CNN笔记
卷积神经网络
设置一个33或者55的卷积核进行filter,
https://gaowenxin95.github.io/DL/deep_learn.html#cnn-1
这个比较简单,可以看看知乎大神的博客比较通俗易懂~
实现起来也比较简单,可以使用tf/keras的squence的方法~
图片的像素
人眼看到的图片,计算机读取的图片就是一堆的数字。一个图片就是一个三维数组(a,b,c)a,b分别代表图像的高度和宽度表示的像素数,c表示图片的颜色像素数
imread()
读取图片(的像素)
# Import matplotlib
import matplotlib.pyplot as plt
# Load the image
data = plt.imread('bricks.png')
# Display the image
plt.imshow(data)
plt.show()

Convolutions
卷积操作
定义一个kernel,不断地在图的窗口滑动,就是相乘再相加,也就是把33的一个窗口变为一个像素(假如卷积核是33)

array = np.array([1, 0, 1, 0, 1, 0, 1, 0, 1, 0])
kernel = np.array([1, -1, 0])
conv = np.array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
# Output array
for ii in range(8):
conv[ii] = (kernel * array[ii:ii+3]).sum()
# Print conv
print(conv)
<script.py> output:
[ 1 -1 1 -1 1 -1 1 -1 0 0]
kernel = np.array([[0, 1, 0], [1, 1, 1], [0, 1, 0]])
result = np.zeros(im.shape)
# Output array
for ii in range(im.shape[0] - 3):
for jj in range(im.shape[1] - 3):
result[ii, jj] = (im[ii:ii+3, jj:jj+3] * kernel).sum()
# Print result
print(result)
<script.py> output:
[[2.68104586 2.95947725 2.84313735 ... 0. 0. 0. ]
[3.01830077 3.07058835 3.05098051 ... 0. 0. 0. ]
[2.95163405 3.09934652 3.20261449 ... 0. 0. 0. ]
...
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]]
conv2D
keras中的 2维卷积层
卷积层对于内核中的每个像素素只有一个群众
Flatten()
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
```r
# Import the necessary components from Keras
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten
# Initialize the model object
model = Sequential()
# Add a convolutional layer
model.add(Conv2D(10, kernel_size=3, activation='relu',
input_shape=(img_rows, img_cols, 1)))
# Flatten the output of the convolutional layer
model.add(Flatten())
# Add an output layer for the 3 categories
model.add(Dense(3, activation='softmax'))
# Compile the model
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Fit the model on a training set
model.fit(train_data, train_labels,
validation_split=0.2,
epochs=3, batch_size=10)
# Evaluate the model on separate test data
model.evaluate(test_data, test_labels, batch_size=10)
Tweaking your convolutions
调整卷积
卷积运算,两个输入张量(输入数据和卷积核)进行卷积,输出代表来自每个输入的信息张量。tf.keras.conv2d完成卷积运算。卷积核(kernel),权值、滤波器、卷积矩阵或模版,filter。权值训练习得。卷积核(filter参数)权值数量决定需要学习卷积核数量。通道,计算机器视觉,描述输出向量。RGB图像,3个代表秩1张量[red,green,blue]通道。输出与input_batch同秩张量,与卷积核维数相同。两个张量卷积生成特征图(feature map)。特征图为输出添加新层代表张量卷积。访问输入批数据和特征图元素用相同索引,可了解输入与kernel卷积运算值变化。层,输出新维度。
计算机视觉卷积价值,修改卷积核strides(跨度)参数实现输入降维。strides参数使卷积核无需遍历每个输入元素,跳过部分图像像素。kernel在input_batch滑动,跨过部分元素,每次移动以input_batch一个元素为中心。位置重叠值相乘,乘积相加,得卷积结果。逐点相乘,整合两个输入。设置跨度,调整输入张量维数。降维减少运算量,避免重叠感受域。strides参数格式与输入向量相同(image_batch_size_stride、image_height_stride、image_width_stride、image_channels_stride)。
边界填充,卷积核与图像尺寸不匹配,填充图像缺失区域。TensorFlow用0填充。padding参数控制conv2d零填充数或错误状态。SAME:卷积输出输入尺寸相同,不考虑滤波器尺寸,缺失像素填充0,卷积核扫像素数大于图像实际像素数。VALID:考虑滤波器尺寸。尽量不越过图像边界,也可能边界被填充。
输入输出大小相同的华,可以设置paddle参数
# Initialize the model
model = Sequential()
# Add the convolutional layer
model.add(Conv2D(10, kernel_size=3, activation='relu',
input_shape=(img_rows, img_cols, 1),
padding='same'))
# Feed into output layer
model.add(Flatten())
model.add(Dense(3, activation='softmax'))
设置卷积的步长
# Initialize the model
model = Sequential()
# Add a convolutional layer
model.add(Conv2D(10, kernel_size=3, activation='relu',
input_shape=(img_rows, img_cols, 1),
strides=2))
# Feed into output layer
model.add(Flatten())
model.add(Dense(3, activation='softmax'))
data_format修改数据格式。NHWC指定输入输出数据格式,[batch_size(批数据张量数)、in_height(批数据张量高度)、in_width(批数据张量宽度)、in_channels(批数据张量通道数)]。NCHW指定输入输出数据格式,[batch_size、in_channels、in_height、in_width]。
TensorFlow滤波器参数指定输入卷积运算卷积核。滤波器使用特定模式突出图像中感兴趣特征。图像与边缘检测卷积核的卷积输出是所有检测边缘区域。tf.minimum和tf.nn.relu使卷积值保持在RGB颜色值合法范围[0,255]内。卷积核初值随机设定,训练迭代,值由CNN学习层自动调整,训练一迭代,接收图像,与卷积核卷积,预测结果与图像真实标签是否一致,调整卷积核。
keras.layers.convolutional.Conv2D(
filters, #卷积核的数目(即输出的维度)
kernel_size,#整数或由单个整数构成的list/tuple,卷积核的空域或时域窗长度
strides=1, #整数或由单个整数构成的list/tuple,为卷积的步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容
padding='valid', #补0策略,为“valid”, “same”
“valid”这是说只从边界开始卷积,不进行补0。
“same”对边界也进行补0,但是保证输入维度与输出维度相同。
dilation_rate=1, #整数或由单个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rate均与任何不为1的strides均不兼容。
activation=None, #激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
use_bias=True, #布尔值,是否使用偏置项
kernel_initializer='glorot_uniform', #权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。
bias_initializer='zeros', #权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。
kernel_regularizer=None, #施加在权重上的正则项
bias_regularizer=None, #施加在偏置向量上的正则项
activity_regularizer=None, #施加在输出上的正则项
kernel_constraint=None, #施加在权重上的约束项
bias_constraint=None#施加在偏置上的约束项
)
计算输出大小

设置膨胀积
规模问题
Going deeper
更深
特征是一层一层提取的
pooling层
Poolig层对Filter层的特征进行降维操作,形成最终的特征。
一般在Pooling层后连接全连接层神经网络,形成最后的分类结果。
Max Pooling的含义是对某个Filter抽取到若干特征值,只取得其中最大的那个Pooling层作为保留值,其他特征值全部抛弃,值最大代表只保留这些特征中最强的,抛弃其他弱的此类特征。
好处有以下几点
保证特征的位置与旋转不变性。对于图像处理这种特性是很好的,但是对于NLP来说特征出现的位置是很重要的。比如主语一般出现在句子头等等
减少模型参数数量,减少过拟合问题。2D或1D的数组转化为单一数值,对于后续的convolution层或者全连接隐层来说,减少了单个Filter参数或隐层神经元个数
可以把变长的输入x整理成固定长度的输入。CNN往往最后连接全连接层,神经元个数需要固定好,但是cnn输入x长度不确定,通过pooling操作,每个filter固定取一个值。有多少个Filter,Pooling就有多少个神经元,这样就可以把全连接层神经元固定住。
# Add a convolutional layer
model.add(Conv2D(15, kernel_size=2, activation='relu',
input_shape=(img_rows, img_cols, 1)))
# Add a pooling operation
model.add(MaxPool2D(2))
# Add another convolutional layer
model.add(Conv2D(5, kernel_size=2, activation='relu'))
# Flatten and feed to output layer
model.add(Flatten())
model.add(Dense(3, activation='softmax'))
model.summary()
过拟合
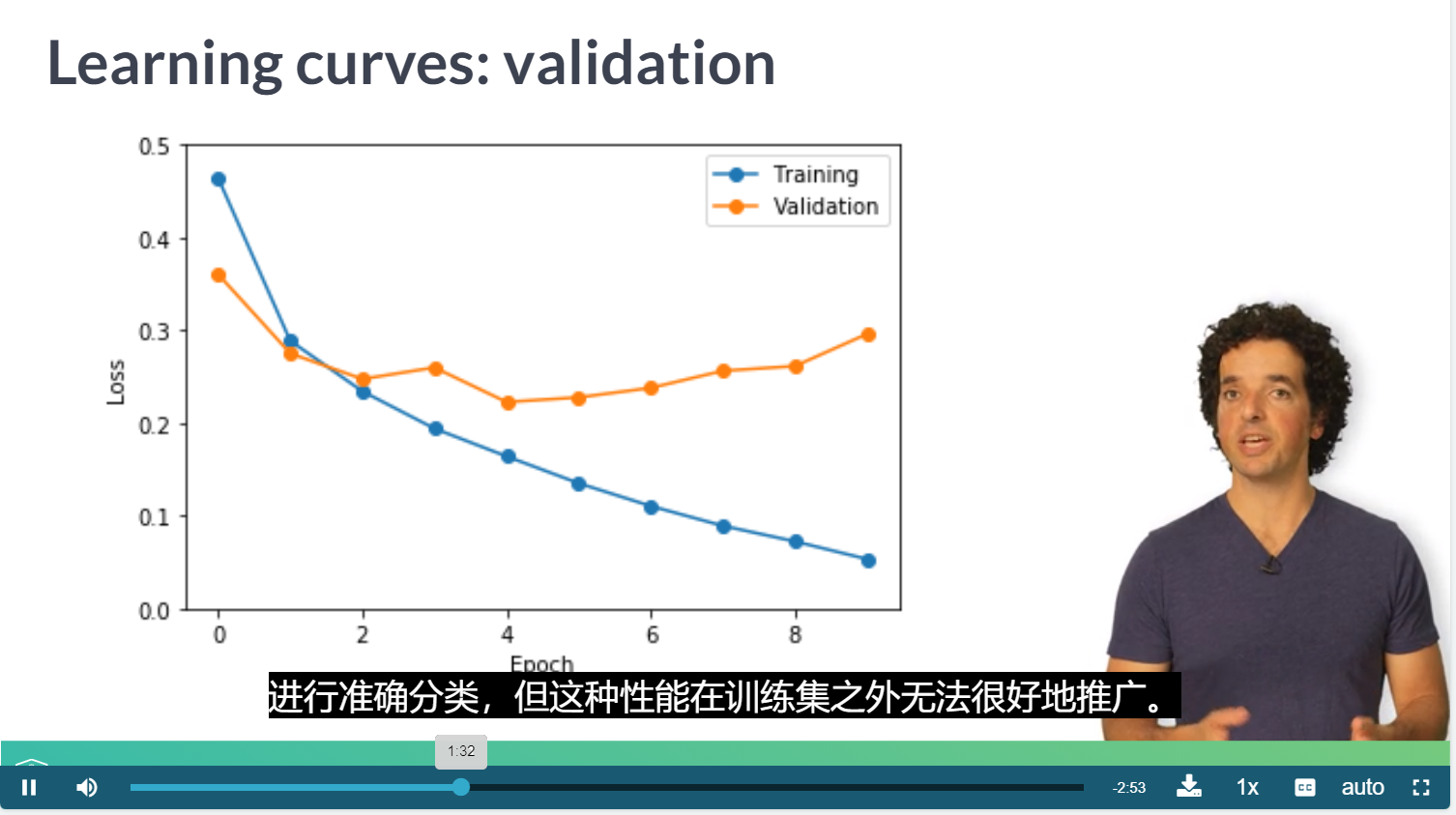
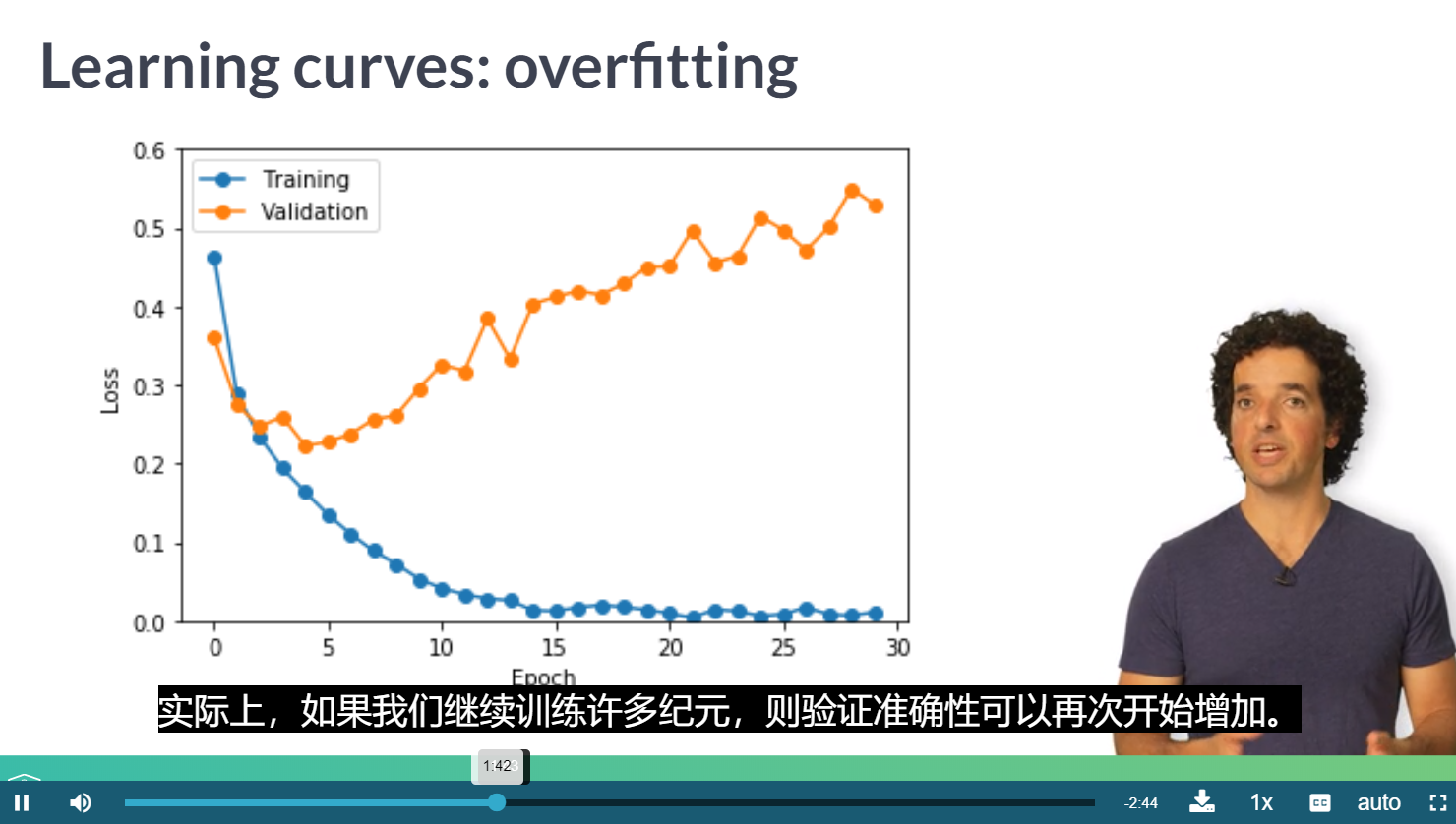
可以考虑使用回调函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号