

一致性哈希组(Consistent Hashing) 算法及源码(三)一致性哈希组基于net core 的具体实现(附源码)
写在前面
一致性哈希组(Consistent Hashing) 算法及源码共分为三篇文章
(一)通过取模算法实现数据负载均衡
(二)一致性哈希组(Consistent Hashing)算法介绍
(三)一致性哈希组基于net core 的具体实现(附源码)
文章中涉及的具体架构设计及代码实现均由我们一位架构师完成,我有幸参与了其中一部分的开发和测试工作。
因架构师比较忙所以由我代为整理发布出来,希望和大家一起交流学习,逐渐完善。
通过取模和一致性哈希组实现负载均衡这两个算法分别在两个实际项目中真实用到,所以从数据安全性考虑出发只能将架构部分非业务相关的代码放到GitHub上和大家一起探讨学习。
一致性哈希组代码下载地址:https://github.com/GavinGuoweiXu/ConsistentHashing.git
主要实体UML说明:
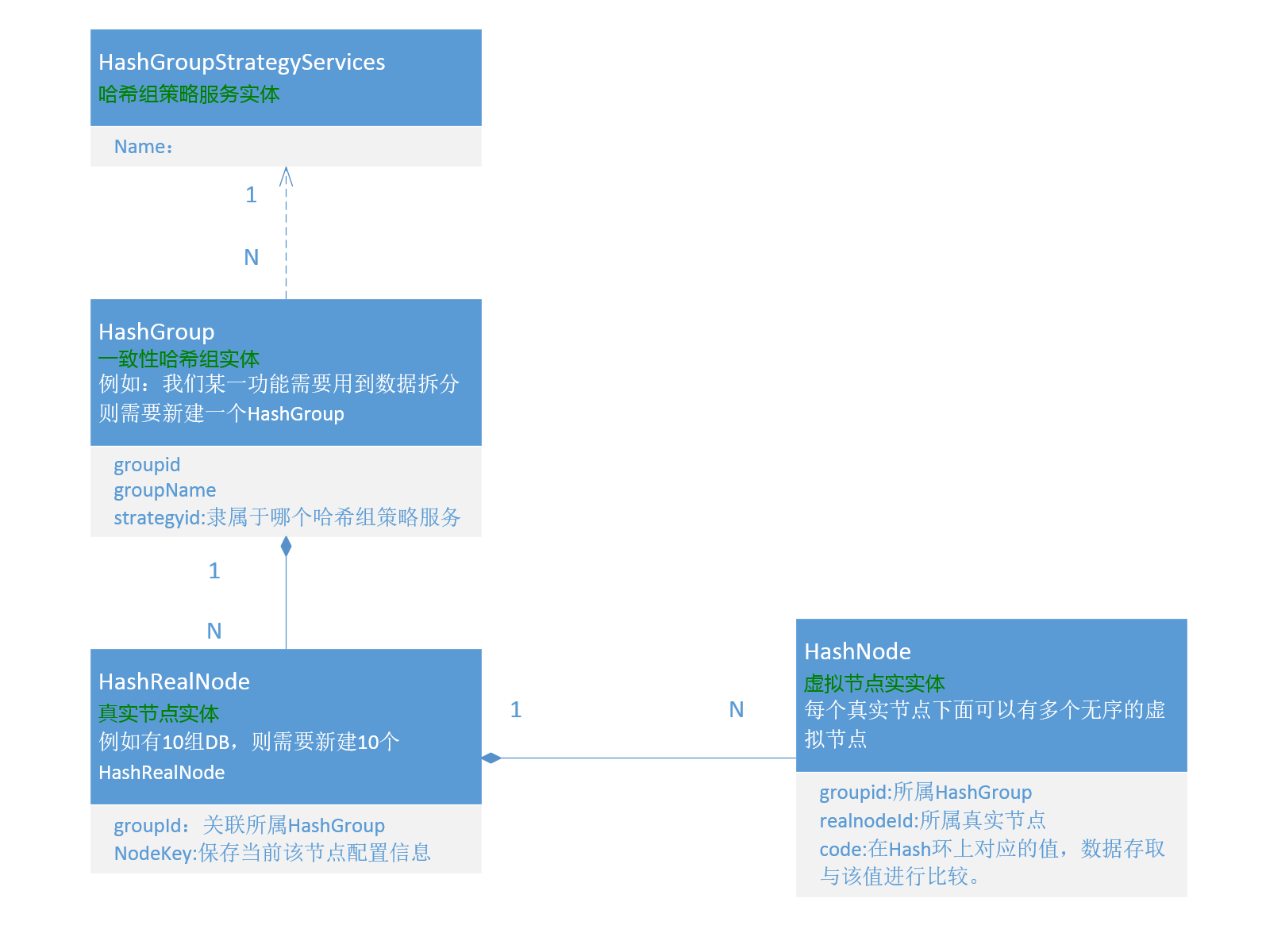
HashRealNode(真实节点)
每条HashRealNode记录对应一个真实的DB节点,如一个HashGroup对应10台DB集群则该HashGroup下会对应10条HashRealNode记录。
每条记录中的NodeKey字段会保存当前服务器相关信息。
NodeKey字段以Json格式保存:
{ "DBConnectionNames": { "ReadAndWrite": "Password=pass;Persist Security Info=True;User ID=sa;Initial Catalog=DB1;Data Source=202.121.66.22", "Read": "Password=pass;Persist Security Info=True;User ID=sa;Initial Catalog=DB2;Data Source=202.121.86.92" }, "TableNames": { "SerialNumber": "SerialNumberRecord19", "SerialGroup": "SerialGroup19" } }
HashNode(虚拟节点)
每个真实节点下面对应多个虚拟节点(关于虚拟节点的解释请参照第二篇文章),每个虚拟节点上的code是无序分配到整个Hash环上。
数据在存取时会与code值进行比较然后找到对应的HashNode进而再找到相应的HashRealNode。
节点变更时的数据迁移服务
当新增或删除节点时需要调用HashDataMigrateServices来进行数据迁移,将数据进行重新再分配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号