MySQL数据库
[TOC]
一.基础操作
1.安装
参考:https://www.cnblogs.com/Eva-J/articles/9669675.html' https://www.cnblogs.com/Ailsa-a/protected/articles/11368316.html


在我们下载完mysql,mysql服务端默认root账户密码为空,此时在终端输入:mysql -uroot -p 回车然后回车,再回车,可验证密码为空;在此前不会加载my.ini配置文件,需要在终端设置密码set password=password("xx"),这是设置mysql服务端的密码,之后在终端只输入mysql,回车,会加载配置文件中的账户密码和服务端的比较。
[mysqld] character-set-server=utf8 collation-server=utf8_general_ci [client] default-character-set=utf8 [mysql] user="root" password="root" default-character-set=utf8
set character_set_database=’utf8’; set character_set_server=’utf8’; status
2.用户配置
mysql:客户端命令行
mysqld:mysql服务
初始化数据库信息:mysqld --initialize-insecure 注册服务:mysqld -install #将mysqld服务添加到系统服务,只用第一次使用 启动服务:net start mysql 进入数据库:mysql -u root -p(或mysql -u root -h 127.0.0.1 -p) -h 127.0.0.1 没有的话会自动默认为localhost root用户是原本数据库mysql中user表有的,要创建用户、删除用户等操作要用用户管理特殊命令。 最高管理员(root用户): 创建用户: create user '用户名'@'IP地址' identified by '密码'; ps:create user gyk@127.0.0.1 identified by "gyk"; 查看用户:1.select user,password from mysql.user; #查看所有用户 2.select user(); #查看当前用户 删除用户:drop user '用户名'@'IP地址'; 修改用户:rename user '用户名'@'IP地址' to '新用户名'@'IP地址'; 设置密码:set password = password("xx"); #设置当前用户密码 修改密码:set password for '用户名'@'IP地址'=Password('新密码') #设置指定用户密码
3.权限设置
# 创建账号(语法: create user 用户名@IP identified by '密码') create user alisa@'192.168.10.%' identified by'123';# 指示网段 create user alisa@192.168.10.5 # 指示某机器可以连接 create user alisa@'%' #指示所有机器都可以连接 # 查看权限 语法: show grants for 用户名@IP show grants for alisa@192.168.10.5; # 查看某个用户的权限 # 远程登陆 mysql -uroot -p123 -h 192.168.10.3 # 给账号授权 语法: grant 权限 on 库名.表名 to 用户名@IP 权限: select(查询) insert(插入) update(更新) delete(删除) all(代表所有权限) # 分配所有权限 grant all on *.* to alisa@'%'; # 分配查询权限 grant select on *.* to alisa@'%'; # 分配 查询和插入权限 grant select,insert on *.* to alisa@'%'; # 刷新使授权立即生效,涉及到权限和用户密码的都刷新就对了 flush privileges;
# 创建账号并授权 grant all on *.* to alisa@'%' identified by '123' ; # 删除用户权限 语法: revoke 权限 on 库名.表名 from 用户名@IP revoke all on *.* from alisa@'%'; # 删除用户 语法:drop user 用户名@IP drop user 'alisa'@'192.168.0.%';
4.忘记密码???
1.关闭mysql服务端 net stop mysql 2.输入mysqld --skip-grant-tables # 以跳过授权表的方式在命令行中启动mysqld服务端 3.再打开一个cmd 输入 mysql -uroot -p 不用输入密码,直接登录 4.重置mysql.user表中的密码 update mysql.user set password=password('123') where user='root' and host='localhost' flush privileges # 对于用户和权限的操作,建议每次都使用刷新 5.停止mysql服务(刚刚是以跳过授权方式启动的,需要关闭,此时是通过mysqld启动,服务端是夯住的,Ctrl+C停止服务) 6.net start mysql 重启服务 7.输入:mysql -uroot -p123 即可登录 # 还有一个方法是直接在配置文件中的[musqld]中写跳过权限认证的命令,用户几乎一样
5.日志操作
#查看mysql历史命令 cat ~/.mysql_history #查看错误日志(先找到错误日志在哪里) MariaDB [(none)]> show variables like 'log_error'; +---------------+------------------------------+ | Variable_name | Value | +---------------+------------------------------+ | log_error | /var/log/mariadb/mariadb.log | +---------------+------------------------------+
二.库操作
1.命令
使用数据库:use db1; 查看所有数据库:show databases; 查看其中一个库:show create databases db1; 创建数据库:create database db1; 创建数据库并指定编码:create database db1 charset utf8; 修改数据库编码:alter database db1 charset utf8 删除数据库:drop database db1;
2.数据库备份
#语法: # mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql #示例: #单库备份 mysqldump -uroot -p123 db1 > db1.sql mysqldump -uroot -p123 db1 table1 table2 > db1-table1-table2.sql #多库备份 mysqldump -uroot -p123 --databases db1 db2 mysql db3 > db1_db2_mysql_db3.sql #备份所有库 mysqldump -uroot -p123 --all-databases > all.sql
#方法一: mysql -uroot -p123 < /backup/all.sql #方法二: mysql> use db1; mysql> source /root/db1.sql #注:如果备份/恢复单个库时,可以修改sql文件 DROP database if exists school; create database school; use school;
务必保证在相同版本之间迁移 # mysqldump -h 源IP -uroot -p123 --databases db1 | mysql -h 目标IP -uroot -p456
三.表操作
1.表
show tables; #查看当前库下所有表 show create table stu; #查看表(会显示创建表的语句) \G竖着显示 desc stu; #查看表的基本结构 select * from 表名 where id=1 #查看表中数据 drop table 表名; #删除表 delete table 表名 #清空表 truncate table 表名 #清空表并重设id
2.行(记录)
改: 修改数据:update 表名 set 字段名="xx" where id=3; 删: 删除某行:delete from 表名 where name="海购"; 增: insert into 表名 values(1,"海购"),(2,"xx"),(3,"钢环"); insert into 表名 (id,name) values (1,"万钢"),(2,"xx"); #insert into 表名 values(1,"xx"),(2,"ss") 不指定字段名,就要全部添加
3.列
改: 修改类型:alter table 表名 modify 列名 类型 约束 修改列名:alter table 表名 change 原列名 新列名 类型 约束 删: 删除列:alter table 表名 drop cloumn 列名 删除主键:alter table 表名 drop primary key #如果主键有auto_increment,需要先将其字段去除约束 删除外键:alter table 表名 drop foreign key "constraint设置的别名" 增: 添加列:alter table 表名 add 列名 类型 添加主键:alter table 表名 add primary key(列名) 添加外键:alter table 表名 add constraint fk_s foreign key 附表名(pid) references 主表名(id);
四.存储引擎
参考:https://www.cnblogs.com/clschao/articles/9953550.html
1.简单了解
存储引擎的概念只有MySQL中有,是mysql提供的一种存储机制。MySQL中常用的引擎为MyISAM和InnoDB.
1、show engines;#查看MySQL所有的引擎 2、show variables like "storage_engine%";查看当前正在使用的引擎
1.不支持事务 事务是指逻辑上的一组操作,组成这组操作的各个单元,要么全成功要么全失败。 2.表级锁定 数据更新时锁定整个表:其锁定机制是表级锁定,也就是对表中的一个数据进行操作都会将这个表锁定,其他人不能操作这个表,这虽然可以让锁定的实现成本很小但是也同时大大降低了其并发性能。 3.读写互相阻塞 不仅会在写入的时候阻塞读取,MyISAM还会再读取的时候阻塞写入,但读本身并不会阻塞另外的读。 4.只会缓存索引 MyISAM可以通过key_buffer_size的值来提高缓存索引,以大大提高访问性能减少磁盘IO,但是这个缓存区只会缓存索引,而不会缓存数据。 5.读取速度较快 占用资源相对较少 6.不支持外键约束,但只是全文索引 7.MyISAM引擎是MySQL5.5版本之前的默认引擎,是对最初的ISAM引擎优化的产物。
InnoDB引擎特点: 1.支持事务:支持4个事务隔离界别,支持多版本读。 2.行级锁定(更新时一般是锁定当前行):通过索引实现,全表扫描仍然会是表锁,注意间隙锁的影响。 3.读写阻塞与事务隔离级别相关(有多个级别,这就不介绍啦~)。 4.具体非常高效的缓存特性:能缓存索引,也能缓存数据。
memory引擎是内存级别的,所以没有在磁盘上的数据文件,只有一个表结构文件
blackhole:凡是通过这个引擎存的表都会消失,也就是被删掉,所以只有表结构,没有表数据文件
2.使用
1.创建表时指定引擎
create table innodb_t2(id int)engine=innodb;
2.配置文件时指定引擎
linux:vim /etc/my.cnf windows:my.ini文件 [mysqld] default-storage-engine=INNODB #配置默认引擎,现在用的mysql默认基本都是InnoDB,所以其实都可以不用配置了 innodb_file_per_table=1 #表示独立表空间存储,可以不写
3.data文件夹中各文件
1.db.opt文件: 记录该库的默认字符集编码和字符集排序规则。如果新建表中没有指定字符集和排序规则,将会采用db.opt文件中指定的属性。 2.后缀名为.frm的文件: 用来表述数据表结构(id,name字段等)和字段长度等信息。 3.后缀名为.ibd的文件: 存储的是采用独立表储存模式时储存数据库的数据信息和索引信息。 4.后缀名为.MYD(MYData)的文件: 存储数据库数据信息 5.后缀名为.MYI的文件: 存储数据库的索引信息
五.MySQL基础数据类型
1.简单介绍sql_mode
参考:https://www.cnblogs.com/clschao/articles/9962347.html
sql_mode分为两种模式:宽松模式、严格模式。我们在cmd中改变mode模式,它只在当前会话中管用,一旦MySQL服务端重启后就会失效。但是在实际工作中,我们应该在my.ini配置文件中设置严格模式
宽松模式:在输入非法字符时,MySQL解释器不报错,只是警告。例如创建一张表,id字段设置类型为int类型,然后insert的数据大于int最大允许值,不会报错,会按照最大的允许值存储
严格模式:和宽松模式相反,字段规定是什么就是什么。
select @@sql_mode #查看当前会话的sql_mode select @@global.sql_mode #查看全局的sql_mode set sql_mode = '修改后的值' #设置sql_mode
模式的修改:
方式一:先执行select @@sql_mode,复制查询出来的值并将其中的NO_ZERO_IN_DATE,NO_ZERO_DATE删除,然后执行set sql_mode = '修改后的值'或者set session sql_mode='修改后的值';,例如:set session sql_mode='STRICT_TRANS_TABLES';改为严格模式 #session可以不用写 此方法只在当前会话中生效,关闭当前会话就不生效了。 方式二:先执行select @@global.sql_mode,复制查询出来的值并将其中的NO_ZERO_IN_DATE,NO_ZERO_DATE删除,然后执行set global sql_mode = '修改后的值'。 此方法在当前服务中生效,重新MySQL服务后失效 方法三:在mysql的安装目录下,或my.cnf文件(windows系统是my.ini文件),新增 sql_mode = STRICT_TRANS_TABLES #严格模式 添加my.cnf如下: [mysqld] sql_mode=STRICT_TRANS_TABLES
2.数值类型
#创建表完整语句
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
常用数据类型:数字(int),字符串(char),时间类型(datetime),枚举和集合(enum,set)
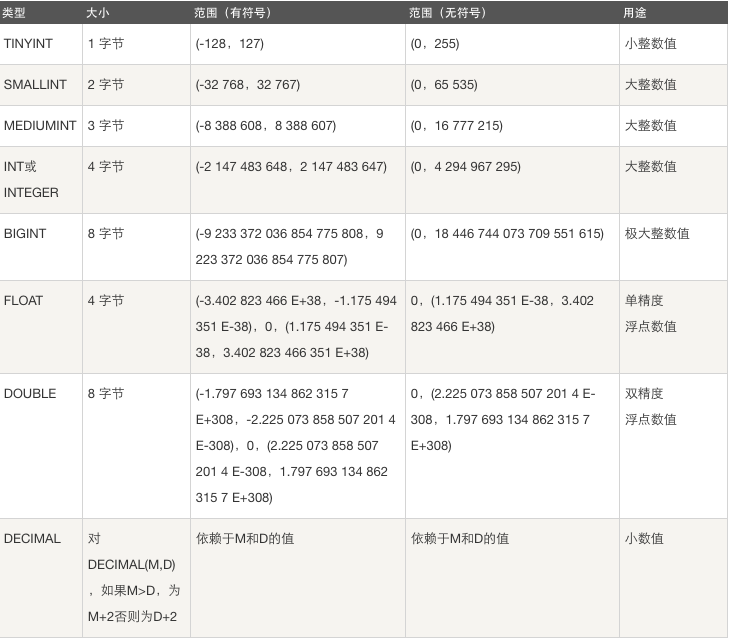
int的存储宽度是4个Bytes,即32个bit,即2**32
例子:
create table a1(id int) create table a1(id int unsigned) #无符号 create table a1(id int,num float(60,30)) #浮点数总长度为60,小数位30位
3.日期类型
日期类型分布:
YEAR YYYY(范围:1901/2155)2018 DATE YYYY-MM-DD(范围:1000-01-01/9999-12-31)例:2018-01-01 TIME HH:MM:SS(范围:'-838:59:59'/'838:59:59')例:12:09:32 DATETIME YYYY-MM-DD HH:MM:SS(范围:1000-01-01 00:00:00/9999-12-31 23:59:59 Y)例: 2018-01-01 12:09:32 TIMESTAMP YYYYMMDD HHMMSS(范围:1970-01-01 00:00:00/2037 年某时) 日期类型分类
日期类型测试:
create table a1(id int,times datetime); insert into a1(1,now());
4.字符串类型
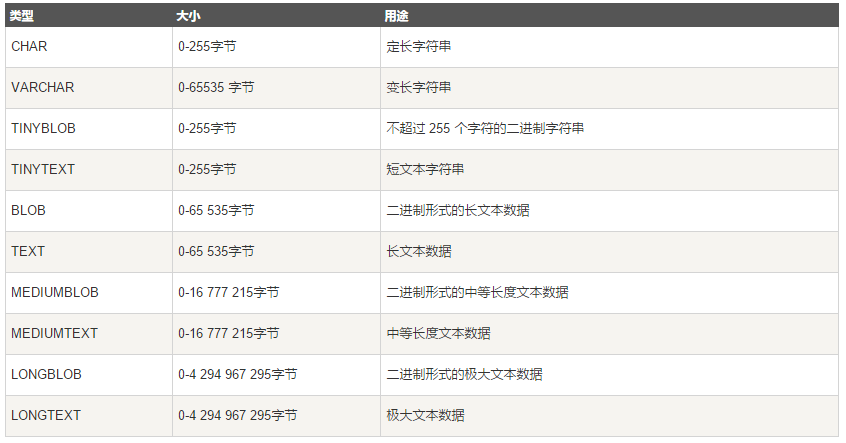
一般我们用到char和varchar
#注意:char和varchar括号内的参数指的都是字符的长度 #char类型:定长,简单粗暴,浪费空间,存取速度快 字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节) 存储: 存储char类型的值时,会往右填充空格来满足长度 例如:指定长度为10,存>10个字符则报错(严格模式下),存<10个字符则用空格填充直到凑够10个字符存储 检索: 在检索或者说查询时,查出的结果会自动删除尾部的空格,如果你想看到它补全空格之后的内容,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'strict_trans_tables,PAD_CHAR_TO_FULL_LENGTH';) #varchar类型:变长,精准,节省空间,存取速度慢 字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html) 存储: varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来 强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用) 如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255) 如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535) 检索: 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
5.枚举和集合类型
枚举类型(enum) 示例: CREATE TABLE shirts ( name VARCHAR(40), size ENUM('x-small', 'small', 'medium', 'large', 'x-large') ); INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small'); 集合类型(set) 示例: CREATE TABLE myset (col SET('a', 'b', 'c', 'd')); INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
六.MySQL完整性约束
参考:https://www.cnblogs.com/clschao/articles/9968396.html
1.介绍
约束条件和数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分类:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录 FOREIGN KEY (FK) 标识该字段为该表的外键 NOT NULL 标识该字段不能为空 UNIQUE KEY (UK) 标识该字段的值是唯一的 AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键) DEFAULT 为该字段设置默认值 UNSIGNED 无符号 ZEROFILL 使用0填充
2.not null和default 非空/默认值
create table tb1( nid int not null defalut 2, #设置nid不为空,切默认值为2 num int not null );
3.unique 唯一
是一种key,唯一键,是在数据类型之外的附加属性,其实还有加速查询的作用
create table department1( id int, name varchar(20) unique, comment varchar(100) );
4.primary key 主键
从约束角度看primary key字段的值不为空且唯一,相当于not null+unique,一张表中必须只有一个主键,在没有主键的时候,not null+unique会被默认当成主键。
create table department2( id int primary key, #主键 name varchar(20), comment varchar(100) );
============单列做主键=============== #方法一:not null+unique create table department1( id int not null unique, #主键 name varchar(20) not null unique, comment varchar(100) ); mysql> desc department1; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | NO | UNI | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec) #方法二:在某一个字段后用primary key create table department2( id int primary key, #主键 name varchar(20), comment varchar(100) ); mysql> desc department2; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.00 sec) #方法三:在所有字段后单独定义primary key create table department3( id int, name varchar(20), comment varchar(100), constraint pk_name primary key(id); #创建主键并为其命名pk_name mysql> desc department3; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec)
5.auto_increment 自增
要和primary key结合使用
#不指定id,则自动增长 create table student( id int primary key auto_increment, name varchar(20), sex enum('male','female') default 'male' ); mysql> desc student; +-------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | sex | enum('male','female') | YES | | male | | +-------+-----------------------+------+-----+---------+----------------+ mysql> insert into student(name) values -> ('egon'), -> ('alex') -> ; mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 1 | egon | male | | 2 | alex | male | +----+------+------+ #也可以指定id mysql> insert into student values(4,'asb','female'); Query OK, 1 row affected (0.00 sec) mysql> insert into student values(7,'wsb','female'); Query OK, 1 row affected (0.00 sec) mysql> select * from student; +----+------+--------+ | id | name | sex | +----+------+--------+ | 1 | egon | male | | 2 | alex | male | | 4 | asb | female | | 7 | wsb | female | +----+------+--------+ #对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长 mysql> delete from student; Query OK, 4 rows affected (0.00 sec) mysql> select * from student; Empty set (0.00 sec) mysql> insert into student(name) values('ysb'); mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 8 | ysb | male | +----+------+------+ #应该用truncate清空表,比起delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它 mysql> truncate student; Query OK, 0 rows affected (0.01 sec) mysql> insert into student(name) values('egon'); Query OK, 1 row affected (0.01 sec) mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 1 | egon | male | +----+------+------+ row in set (0.00 sec) auto_increment测试
6.foreign key 外键
外键一般存在三种关系:一对一,一对多(多对一),多对多
一对一:外键写在表数据少的里面,因为必须一对一对应,多余的部分会删除。如果写在数据多的表中,无法一一对应,会报错
1.在创建表时同时创建外键 学生表(student)和客户表(customer) create table student( id int primary key, name char(10), cid int unique, #外键必须是唯一的 foreign key(cid) references customer(id) #student表中的cid映射到customer表中的id字段 ); create table student( id int primary key, name char(10), cid int unique, #外键必须是唯一的 constraint fk_s foreign key(cid) references customer(id) ); 2.在已经创建的表中添加外键 create table student( id int primary key, name char(10), cid int ); alter table student add foreign key (cid) references customer(id); alter table student add constraint fk_s foreign key(cid) references customer(id);
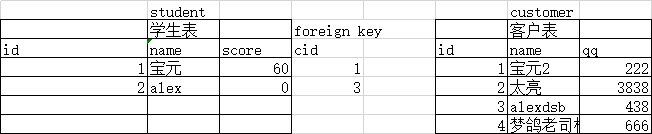
一对多(多对一):外键写在关系中多的表中(一个出版社对应多个书籍,那外键就写在书籍表中)
create table book( id int primary key, name char(10), pid int, foreign key(pid) references publish(id) );

多对多:需要借助第三张表,在第三张表中设置外键
create table authortobook( id int primary key, author_id int, book_id int, foreign key(author_id) references author1(id), foreign key(book_id) references book1(id) );
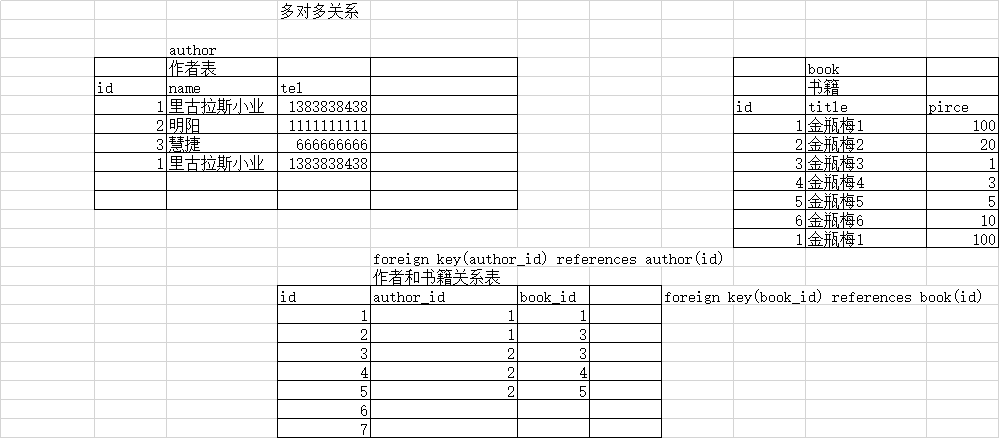
7.级联
三个模式:严格模式、级联模式、set null模式
只有删除或更新主表(外键不在的表中),从表才会相应的变更,删除或更新从表,主表不变。
1.严格模式(默认)
外键有强制约束效果,主表中被关联字段不能随意删除和更改
2.级联模式(cascade)
主表被关联字段删除更新时,附表中对应的也会删除更新。
mysql> select * from td1; +----+------+ | id | pid | +----+------+ | 3 | 2 | | 7 | 3 | | 4 | 4 | +----+------+ mysql> select * from td2; +----+-------+ | id | name | +----+-------+ | 2 | egon | | 3 | alex1 | | 4 | egon2 | +----+-------+ update td2 set id=6 where id=2; #修改后 mysql> select * from td1; +----+------+ | id | pid | +----+------+ | 7 | 3 | | 4 | 4 | | 3 | 6 | mysql> select * from td2; +----+-------+ | id | name | +----+-------+ | 3 | alex1 | | 4 | egon2 | | 6 | egon | +----+-------+
constraint fk_t1_publish foreign key(pid) references publish(id) on delete cascade on update cascade;
3.set null模式
被关联字段删除后,关联它的字段会设置成null
constraint fk_t1_publish foreign key(pid) references publish(id) set null;
七.单表查询
1.查询语法
#查询数据的本质:mysql会到你本地的硬盘上找到对应的文件,然后打开文件,按照你的查询条件来找出你需要的数据。下面是完整的一个单表查询的语法 select distinct 字段1,字段2... FROM 库名.表名 #distince去重 WHERE 条件 #从表中找符合条件的数据记录,where后面跟的是你的查询条件 GROUP BY field(字段) #分组 HAVING 筛选 #过滤,过滤之后执行select后面的字段筛选,就是说我要确定一下需要哪个字段的数据,你查询的字段数据进行去重,然后在进行下面的操作 ORDER BY field(字段) #将结果按照后面的字段进行排序 LIMIT 限制条数 #将最后的结果加一个限制条数,就是说我要过滤或者说限制查询出来的数据记录的条数 select concat("姓名:",name,"年龄:",age) from 表 #得到一个组合形式的字段 select concat(",",name,age) from 表 #第一个参数指定分隔符
1.找到表:from 2.拿着where指定的约束条件,去文件/表中取出一条条记录 3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组 4.将分组的结果进行having过滤 5.执行select 6.去重 7.将结果按条件排序:order by 8.限制结果的显示条数
2.WHERE约束
where语句中可以使用: 1. 比较运算符:> < >= <= <> !=都是不等于 2. between 80 and 100 值在80到100之间 3. in(80,90,100) 值是80或90或100 4. like 'egon%' pattern可以是%或_, %表示任意多字符 _表示一个字符 5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not 1.select * from 表 where 字段<>1; 查询表中字段不等于1的所有值 2.select * from 表 where 字段 between a and b; 3.select * from 表 where 字段 in (89,90,100); 4.select * from 表 where 字段 like "ego%";
3.分组(GROUP BY)
单独使用GROUP BY关键字分组 SELECT post FROM employee GROUP BY post; 注意:我们按照post字段分组,那么select查询的字段只能是post,想要获取组内的其他相关信息,需要借助函数 GROUP BY关键字和GROUP_CONCAT()函数一起使用,比如说我想按部门分组,每个组有哪些员工,都显示出来,怎么搞 SELECT post,GROUP_CONCAT(name) FROM employee GROUP BY post;#按照岗位分组,并查看组内所有成员名,通过逗号拼接在一起 SELECT post,GROUP_CONCAT(name,':',salary) as emp_members FROM employee GROUP BY post; GROUP BY一般都会与聚合函数一起使用,聚合是什么意思:聚合就是将分组的数据聚集到一起,合并起来搞事情,拿到一个最后的结果 select post,count(id) as count from employee group by post;#按照岗位分组,并查看每个组有多少人,每个人都有唯一的id号,我count是计算一下分组之后每组有多少的id记录,通过这个id记录我就知道每个组有多少人了 关于集合函数,mysql提供了以下几种聚合函数:count、max、min、avg、sum等,上面的group_concat也算是一个聚合函数了,做字符串拼接的操作
4.HAVING过滤
having的语法格式和where是一模一样的,只不过having是在分组之后进行的进一步的过滤,where不能使用聚合函数,having是可以使用聚合函数的 #!!!执行优先级从高到低:where > group by > having #1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。 #2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,having是可以使用聚合函数
5.ORDER BY排序
SELECT * FROM employee ORDER BY salary; #默认是升序排列 SELECT * FROM employee ORDER BY salary ASC; #升序 SELECT * FROM employee ORDER BY salary DESC; #降序
6.LIMIT限制条数
示例: #取出工资最高的前三位 SELECT * FROM employee ORDER BY salary DESC LIMIT 3; #默认初始位置为0,从第一条开始顺序取出三条 SELECT * FROM employee ORDER BY salary DESC LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条 SELECT * FROM employee ORDER BY salary DESC LIMIT 5,5; #从第5开始,即先查询出第6条,然后包含这一条在内往后查5条
7.使用正则查询
#之前我们用like做模糊匹配,只有%和_,局限性比较强,所以我们说一个正则,之前我们是不是学过正则匹配,你之前学的正则表达式都可以用,正则是通用的 SELECT * FROM employee WHERE name REGEXP '^ale'; SELECT * FROM employee WHERE name REGEXP 'on$'; SELECT * FROM employee WHERE name REGEXP 'm{2}'; 小结:对字符串匹配的方式 WHERE name = 'egon'; WHERE name LIKE 'yua%'; WHERE name REGEXP 'on$';
八.多表查询
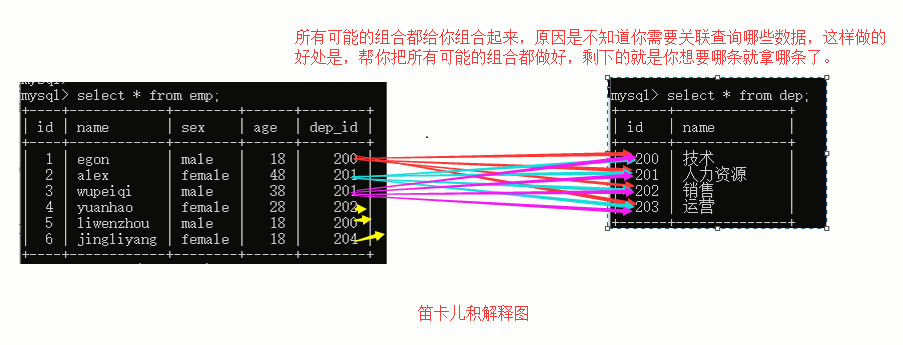
1.交叉连接,生成笛卡尔积。
select * from a1,b1;
笛卡尔积现象解释图:
2.inner内连接
inner内连接只连接匹配的行,和普通的select * from 表1,表2 where 条件效果相同,但是代码的可读性更高。
inner内连接语法:
第一步:连表 select * from dep inner join emp on dep.id=emp.dep_id; 第二步: 过滤 select * from dep inner join emp on dep.id=emp.dep_id where dep.name='技术'; 第三步:找对应字段数据 select emp.name from dep inner join emp on dep.id=emp.dep_id where dep.name='技术';
3.左连接,右连接
left join左连接以左边的表为主表,会显示左表的所有数据,如果右表的数据更多,会将多余的不匹配的删除;如果左表数据更多,右表没办法匹配的,会使用null补全。right join右连接刚好相反。
#以左表为准,即找出所有员工信息,当然包括没有部门的员工 #本质就是:在内连接的基础上增加左边有右边没有的结果 #注意语法: mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id; +----+------------+--------------+ | id | name | depart_name | +----+------------+--------------+ | 1 | egon | 技术 | | 5 | liwenzhou | 技术 | | 2 | alex | 人力资源 | | 3 | wupeiqi | 人力资源 | | 4 | yuanhao | 销售 | | 6 | jingliyang | NULL | +----+------------+--------------+
#以右表为准,即找出所有部门信息,包括没有员工的部门 #本质就是:在内连接的基础上增加右边有左边没有的结果 mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id; +------+-----------+--------------+ | id | name | depart_name | +------+-----------+--------------+ | 1 | egon | 技术 | | 2 | alex | 人力资源 | | 3 | wupeiqi | 人力资源 | | 4 | yuanhao | 销售 | | 5 | liwenzhou | 技术 | | NULL | NULL | 运营 | +------+-----------+--------------+
4.全外连接,显示左右两表的全部记录
全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果 #注意:mysql不支持全外连接 full JOIN #强调:mysql可以使用此种方式间接实现全外连接 select * from employee left join department on employee.dep_id = department.id union select * from employee right join department on employee.dep_id = department.id ; #查看结果 +------+------------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +------+------------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 5 | liwenzhou | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 6 | jingliyang | female | 18 | 204 | NULL | NULL | | NULL | NULL | NULL | NULL | NULL | 203 | 运营 | +------+------------+--------+------+--------+------+--------------+ #注意 union与union all的区别:union会去掉相同的纪录,因为union all是left join 和right join合并,所以有重复的记录,通过union就将重复的记录去重了。
5.子链接
#括号中是一个结果集,如果是一个结果,判断条件可以使用'=',如果是多个结果,需要使用'in'。 select * from td1 where x in (select * from td1); #如果括号后边加上as 表名,是创建一个新表
九.pymysql
1.代码操作
pymysql是python中提供的一种对于mysql数据库的操作接口。
Cursor类的源码(cursor不用自己创建,使用connections.Connection.cursor()即可,cursor是用来操作数据库中的类):
This is the object you use to interact with the database.
Do not create an instance of a Cursor yourself. Call
connections.Connection.cursor().
See `Cursor <https://www.python.org/dev/peps/pep-0249/#cursor-objects>`_ in
the specification.
"""
import pymysql #创建连接(6个条件) conn = pymysql.connect( host="localhost", user="root", password="root", port=3306, database="db2", charset="utf8" ) #创建连接,相当于在cmd下输入mysql -u root -p -h ...... cursor = conn.cursor(pymysql.cursors.DictCursor) #cursor为游标,将结果设置为字典形式 sql = cursor.execute("select * from class;") #execute执行sql语句 print(sql) #打印查询数据得到的行数 print(cursor.fetchone()) #得到一个结果,游标cursor向下移动一行 #print(cursor.fetchmany(3)) #查询指定个数的数据 #print(cursor.fetchall()) #查询所有数据 #cursor.scroll(2,"relative") #cursor相对于当前位置向下移动2个位置,超出范围报错 #cursor.scroll(2,"absolute") #cursor从开始位置向下移动2个位置,查第3个数据超出范围报错 conn.commit() #数据增删改需要用到,不然无法刷新到数据库 cursor.close() #关闭游标 conn.close() #关闭连接
2.数据库连接池
参考:1.https://www.cnblogs.com/apollo1616/p/10270123.html
2.https://blog.csdn.net/weixin_40976261/article/details/89057633
3.https://www.cnblogs.com/believepd/p/10344351.html
当使用pymsql连接数据库时,为解决每次执行sql语句都连接数据库,引入了数据库连接池。
数据库连接池的优点:
在程序创建连接的时候,可以从一个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度。 关闭连接的时候,把连接放回连接池,而不是真正的关闭,所以可以减少频繁的打开和关闭连接。
模块:DBUtils
DBUtils是python的一个用于实现数据库连接池的模块
此连接池有两种连接模式:
PersitentDB:提供线程专用的数据库连接,并自动管理连接
PooledDB:提供线程之间可共享的数据库连接,并自动管理连接
import pymysql from DBUtils.PooledDB import PooledDB #配置 POOL = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的链接,0表示不创建 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 ping=0, # ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always host='127.0.0.1', port=3306, user='root', password='222', database='cmdb', charset='utf8' ) #应用 def get_userinfo(): conn = POOL.connection() cursor = conn.cursor(pymysql.cursors.DictCursor) cursor.execute("select * from userinfo;") result = cursor.fetchall() cursor.close() return result
import pymysql from DBUtils.PooledDB import PooledDB class SqlHelper(object): def __init__(self): self.pool = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的链接,0表示不创建 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 ping=0, # ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always host='127.0.0.1', port=3306, user='root', password='222', database='cmdb', charset='utf8' ) def open(self): conn = self.pool.connection() #翻译过来就是池里的连接,从池里取一个连接 cursor = conn.cursor() return conn,cursor def close(self,cursor,conn): cursor.close() conn.close() def fetchall(self,sql, *args): """ 获取所有数据 """ conn,cursor = self.open() cursor.execute(sql, args) result = cursor.fetchall() self.close(conn,cursor) return result def fetchone(self,sql, *args): """ 获取所有数据 """ conn, cursor = self.open() cursor.execute(sql, args) result = cursor.fetchone() self.close(conn, cursor) return result db = SqlHelper() PooledDB模式
判断数据库是否正在连接
try: #conn,cursor = PooledDB(user="xx",password="xx").connection() conn.ping() #此处只是检查是否连接成功 except: 重连代码...
3.sql注入
首先我们要知道在mysql中有两种sql注入的问题
1.--空格 会注释掉sql后边的语句
2.or条件前面的一旦满足,后面的无用
解决方法:将sql语句写入:cursor.execute(sql,[username,password])
import pymysql conn = pymysql.connect( host='127.0.0.1', port=3306, user='root', password='666', database='day43', charset='utf8', ) while 1: username = input('请输入用户名:') password = input('请输入密码:') cursor = conn.cursor(pymysql.cursors.DictCursor) # sql = "select * from userinfo where username='duijie '-- ' and password='%s';" \ # % (username, password) #知道用户名不知道密码,也可登录网站 # sql = "select * from userinfo where username='asdfasdf' or 1=1 -- ' and password='%s';" \ # % (username, password) #不知道用户名也不知道密码,登录网站 # pymysql解决sql注入问题 sql = "select * from userinfo where username=%s and password=%s;" ret = cursor.execute(sql,[username,password]) if ret: print('登录成功') else: print('账号或者密码错误,请重新输入!!!') # 增删改都必须进行提交操作(commit) conn.commit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号