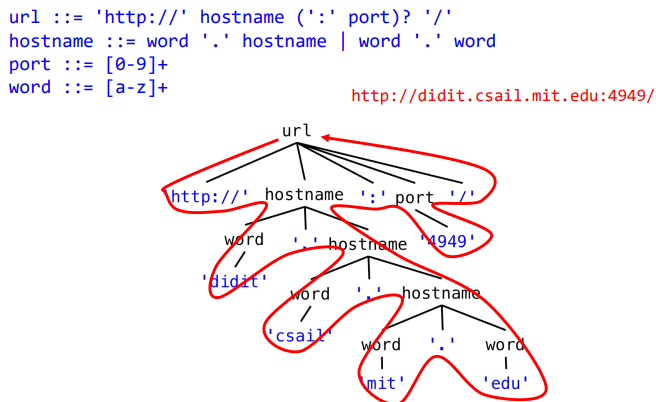 采用了递归的形式。
采用了递归的形式。
HTML的语法为: 即形式为“text <i> text </i>”这种,他是上下文无关的文法。支持标记的嵌套。
即形式为“text <i> text </i>”这种,他是上下文无关的文法。支持标记的嵌套。
Markdown语法为: 即形式为“text _ text _”这种,他是正则的。不支持标记的嵌套。
即形式为“text _ text _”这种,他是正则的。不支持标记的嵌套。
关于Parser和Parser Generator: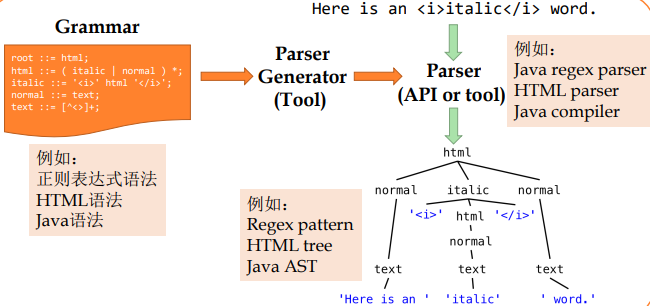 Grammar定义语法规则(BNF格式的文本),Parser Generator根据语法规则产生一个Parser,用户利用parser来解析文本,看其是否符合语法定义并对其做各种处理(例如转成parse tree)。
Grammar定义语法规则(BNF格式的文本),Parser Generator根据语法规则产生一个Parser,用户利用parser来解析文本,看其是否符合语法定义并对其做各种处理(例如转成parse tree)。
Java中你可能会碰到的一些正则表达式的表达方式:

匹配器的三种匹配方式:
- Greedy : 匹配器被强制要求第一次尝试匹配时读入整个输入串,如果第一次尝试匹配失败,则从后往前逐个字符地回退并尝试再次匹配,直到匹配成功或没有字符可回退。
- Reluctant:从输入串的首(字符)位置开始,在一次尝试匹配查找中只勉强地读一个字符,直到尝试完整个字符串。
- Possessive: 直接匹配整个字符串,如果完全匹配就匹配成功,否则匹配失败。效果相当于equals()。
举个例子: 此处的“.”代表任意单个字符,所以“.*foo”代表形如xxxfoo的字符串,xxx可为空串,也可为一堆任意的字符。所以贪婪匹配得到的便是整个字符串,因为他是先整个读取若不匹配再从最后回退。同理勉强匹配得到的是两个字符串,因为他是一个个读取直到匹配,待到读完整个字符串便返回。对于独占匹配,它直接将整个字符串和给定形式匹配,这里正则表达式能代表的字符串前缀是任意的,而给定的字符串前缀是确定的xfooxxxxxx,所以匹配失败。(但是对于第三个例子,将".*+foo"换为“x*+foo”,将“xfooxxxxxxfoo”换为“xxxxxxfoo”就能正确匹配了,关键还是在于“.”的类似于通配符的作用使得第三个例子返回false。)
此处的“.”代表任意单个字符,所以“.*foo”代表形如xxxfoo的字符串,xxx可为空串,也可为一堆任意的字符。所以贪婪匹配得到的便是整个字符串,因为他是先整个读取若不匹配再从最后回退。同理勉强匹配得到的是两个字符串,因为他是一个个读取直到匹配,待到读完整个字符串便返回。对于独占匹配,它直接将整个字符串和给定形式匹配,这里正则表达式能代表的字符串前缀是任意的,而给定的字符串前缀是确定的xfooxxxxxx,所以匹配失败。(但是对于第三个例子,将".*+foo"换为“x*+foo”,将“xfooxxxxxxfoo”换为“xxxxxxfoo”就能正确匹配了,关键还是在于“.”的类似于通配符的作用使得第三个例子返回false。)
界限匹配:
Java中的关于正则表达式的一些方法:
posted on 2022-06-03 16:18 GloamingBlue 阅读(52) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号