【python爬虫】2.爬小米应用商店
主要就是beautifulsoup的一些用法
但现在还是局限于:1.只能爬网页端 2.只能爬网页端存在超链接的地方
所以爬到的数据不多,要爬手机端还得接着学手机各种协议各种包的知识,还有很长的路
import time import requests import re from bs4 import BeautifulSoup def parse(soup): try: title=soup.body.find(class_='main').find(class_='container cf').find(class_='app-intro cf').div.div.h3.text # print(title) fo.write(title+'\n') except: return details=soup.body.find(class_='main').find(class_='container cf') for i in details.find_all(style="width:100%; display: inline-block"): item=i.find(class_='float-left').div.text data=i.find(class_='float-left').find(style='float:right;').text ans=item+':'+data b=ans.split() ans="".join(b) if ans: # print(ans) fo.write(ans+'\n') fo.write('\n') def get_url(): for page in range(3): session = requests.Session() web1 = session.get( url='https://app.mi.com/catTopList/0?page='+str(page), headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.36', } ) soup1 = BeautifulSoup(web1.text, 'lxml') applist=soup1.body.find(class_='main').find(class_='container cf').find(class_='main-con').find(class_='applist-wrap').find(class_='applist') for i in applist.find_all('li'): # print(i.a.get('href')) web2 = session.get( url='https://app.mi.com'+i.a.get('href'), headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.36', } ) soup2 = BeautifulSoup(web2.text, 'lxml') parse(soup2) if __name__ == '__main__': fo = open("mi.txt", "w") get_url() # parse(soup)
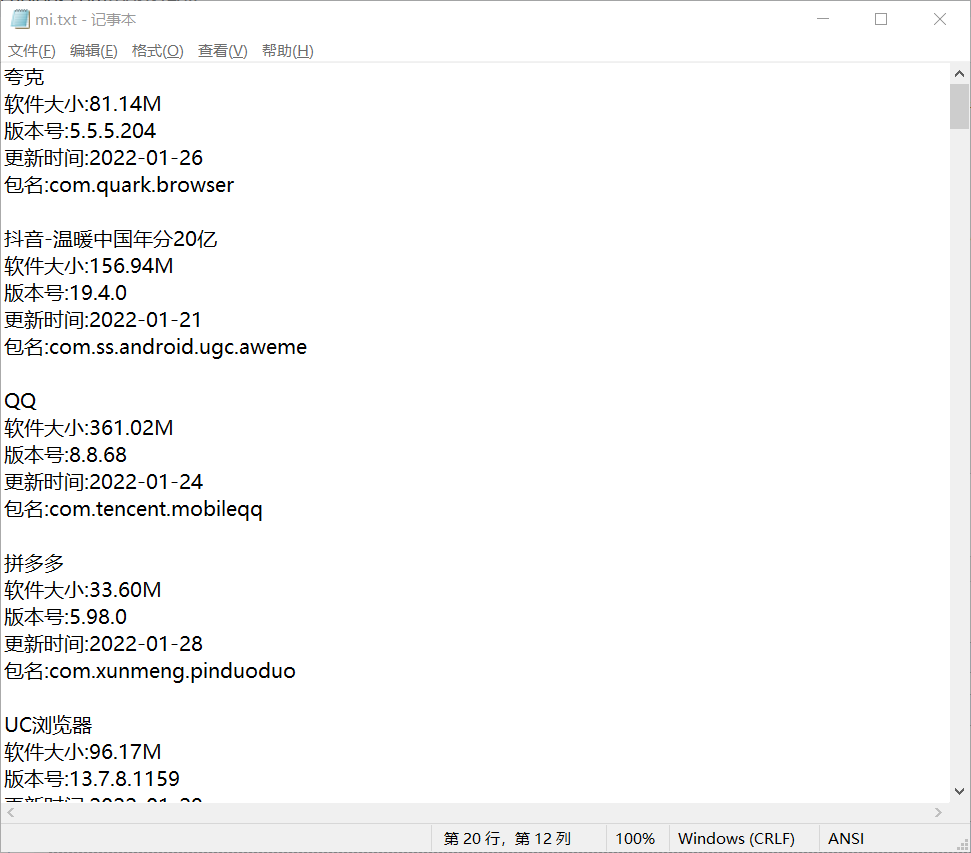
输出mi.txt:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号