

“一码通”设计随想
“一码通”系统设计
前言
这几天看新闻,西安的一码通半个月崩溃了两次,影响了普通市民的出行。在这里也想一下,一码通其实也是一种大规模海量高并发的系统,而且使用场景,较之电商,抢票之类的,也有很多自己独特的地方,在这里做一个简单的系统设计,算抛砖引玉。如有设计得不合理或者不清楚的地方,还麻烦批评指正。
需求
1. “一码通”是针对单个城市进行使用的,但存在扩展至全省,或全国的可能性。
2. “一码通”相对来说是一个读多写少的系统,原因是“一码通”内容的更新一般伴随核酸检测,乃至大规模核算检测,或者跨区/跨城/跨省的人员流动
3. “一码通”的使用存在比较明显的波峰波谷现象,在早晚上下班高峰期间,出入公共交通,写字楼时存在短时间内大规模访问的现象。
4. “一码通”的各种码存在短时间集中变更的场景,主要原因是做了核酸检测后,会集中更新用户的核酸状态,短时间内会有大规模的访问。
5. 在用户状态变更后,可以不立马表现到终端处,譬如有(一分钟,两分钟,乃至五分钟,十分钟)的状态延迟,也是可以接受的。但是状态转换后,应该是稳定一致的。
6. 对于单个用户来说,单日内访问“一码通”的次数不会过多。(较之消息流/广告埋点等)
7. 单个用户打开“一码通”的延迟,相对容忍度较高,可以为百毫秒,甚至一两秒。
8. 对于单个用户的“一码通”状态,需要有最终一致性,意思是如果该用户状态由黄转绿,不应该在下次打开时,又变为黄,或此反复。如无特殊事件(核酸检测,区域集中状态变更),“一码通”状态是不应该变更的。
9. 需要为后台管理留下操作空间:
a) 存在需要针对某个小粒度区域进行统计的可能性,譬如专门统计南山区黄码人群的总数,专门统计某个年龄段黄码人群总数等
b) 需要具有手工将部分人群状态进行调整的功能,例如即使没有进行核算,也需要将某个小区的用户状态全部置为黄码。
10. 需要为实时统计和离线统计等留下操作的空间。
系统设计
整体设计
设计的难点主要是该系统的访问具有短时间高并发读的现象,而且读操作会远多于写操作。需要增加多级缓存的方式,以降低对系统后端的压力。同时,需要注意的是,如果出现所谓的缓存雪崩之类的场景,例如缓存服务宕机等,services是不应该直接访问db的,因为这可能会直接导致db服务不可用,造成全面雪崩。services在访问缓存失败,最终无法返回健康码时,应该返回失败给移动端。
对于多级缓存,可以增加server内缓存的方式,降低对后端缓存服务的压力。同时,在接入层到server层的路由上,使用一致性哈希的方式,降低对单个server的内存要求。缓存可以使用LRU的方式进行淘汰,主要原因是对于单个用户来说,存在短时间内多次展示一码通的可能,譬如先做地铁,然后转公交,进写字楼前都需要进行展示。
对于数据存储和更新来说,数据本身应该存储至关系型数据库中,使用基于binlog捕获的方式进行缓存和数据库的同步,同时辅以对账的方式进行数据对比核验。使用这种方式的原因是,主要是像“理财通”等基于实时对账同步的方式的对系统压力太大。如果出现单缓存实例数据完全不可用等情况,再依赖对账方式进行数据全量同步。而且,由于系统只需要满足最终一致即可,可以减低短时间内对数据库和缓存的访问压力。
此外,采用关系型数据库方便后台管理系统的建设,这也可以很方便的做一些简单的分析。如果使用MongoDB,ES等,对于后续对接大数据等系统并不是那么方便,这也增加系统运维的复杂度(毕竟Mysql的流行程度远大于其他NoSQL)。同时,这样也方便后端管理功能的开发,以及对单个用户的精细化管理。
系统架构
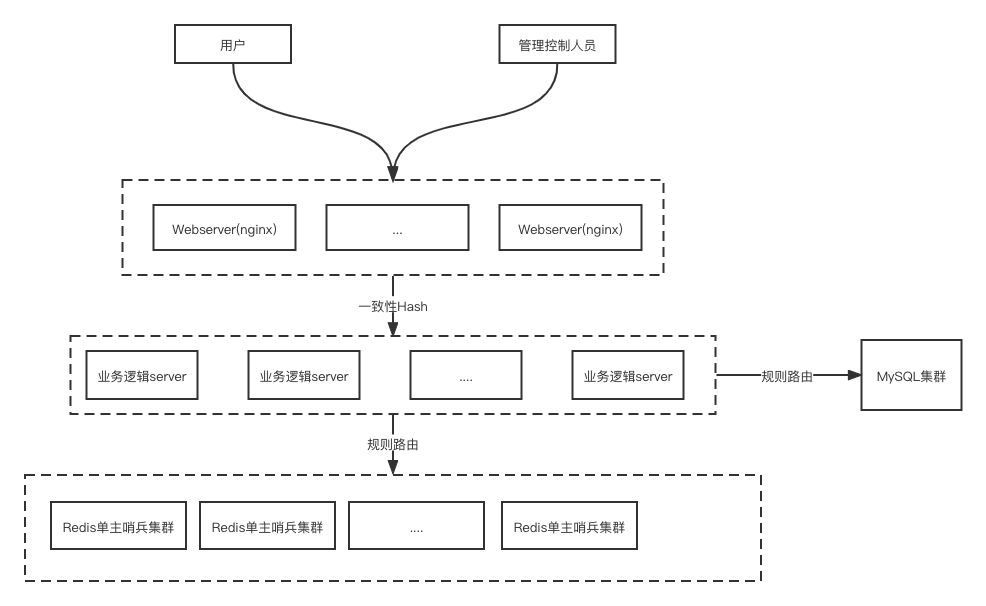
对于单个用户的访问,经过DNS域名转换后,通过虚ip访问对应的接入层集群。这里需要考虑dns集群的服务能力,或者明确dns集群的负载能力,或者采用直接写入ip地址,不经过dns服务进行转换的方式。在接入层之前,为了增加系统的可靠性,可以采用ECMP(等价路由协议)的方式,将流量在ip层直接分散到多个负载均衡设备上。最后将请求传递到接入层nginx上来。在这里使用nginx的主要原因除了常见的webserver层面的功能,如https解包,url重写等功能外,需要支持使用一致性Hash的方式,对下层server进行负载均衡。在这里客户端将用户的唯一标识号,可以为身份证号,可以是设备id号的的后两位作为单独的hash_id作为query params传递到后端,以供nginx进行一致性hash。在这里使用一致性hash的主要原因是使相同用户的请求最终路由到同一个逻辑Server上去,同时使用一致性Hash而不使用直接Hash的方式是因为故障或者扩容时的系统压力。
通过一致性hash的方式,最终使得单个用户的请求始终进入同一个逻辑Server中,这样就可以增加LRU形式的缓存。通过在Logic Server增加缓存的方式,降低对后端缓存服务的压力。读请求进入LogicServer后,在LRU缓存中检查是否命中,如果没有命中则访问缓存服务进行查找。
对于缓存服务,如果是基础设施比较齐备的公司,可以使用内部的缓存服务,这样就可以直接不使用LogicServer的LRU缓存。在配置时也可以更简单一些。不建议使用Redis集群,因为Redis的集群模式,可靠性比较差,不如在客户端直接做路由策略了。
容灾
l nginx
单个nginx实例故障,对系统没有太多影响,仅会增加其他nginx实例的负载压力。所以系统要有一定的冗余,抵抗单实例崩溃造成的流量压力。
l LogicServer
对于逻辑服务故障,需要在nginx侧,通过配置主动下掉某个后端服务。这样的方式主要弊端是如果出现故障,时间会比较长,依赖人工介入。如果对故障非常敏感,需要在nginx和LogicServer之间增加一层cgi,这一层cgi只需要做简单的用户校验检查等常规业务操作即可,此外就是在这一层cgi就是根据注册中心提供的下游服务列表,进行一致性Hash的负载均衡。这样会让服务器成本上升,增加开发成本和运营成本。名字服务的话,可以简单使用nacos即可。
l 缓存实例
缓存实例,对于基础应用功能不是很强大的公司,可以使用多Redis哨兵集群实例的方式。不使用Redis集群的原因主要是Redis集群的路由设计的不太合理,在单片slot故障的时候,整个集群都会故障,会降低系统的可用性。不如直接再客户端做路由访问多个Redis哨兵集群来的更合理。如果是基础服务能力比较强得公司,如腾讯等,直接使用CKV则更为合理。或者如阿里云上的Tair缓存服务等,可以降低整体系统的开发难度。
扩缩容
nginx为无状态的模块,可以直接进行扩容。如果需要增加cgi层,也可以简单增加cgi服务实例的数量,这些都是无状态的模块。如果LogicServer需要扩容,会引起LRU Cache的失效,整个扩缩容操作应该缓慢,同时观察cache的hit率,再进行服务实例的发布。
缓存与数据库同步
使用如阿里DTS的组件进行数据库和缓存之间的数据同步,整体系统是最安全,不会存在所谓的缓存击穿,缓存雪崩之类的现象,对Redis的写压力也最低。可以辅之Redis和数据库的对账的脚本,进行两方对账,防止出现说由于Redis实例崩溃导致的数据不一致现象。
管理功能
管理功能可以直接做在LogicServer上,同时直接操作数据库去实现,系统设计也会比较简单。同学们开发也会比较熟悉。
统计
简单的统计功能可以直接再数据库的异步从库等进行实现,如果有比较多的检索需求,需要使用如DTS等组件,同步至大数据系统进行统计。
结语
整体系统设计得比较简单,主要是考虑海量读操作场景下的系统设计。还有很多地方可以优化,大家多指教

 浙公网安备 33010602011771号
浙公网安备 33010602011771号