(原)centos7安装和使用greenplum4.3.12(详细版)
对于很多IT人来说GREENPLUM是个陌生的名字。简单的说它就是一个与ORACLE, DB2一样面向对象的关系型数据库。我们通过标准的SQL可以对GP中的数据进行访问存取。
本质上讲GREENPLUM是一个关系型数据库集群. 它实际上是由数个独立的数据库服务组合成的逻辑数据库。与RAC不同,这种数据库集群采取的是MPP架构。如下图所示

它的组件分成三个部分MASTER/SEGMENT以及MASTER与SEGMENT之间的高效互联技术GNET。其中MASTER和SEGMENT本身就是独立的数据库SERVER。不同之处在于,MASTER只负责应用的连接,生成并拆分执行计划,把执行计划分配给SEGMENT节点,以及返回最终结果给应用,它只存储一些数据库的元数据,不负责运算,因此不会成为系统性能的瓶颈。这也是GREENPLUM与传统MPP架构数据库的一个重要区别。 SEGMENT节点存储用户的业务数据,并根据得到执行计划,负责处理业务数据。也就是用户关系表的数据会打散分布到每个SEGMENGT节点。当进行数据访问时,首先所有SEGMENT并行处理与自己有关的数据,如果需要segment可以通过进行innterconnect进行彼此的数据交互。 segment节点越多,数据就会打的越散,处理速度就越快。因此与SHARE ALL数据库集群不同,通过增加SEGMENT节点服务器的数量,GREENPLUM的性能会成线性增长。
安装之前看了一些关于greenplun的文章,介绍和解释地实在难以让人满意,结合官网,记录一下自己的搭建过程.
- greenplum集群一共有三个角色,主节点,备节点和数据节点,理论上至少要有三台机器,如果条件差一些,备用节点去掉后续再添加也可以
- 10.10.10.1 master节点
- 10.10.10.2 standby节点
- 10.10.10.3 data1节点
- 10.10.10.4 data2节点
- 系统都为centos7
- 下载地址: https://network.pivotal.io/products/pivotal-gpdb/(包括jdbc连接jar包下载地址)
- 下图是官方对系统的要求
-
Table 1. System Prerequisites for Greenplum Database 4.3 Operating System SUSE Linux Enterprise Server 11 SP2 CentOS 5.0 or higher
Red Hat Enterprise Linux (RHEL) 5.0 or higher
Oracle Unbreakable Linux 5.5
Note: See the Greenplum Database Release Notes for current supported platform information.File Systems - xfs required for data storage on SUSE Linux and Red Hat (ext3 supported for root file system)
Minimum CPU Pentium Pro compatible (P3/Athlon and above) Minimum Memory 16 GB RAM per server Disk Requirements - 150MB per host for Greenplum installation
- Approximately 300MB per segment instance for meta data
- Appropriate free space for data with disks at no more than 70% capacity
- High-speed, local storage
Network Requirements 10 Gigabit Ethernet within the array Dedicated, non-blocking switch
Software and Utilities bash shell GNU tars
GNU zip
GNU sed (used by Greenplum Database gpinitsystem)
- 安装分为两步,一个是系统配置,然后才是配置.系统配置主要是做磁盘优化,主机通讯等工作.
- root用户登录,查看SELinuxstatus
sestatus
如果不是disabled,则需要修改参数:
vi /etc/selinux/config
修改
SELINUX=disabled
- 关闭防火墙 ,因为是centos7,默认防火墙为firewall,先查看
systemctl status firewalld
如果为关闭状态则显示如下:
* firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled) Active: inactive (dead)
否则执行命令:
# systemctl stop firewalld # systemctl disable firewalld - 接下来执行一些推荐配置,理论上不配置也不影响使用,只不过影响性能,包括三方面,共享内存,网络和用户限制
vi /etc/sysctl.conf
如果没有的话添加如下配置,重启生效,可以等全改完重启.
kernel.shmmax = 500000000 kernel.shmmni = 4096 kernel.shmall = 4000000000 kernel.sem = 250 512000 100 2048 kernel.sysrq = 1 kernel.core_uses_pid = 1 kernel.msgmnb = 65536 kernel.msgmax = 65536 kernel.msgmni = 2048 net.ipv4.tcp_syncookies = 1 net.ipv4.conf.default.accept_source_route = 0 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_max_syn_backlog = 4096 net.ipv4.conf.all.arp_filter = 1 net.ipv4.ip_local_port_range = 10000 65535 net.core.netdev_max_backlog = 10000 net.core.rmem_max = 2097152 net.core.wmem_max = 2097152 vm.overcommit_memory = 2
更改文件限制
vi /etc/security/limits.conf
文件末尾添加
* soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072
说明,如果centos或redhat6版本的,该配置会被/etc/security/limits.d/90-nproc.conf覆盖,注意两边都修改.
- 更改文件格式,推荐xfs
vi /etc/fstab
比如:
/dev/data /data xfs nodev,noatime,nobarrier,inode64,allocsize=16m 0 0
- 磁盘io调度算法有多种:CFQ, AS,deadline.greenplum推荐deadline,通过命令指定重启后的调度算法:(对各个盘进行操作)
# echo schedulername > /sys/block/devname/queue/scheduler
比如修改sdb调度:
# echo deadline > /sys/block/sdb/queue/schedule
也可以通过加入启动项参数的方法修改调度算法,centos6和7的做法不相同,如果是6:
vi /boot/grub/grub.conf
添加启动参数如下:
kernel /vmlinuz-2.6.18-274.3.1.el5 ro root=LABEL=/ elevator=deadline crashkernel=128M@16M quiet console=tty1 console=ttyS1,115200 panic=30 transparent_hugepage=never initrd /initrd-2.6.18-274.3.1.el5.img
如果是centos7,运行:
grubby --update-kernel=ALL --args="elevator=deadline"
- 修改磁盘预读量为16384,查看预读量
# /sbin/blockdev --getra devname
比如:
# /sbin/blockdev --getra /dev/sdb
设置预读量:
# /sbin/blockdev --setra bytes devname
比如:
# /sbin/blockdev --setra 16384 /dev/sdb
- 修改hosts文件确保,几个主机之间能够互相识别:
vi /etc/hosts
比如
10.10.10.1 mdw 10.10.10.2 smdw 10.10.10.3 sdw1 10.10.10.4 sdw2
注意多网卡的情况,我只有单网卡,所以就不麻烦得写多网卡了.
- 关闭Transparent Huge Pages (THP),同样是分开centos6和centos7两种不同的系统不同操作,分别是:
kernel /vmlinuz-2.6.18-274.3.1.el5 ro root=LABEL=/ elevator=deadline crashkernel=128M@16M quiet console=tty1 console=ttyS1,115200 panic=30 transparent_hugepage=never initrd /initrd-2.6.18-274.3.1.el5.img
centos7:
# grubby --update-kernel=ALL --args="transparent_hugepage=never"
- 到这里系统配置就完成了,重启后安装greenplum
- 安装greenplum,注意所有操作均在master节点上运行
- 解压运行
-
# unzip greenplum-db-4.3.x.x-PLATFORM.zip
# /bin/bash greenplum-db-4.3.x.x-PLATFORM.bin
有提示安装路径推荐默认()/usr/local/greenplum-db-4.3.x.x)
- 安装
$ su -
环境变量:
# source /usr/local/greenplum-db/greenplum_path.sh
创建文件hostfile_exkeys:
mdw smdw sdw1 sdw2如果机子上存在多个网卡,则要全部写上,比如:(每台机子下方写上该主机的网络接口,mdw-1是网络接口)
mdw mdw-1 mdw-2 smdw smdw-1 smdw-2 sdw1 sdw1-1 sdw1-2 sdw2 sdw2-1 sdw2-2 sdw3 sdw3-1 sdw3-2
运行文件:后面跟着的账户和密码是greenplum管理用户
# gpseginstall -f hostfile_exkeys -u gpadmin -p changeme
- 确认安装:先用gpadmin登录:
$ su - gpadmin
环境变量:
# source /usr/local/greenplum-db/greenplum_path.sh
运行命令测试
$ gpssh -f hostfile_exkeys -e ls -l $GPHOME
这个命令目的是登录到其他数据机器运行ls,如果能够正常显示说明主机之间登录和命令运行没有问题.如果出现提示需要输入密码,则需要再运行:
$ gpssh-exkeys -f hostfile_exkeys
- 安装拓展
$ psql -d testdb -f $GPHOME/share/postgresql/contrib/orafunc.sql
安装拓展需要对每一个库运行,上面命令是对testdb拓展,如果想去掉拓展
$GPHOME/share/postgresql/contrib/uninstall_orafunc.sql
- master和standby节点创建目录(使用root):
# mkdir /data/master
赋权
# chown gpadmin /data/master
使用工具在standby节点上操作:
# source /usr/local/greenplum-db-4.3.x.x/greenplum_path.sh # gpssh -h smdw -e 'mkdir /data/master' # gpssh -h smdw -e 'chown gpadmin /data/master'
-
segment 节点创建目录(也是root),先创建文件hostfile_gpssh_segonly,内容是数据节点
sdw1 sdw2运行:
# source /usr/local/greenplum-db-4.3.x.x/greenplum_path.sh # gpssh -f hostfile_gpssh_segonly -e 'mkdir /data/primary' # gpssh -f hostfile_gpssh_segonly -e 'mkdir /data/mirror' # gpssh -f hostfile_gpssh_segonly -e 'chown gpadmin /data/primary' # gpssh -f hostfile_gpssh_segonly -e 'chown gpadmin /data/mirror'
-
所有机器用ntp同步时间,修改配置文件并更新即可:
vi /etc/ntp.conf
在主节点上运行:
# gpssh -f hostfile_gpssh_allhosts -v -e 'ntpd'
-
开启防火墙
$ gpstop -a
$ service firewalld start
$ gpstart -a
- greenplum使用须知
-
权限配置文件:/data/master/gpseg-1/pg_hba.conf(当前配置了10.1.3.0的所有ip都可以以任何角色访问任何库),不配置角色权限以下几点可以不看:
-
TYPE定义了多种连接PostgreSQL的方式,分别是:“local”使用本地unix套接字,“host”使用TCP/IP连接(包括SSL和非SSL),“host”结合“IPv4地址”使用IPv4方式,结合“IPv6地址”则使用IPv6方式,“hostssl”只能使用SSL TCP/IP连接,“hostnossl”不能使用SSL TCP/IP连接。
-
DATABASE指定哪个数据库,多个数据库,库名间以逗号分隔。“all”只有在没有其他的符合条目时才代表“所有”,如果有其他的符合条目则代表“除了该条之外的”,因为“all”的优先级最低。
-
这两条都是指定local访问方式,因为前一条指定了特定的数据库db1,所以后一条的all代表的是除了db1之外的数据库,同理用户的all也是这个道理。
-
USER指定哪个数据库用户(PostgreSQL正规的叫法是角色,role)。多个用户以逗号分隔。
-
CIDR-ADDRESS项local方式不必填写,该项可以是IPv4地址或IPv6地址,可以定义某台主机或某个网段。
-
METHOD指定如何处理客户端的认证。常用的有ident,md5,password,trust,reject。
-
ident是Linux下PostgreSQL默认的local认证方式,凡是能正确登录服务器的操作系统用户(注:不是数据库用户)就能使用本用户映射的数据库用户不需密码登录数据库。用户映射文件为pg_ident.conf,这个文件记录着与操作系统用户匹配的数据库用户,如果某操作系统用户在本文件中没有映射用户,则默认的映射数据库用户与操作系统用户同名。比如,服务器上有名为user1的操作系统用户,同时数据库上也有同名的数据库用户,user1登录操作系统后可以直接输入psql,以user1数据库用户身份登录数据库且不需密码。很多初学者都会遇到psql -U username登录数据库却出现“username ident 认证失败”的错误,明明数据库用户已经createuser。原因就在于此,使用了ident认证方式,却没有同名的操作系统用户或没有相应的映射用户。解决方案:1、在pg_ident.conf中添加映射用户;2、改变认证方式。
-
md5是常用的密码认证方式,如果你不使用ident,最好使用md5。密码是以md5形式传送给数据库,较安全,且不需建立同名的操作系统用户。
-
password是以明文密码传送给数据库,建议不要在生产环境中使用。
-
trust是只要知道数据库用户名就不需要密码或ident就能登录,建议不要在生产环境中使用。
-
reject是拒绝认证。
-
修改后运行gpstop –u生效,不必重启
-
-
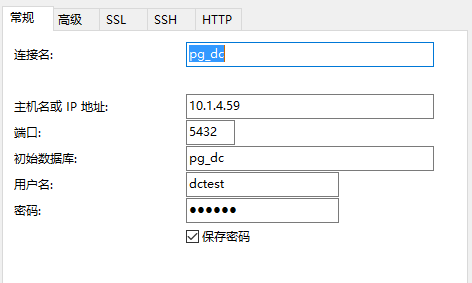
连接可以使用Navicat,pgadmin, RazorSQL, Aginity Workbench for Pivotal Greenplum,连接属性如下图:
- 创建概念须知:
-
- 角色(role)与用户(user):对于PostgreSQL来说,这是完全相同的两个对象。
- 数据库是被模式(schema)来切分的,一个数据库至少有一个模式,所有数据库内部的对象(object)是被创建于模式的。用户登录到系统,连接到一个数据库后,是通过该数据库的search_path(schema)来寻找schema的搜索顺序:
-
更改角色的search_path,可以使查询时优先根据search_path中带有的schema进行查询,简便查询.因为一个角色下可能有多个schema,其中有些对象名称相同,如果没有配置search_path,查询时又没有带上表所属的schema将会报错.更改语句如下:
ALERT ROLE name SET search_path TO schema [, schema, ...]
-
官方建议是这样的:在管理员创建一个具体数据库后,应该为所有可以连接到该数据库的用户分别创建一个与用户名相同的模式,然后,将search_path设置为"$user"(即缺省模式为与用户名相同的模式),这样,任何当某个用户连接上来后,会默认将查找或者定义的对象都定位到与之同名的模式中。这是一个好的设计架构。
-
创建示例:
create user testuser; create schema testuser; GRANT ALL ON SCHEMA testuser TO testuser; GRANT ALL ON DATABASE xxx TO testuser; alter user testuser PASSWORD ‘testuser’; -
Linux连接操作:
psql -h 10.1.4.59 -Udctest pg_dc –W
(dctest为用户名,pg_dc是数据库)
-
操作语句与oracle差不多:比如创建表
create table public.t1(id text); - 创建schema:
create schema authorization hippo;#最好指定拥有者,默认为当前用户.
-
有一些系统表可以查看对象信息:
- pg_class:该系统表记录了数据表、索引(仍然需要参阅pg_index)、序列、视图、复合类型和一些特殊关系类型的元数据。注意:不是所有字段对所有对象类型都有意义。
- pg_attribute:该系统表存储所有表(包括系统表,如pg_class)的字段信息。数据库中的每个表的每个字段在pg_attribute表中都有一行记录。
- pg_database:该系统表存储数据库的信息。和大多数系统表不同的是,在一个集群里该表是所有数据库共享的,即每个集群只有一份pg_database拷贝,而不是每个数据库一份。
-
以上几个比较常用,其他也有看表空间,索引等…
- jdbc示例:
- git clone https://github.com/randomtask1155/PivotalJDBCTest.git
- 其他内容后续添加.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号