
一致性哈希组(Consistent Hashing) 算法及源码(一)通过取模算法实现数据负载均衡
写在前面
通过取模和一致性哈希组实现负载均衡这两个算法分别在两个实际项目中真实用到。
具体架构设计及代码实现均由我们一个架构师完成,我有幸参与了其中一部分的开发和测试工作。
因架构师比较忙所以由我代为整理发布出来,希望和大家一起交流学习,逐渐完善。
一致性哈希组(Consistent Hashing) 算法及源码共分为三篇文章
(一)通过取模算法实现数据负载均衡
(二)一致性哈希组(Consistent Hashing)算法介绍
(三)一致性哈希组基于net core 的具体实现(附源码)
本文结合做过的一个实际项目来说明如何通过取模的方式来实现数据负载均衡。
项目介绍:
项目是一个Loyalty在线识别系统,主要完成客户身份的在线识别和促销码的查询。
会员客户在每次POS端消费的时候会提供手机号,然后POS端调用我们提供的查询接口把该手机号对应的客户信息及该客户所有可用的促销码返回到POS端。
数据量峰值:
客户数量最多2000W左右。
促销码最多2亿条左右。
最多400次/s 并发,要求在半秒内返回查询结果。
技术方案:
接口:C# Socket
DB: SQL Server 2014 内存数据库 + Always on 高可用性
具体实现:
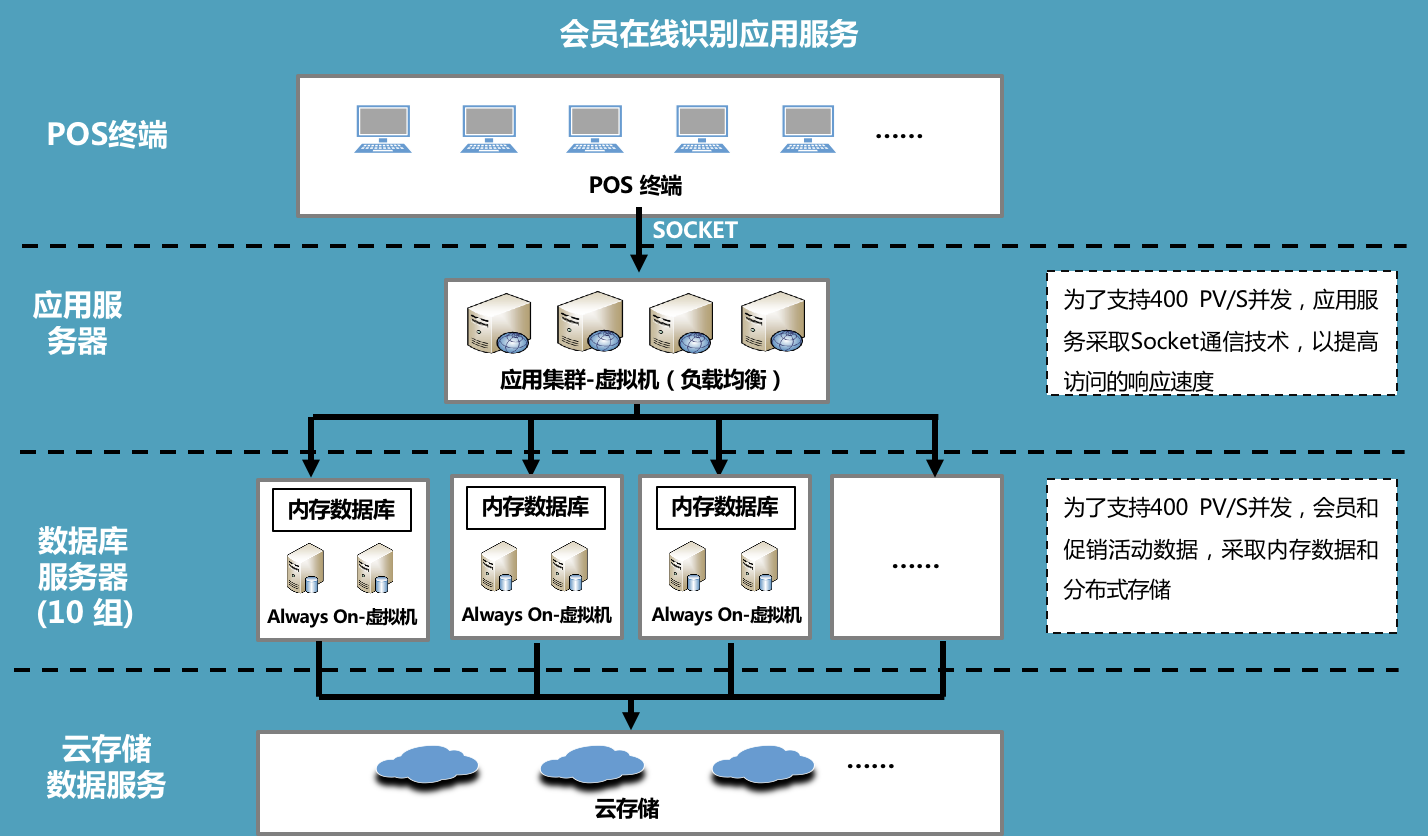
因为数据量比较大并且要求在半秒内返回查询结果,所以在DB层对数据进行分布式存储。
共计分为10组 Always on,每组包含两台真实DB服务器,每台DB均使用内存数据库。
服务器架构如下图:
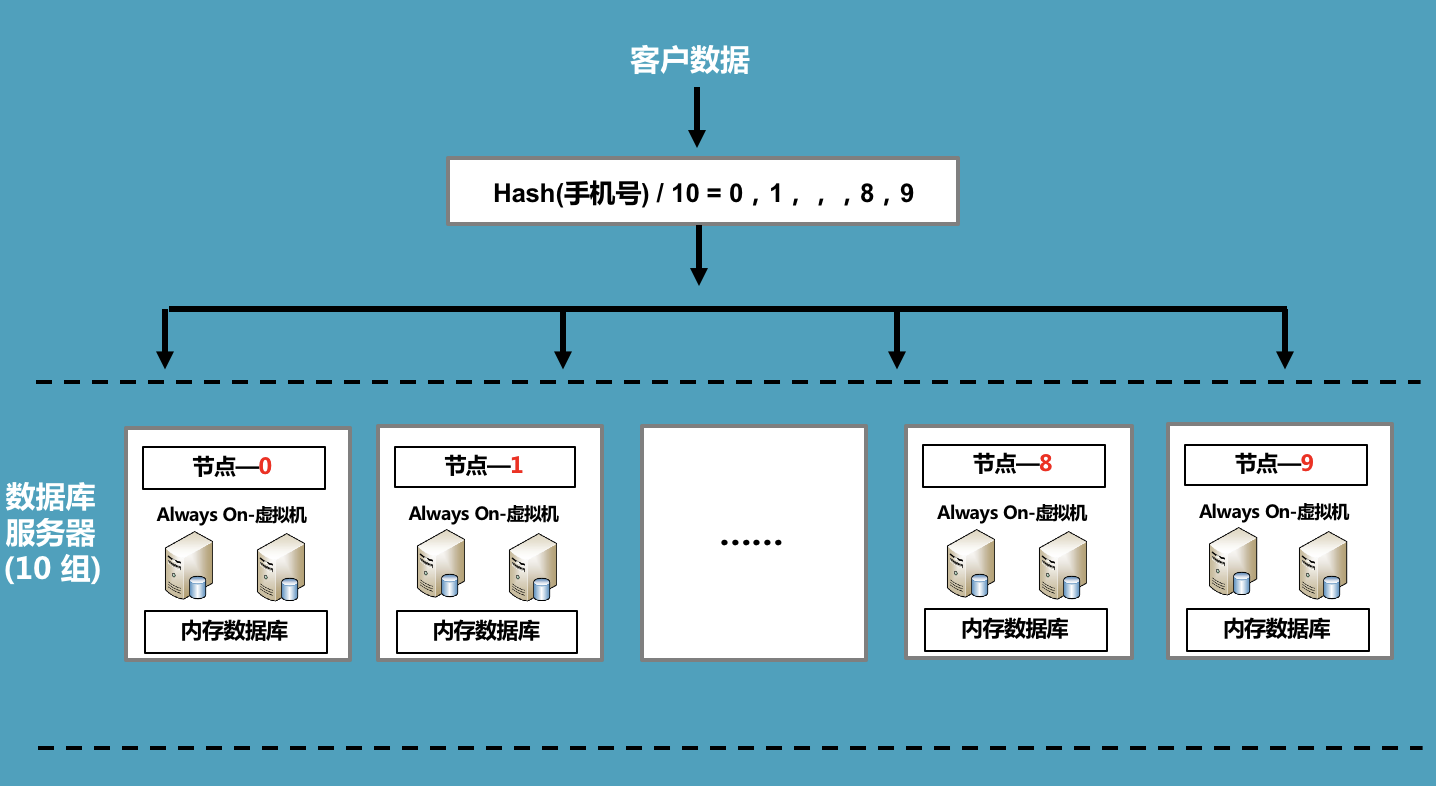
因为分成了10个DB节点所以在对每条数据存取时必须要均匀分配到这10个节点上。
以客户数据存取为例:
0,每条客户数据的主键是手机号(促销数据的主键是促销码)。
1,自定义一个Hash函数,将输入的字符串转成一个Int类型的值。
例如:Hash(手机号)=>返回值( int 类型值)
2,我们先对客户手机号进行Hash计算得到一个int值。
3,将Hash之后的值对总DB节点数(10)进行取余,余数肯定在0-9之间。
4,0-9分别对应一个DB节点。
这样就能将客户数据均匀分布到多个DB节点上。
具体流程如下:
以上取模算法虽然实现了数据的负载均衡但也存在一些问题。
1,在增减节点时如何保证对现有数据做最小的移动呢?
例如随着业务的发展发现10组数据库不够用了需要再加几组数据库或者实际数据远远低于一开始预期想删掉几组数据库。这就导致了DB总节点数发生了变化,取模之后的余数与原来均不一样,需要把已存进去的数据均进行一次重新分配。
2,当其中某个节点down掉之后保存在该节点上的数据全部不能使用。
以上问题在一致性哈希组(Consistent Hashing)中均得到解决,所以我们在最近的一个项目上通过Consistent Hashing 来实现了负载均衡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号